

「社内に点在する膨大な情報から、必要なものを瞬時に見つけ出したい」
「AIチャットボットを導入したが、的外れな回答ばかりで困っている」——。多くの企業が、情報活用の高度化という壁に直面しています。この課題を解決する鍵として、大規模言語モデル(LLM)を活用した「LLM検索」が今、大きな注目を集めています。
LLM検索は、従来のキーワード検索とは異なり、AIが質問の意図や文脈を深く理解して、対話形式で最適な答えを生成する次世代の検索技術です。この記事では、LLM検索の根幹をなす「RAG」という技術の仕組みから、具体的なビジネス活用事例、システム構築のステップ、そして最新の関連ツールまで、専門家の視点から徹底的に解説します。
最後まで読めば、自社でLLM検索を導入し、情報活用のレベルを飛躍させるための具体的な道筋が見えるはずです。AIの力を最大限に引き出す方法を、ここで掴んでください。
AI導入の具体的な進め方や、業務に合わせたカスタマイズでお悩みの場合は、AX CAMPが提供する「AI導入支援サービス」の資料もぜひご活用ください。貴社の状況に合わせた最適な活用法をご提案します。

法人向けAI研修
AX CAMP 無料資料
LLM検索とは?従来の検索との違い

結論として、LLM検索とは大規模言語モデル(LLM)の高度な自然言語理解能力を活用し、ユーザーの質問に対して対話形式で直接的な回答を生成する検索手法です。従来の検索エンジンがキーワードに一致するWebページのリストを返すのに対し、LLM検索は情報そのものを要約・整理して提示する点が大きく異なります。これにより、ユーザーは複数のページを閲覧する手間なく、迅速に求める答えを得られます。
この新しい検索体験は、単なる情報検索の効率化に留まりません。社内ナレッジの活用や顧客対応の自動化など、ビジネスの様々な領域で革新をもたらす可能性を秘めています。次のセクションでは、この強力な技術が抱える課題から見ていきましょう。
LLMが抱える2つの課題(ハルシネーションと知識のカットオフ)
LLMは非常に強力なツールですが、ビジネスで活用するには無視できない2つの大きな課題が存在します。それが「ハルシネーション」と「知識のカットオフ」です。
ハルシネーションとは、LLMが事実に基づかない、もっともらしい嘘の情報を生成してしまう現象を指します。これは、LLMが学習データに存在しない情報について質問された際、確率的にそれらしい単語を繋ぎ合わせて回答を作成しようとするために発生します。ビジネスの意思決定に誤った情報が用いられれば、深刻な損害につながる危険性があります。
もう一方の知識のカットオフは、LLMが持つ知識が学習データを収集した特定の時点(カットオフ日)で止まっているという問題です。そのため、カットオフ日以降の出来事や最新の製品情報、法改正などに関する質問には答えられません。これらの根源的な課題を解決するために、後述するRAGという技術が極めて重要になります。
従来のキーワード検索との根本的な違い
LLM検索と従来のキーワード検索は、その仕組みと提供価値において根本的に異なります。最大の違いは、ユーザーの「意図」を理解できるかどうかにあります。
キーワード検索は、入力された単語(キーワード)が含まれる文書を機械的に探し出し、関連度が高い順にリストアップする仕組みです。一方、LLM検索は入力された文章の文脈や背景を読み取り、ユーザーが本当に知りたいことは何かという「検索意図」を深く理解しようとします。その上で、必要な情報を抽出し、自然な文章で回答を生成します。
この違いを以下の表にまとめました。
| 比較項目 | LLM検索 | 従来のキーワード検索 |
|---|---|---|
| 処理の仕組み | 意味・文脈を理解して回答を生成 | キーワードとの一致度で文書を順位付け |
| 回答形式 | 対話形式の文章、要約 | Webページのリンク一覧 |
| 対話能力 | 追加の質問や深掘りが可能 | 一問一答で完結 |
| 得意なこと | 複雑な質問、情報要約、アイデア出し | 特定の単語を含む文書の網羅的な発見 |
このように、LLM検索は単なる「検索」から「対話による問題解決」へと、情報アクセスのあり方を大きく変える技術と言えるでしょう。

LLM検索を支える中核技術「RAG」とは
LLM検索の精度と信頼性を飛躍的に向上させる技術がRAG(Retrieval-Augmented Generation、検索拡張生成)です。RAGは、LLMが回答を生成する際に、事前に信頼できる外部の知識源(データベースや社内文書など)を参照する仕組みを指します。これにより、ハルシネーションや知識のカットオフといったリスクを大幅に軽減できます。(出典:RAG(検索拡張生成)とは?仕組みやメリット、活用事例を解説)
料理に例えるなら、LLM単体での回答が「記憶だけを頼りに作る料理」だとすれば、RAGを活用した回答は「最新のレシピ本を参照しながら作る料理」です。レシピ本(外部知識)を参照することで、より正確で質の高い料理(回答)を生み出せるのです。
RAG(検索拡張生成)の基本概念
RAGの基本的な概念は、「検索(Retrieval)」と「生成(Generation)」という2つのプロセスを組み合わせる点にあります。ユーザーから質問が入力されると、まずその質問に関連する情報を外部のナレッジベースから検索します。そして、検索して得られた情報と元の質問をLLMに渡し、その情報に基づいて回答を生成させるのです。(出典:RAG(Retrieval-Augmented Generation))
このアーキテクチャにより、LLMは自身の内部知識だけに頼るのではなく、常に最新かつ正確な外部データを根拠として回答を生成できるようになります。結果として、出力される情報の信頼性が大幅に向上し、どの文書を参照したのかという出典も明示できるため、ユーザーは回答の正当性を検証できます。
ファインチューニングとの違いと使い分け
LLMの性能を特定業務に合わせて強化するもう一つの手法に「ファインチューニング」があります。RAGとファインチューニングは目的が似ていますが、そのアプローチと得意な領域が異なります。
RAGは、外部データソースを更新するだけでLLMに新しい知識をリアルタイムで提供できる点が最大の特長です。一方、ファインチューニングは、特定のドメインのデータセットを使ってLLM自体を再学習させ、モデルの振る舞いや文体、特定の専門知識を深く染み込ませる手法です。例えば、医療分野の対話スタイルや法律分野の専門用語のニュアンスなどを学習させる場合に有効です。(出典:Vertex AI Searchとは?料金や使い方、生成AIアプリの構築手順を解説)
以下の表で両者の違いと使い分けを整理します。
| 比較項目 | RAG(検索拡張生成) | ファインチューニング |
|---|---|---|
| 目的 | 最新・正確な情報に基づいた回答生成 | モデルの振る舞い・文体・スタイルの調整 |
| 仕組み | 外部DBを検索し、その情報を基に回答 | 追加データでモデル自体を再学習 |
| 知識の更新 | 容易(DBを更新するだけ) | 困難(再学習が必要で高コスト) |
| 導入コスト | 比較的低い | 高い(大量のデータと計算資源が必要) |
| 適した用途 | 社内規定検索、FAQ、最新ニュースの要約 | 特定のペルソナを持つチャットボット、文体模倣 |
ビジネスシーンでは、これら2つの技術を組み合わせることも珍しくありません。まずファインチューニングで業界特有の対話スタイルを学習させ、その上でRAGを使って最新の社内情報を参照させるといった、ハイブリッドなアプローチが非常に効果的です。
https://media.a-x.inc/ai-rag
https://media.a-x.inc/ai-finetune
RAG(検索拡張生成)の仕組みを3ステップで解説
RAGが外部の知識を活用して高精度な回答を生成する仕組みは、大きく分けて「データ準備(Indexing)」「検索(Retrieval)」「生成(Generation)」の3つのステップで構成されています。この一連の流れを理解することで、LLM検索システムを自社で構築・運用する際の解像度が格段に上がります。
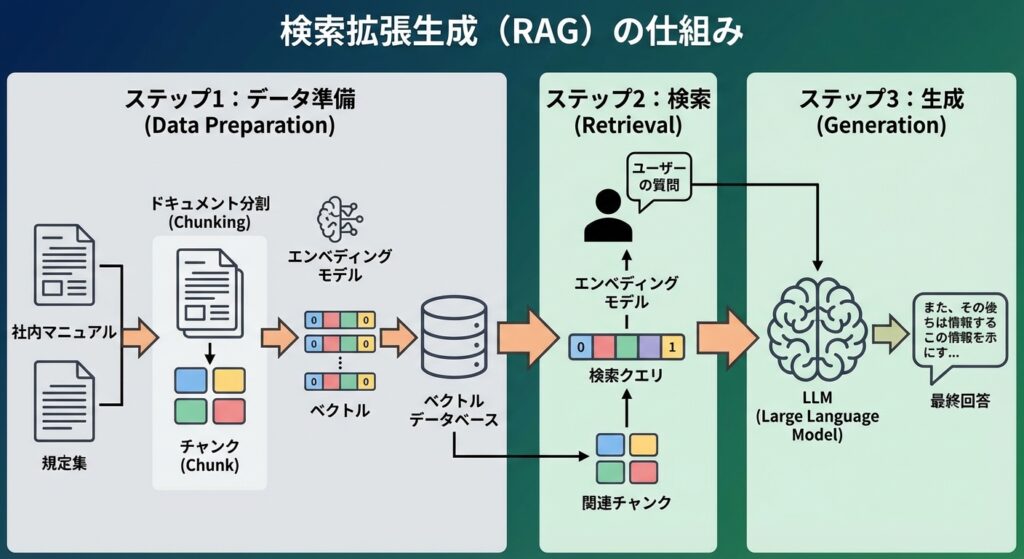
ここでは、それぞれのステップで何が行われているのかを具体的に見ていきましょう。
- ステップ1:データ準備(Indexing)
まず、参照させたい情報源(社内マニュアル、規定集など)をLLMが利用しやすい形に加工・整理します。具体的には、長文のドキュメントを「チャンク」と呼ばれる意味のある小さな塊に分割します。次に、「エンベディングモデル」を用いて各チャンクをベクトル(数値の配列)に変換し、「ベクトルデータベース」に格納します。このベクトル化により、単語の一致ではなく、意味の近さで情報を検索できるようになります。(出典:ベクトルデータベースとは?LLMの外部記憶として活用される仕組みを解説) - ステップ2:検索(Retrieval)
ユーザーから質問が入力されると、ステップ1と同様に質問文もベクトルに変換されます。そして、その質問ベクトルと意味的に最も近いチャンクのベクトルを、ベクトルデータベースの中から探し出します。これにより、キーワードが完全に一致していなくても、文脈的に関連性の高い情報を効率的に見つけ出すことができます。 - ステップ3:生成(Generation)
最後に、ステップ2で検索された関連性の高いチャンクの情報と、ユーザーからの元の質問を組み合わせ、一つのプロンプト(指示文)としてLLMに渡します。LLMは与えられた情報を「根拠」として、その内容に忠実な回答を生成します。これにより、ハルシネーションを抑制し、出典の明らかな信頼性の高い回答が実現します。


LLM検索(RAG活用)の主なメリット
LLM検索にRAGを活用することで、企業は単なる情報検索の効率化を超えた多くのメリットを享受できます。主なメリットは「回答精度の向上」「最新情報への対応力」「回答根拠の透明性」という3点です。これらは、生成AIをビジネスの現場で本格的に活用する上で不可欠な要素となります。
それぞれのメリットについて詳しく見ていきましょう。
回答精度の向上(ハルシネーション抑制)
RAGの最大のメリットは、ハルシネーション(AIが誤情報を生成する現象)を大幅に抑制できることです。LLMが外部の信頼できるデータソースを根拠として回答を生成するため、事実に基づかない情報を答えてしまうリスクを最小限に抑えられます。これは、正確性が求められる業務において極めて重要です。(出典:RAG(Retrieval-Augmented Generation))
最新情報へのリアルタイム対応
また、LLMの知識は学習データが作成された時点で固定されてしまいますが、RAGを使えばこの問題を解決できます。外部のデータベースを最新の状態に保つだけで、LLM自体を再学習させることなく、常にリアルタイムの情報に基づいた回答を提供できます。これにより、日々更新される社内規定や市場動向にも迅速に対応可能です。(出典:AWS CDK を使って Amazon Bedrock Knowledge Bases のためのドキュメント管理・更新基盤を構築する)
出典明示による信頼性・透明性の確保
さらに、RAGはどの文書のどの部分を参照して回答を生成したのか、その出典を明示することができます。これにより、ユーザーは回答の根拠を自ら確認でき、情報の信頼性を検証できます。この透明性は、特に規制の厳しい業界や、監査対応が必要な業務において大きな価値を持ちます。

LLM検索のビジネス活用事例
LLM検索(RAG活用)は、既に多くの企業で導入が進んでおり、具体的な業務効率化やサービス品質の向上に繋がっています。特に効果を発揮しているのが、「社内ナレッジ検索」と「顧客対応の自動化」の2つの領域です。ここでは、具体的な事例を交えながら、その活用方法を紹介します。
1. 高度な社内ナレッジ検索システム
多くの企業では、マニュアル、社内規定、過去のプロジェクト資料などが複数のSaaSに散在し、「どこに何の情報があるか分からない」という課題を抱えています。LLM検索を導入することで、これらの社内文書を横断的に検索し、自然言語での質問に対してピンポイントで回答を得られるようになります。
例えば、「最新の経費精算ルールについて教えて」と質問するだけで、関連する規定文書を探し出し、要点をまとめて提示してくれます。これにより、従業員が情報を探す時間は大幅に削減され、本来の業務に集中できる環境が整います。
実際に、美容健康食品の製造販売を行うエムスタイルジャパン様では、コールセンターでの履歴確認業務などにRAGを活用したシステムを導入。従来は月16時間かかっていた確認業務がほぼ0時間になるなど、全社で月100時間以上の業務削減を達成したと報告されています。(出典:月100時間以上の”ムダ業務”をカット!エムスタイルジャパン社が築いた「AIは当たり前文化」の軌跡)
2. 顧客対応を自動化する次世代チャットボット
従来のシナリオベースのチャットボットは、想定された質問にしか答えられず、少し複雑な問い合わせには有人対応が必要でした。LLMとRAGを組み合わせた次世代チャットボットは、FAQや製品マニュアルなどを知識源として、より柔軟で人間らしい対話が可能です。
ユーザーからの曖昧な質問の意図も汲み取り、関連情報を基に適切な回答を自動生成するため、24時間365日、高品質な顧客対応を実現できます。これにより、カスタマーサポート部門の負荷を軽減し、顧客満足度の向上に大きく貢献します。
SNS広告・ショート動画制作を手掛けるWISDOM合同会社様では、採用活動における問い合わせ対応や候補者管理にAIを導入。これにより、採用担当者2名分の業務負荷をAIで代替することに成功し、コア業務である候補者とのコミュニケーションに注力できる環境を構築しました。(出典:AX CAMP受講企業の成果事例)
また、リスティング広告運用企業のグラシズ様は、LP制作のライティング業務にAIを活用。従来は外注で1本あたり10万円の費用と3営業日を要していましたが、AIの内製化支援により費用0円、制作時間2時間へと劇的に改善し、制作時間を93%削減することに成功しました。(出典:AX CAMP受講企業の成果事例)



LLM検索システムの基本的な構築ステップ
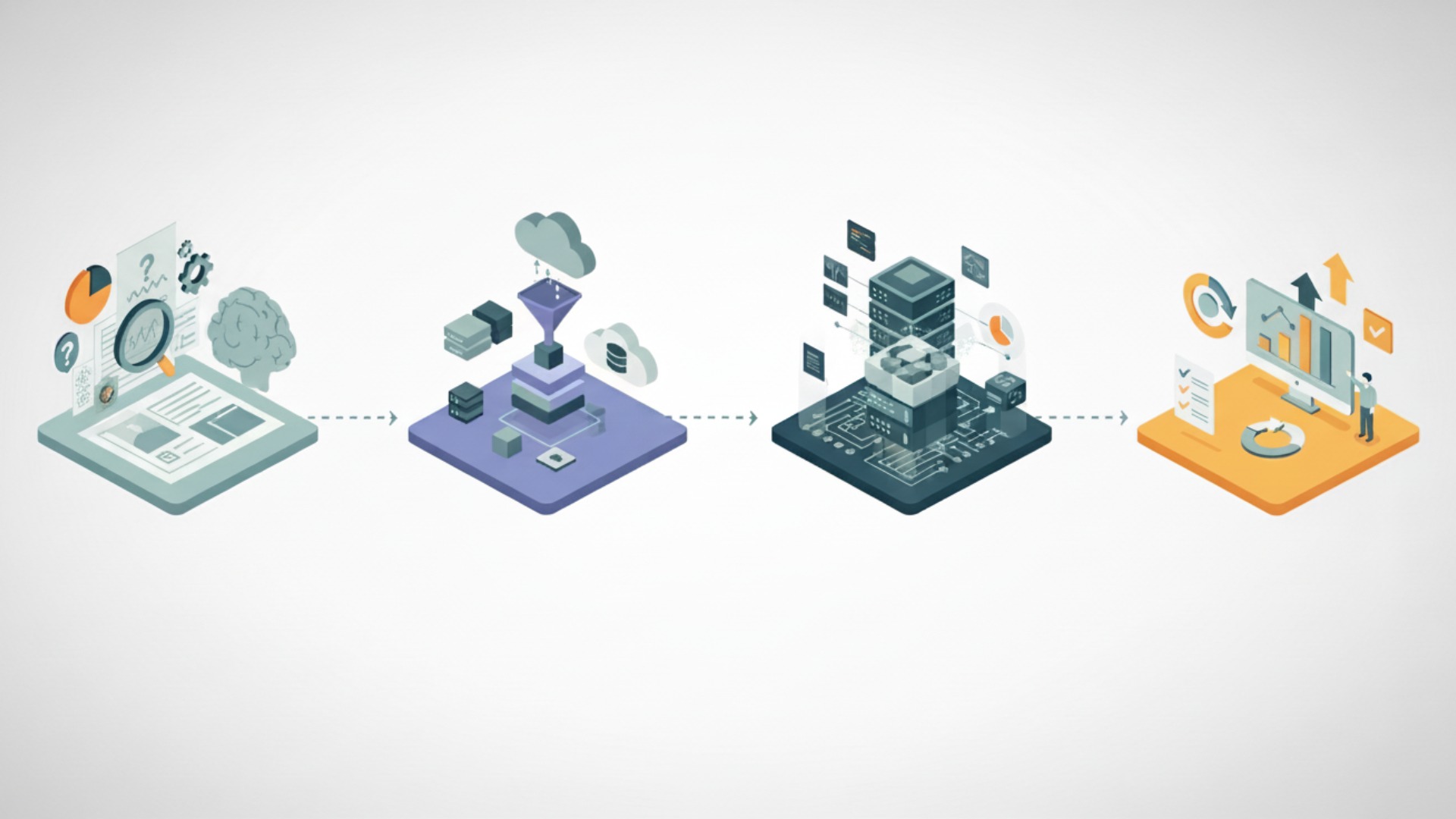
LLM検索システムを自社に導入するプロセスは、大きく分けて4つのステップで進めるのが一般的です。「目的・要件定義」「データ準備」「システム開発」「評価・改善」という流れを理解し、計画的に進めることがプロジェクト成功の鍵となります。各ステップで検討すべきポイントを解説します。
- 目的・要件定義
最初に、「誰が」「何のために」このシステムを使うのかを明確にします。例えば、「営業担当者が提案書作成時に過去の類似案件を迅速に探せるようにする」など、具体的な利用シーンと解決したい課題を定義します。この段階で、対象とするデータ範囲や求める回答精度などの要件も固めます。 - データソースの準備と前処理
次に、RAGの知識源となる社内文書やデータを収集します。PDF、Word、Webページなど、様々な形式のデータを対象とすることが多いでしょう。収集したデータは、不要な情報を削除したり、テキスト形式に変換したりといった前処理を行い、品質を整えることが重要です。 - 技術スタックの選定と開発
目的とデータに合わせて、最適な技術要素(LLMモデル、ベクトルデータベースなど)を選定し、システムを構築します。クラウドサービス(AWS, Google Cloud, Azureなど)が提供する統合型サービスを利用するのか、オープンソースのツールを組み合わせて自社で構築するのかなど、開発方針を決定します。(出典:AWS CDK を使って Amazon Bedrock Knowledge Bases のためのドキュメント管理・更新基盤を構築する) - 評価と改善
システムをリリースしたら、実際の利用状況やユーザーからのフィードバックを基に、継続的に評価と改善を行います。回答の精度が低い質問を分析し、データの前処理方法を見直したり、検索の仕組みをチューニングしたりすることで、システムの価値をさらに高めていくことができます。
これらのステップは一度で終わるものではありません。4の評価・改善から1の要件定義にフィードバックするといったサイクルを回していくことが、現場で本当に使われるシステムを育てる上で不可欠です。


LLM検索の精度を高めるためのポイント
LLM検索システムを構築しても、その回答精度が低ければ業務で活用することはできません。精度を最大化するためには、特に「データの分割・変換方法」と「検索技術の組み合わせ」という2つの技術的なポイントが重要になります。これらを最適化することで、ユーザーの質問意図をより正確に捉え、的確な回答を導き出すことが可能になります。
チャンク分割とエンベディングモデルの最適化
RAGの精度は、データ準備段階の処理に大きく左右されます。特に重要なのが「チャンキング」と「エンベディングモデルの選定」です。
チャンキングとは、元の文書を意味のある塊(チャンク)に分割する処理のことです。チャンクのサイズが小さすぎると文脈が失われ、大きすぎると不要な情報が多くなりノイズの原因となります。文書の種類に応じて、最適なチャンクサイズや、チャンク同士を少し重ねる(オーバーラップ)設定を見つけることが精度向上の鍵です。(出典:Vertex AI Searchとは?料金や使い方、生成AIアプリの構築手順を解説)
エンベディングモデルは、チャンクをベクトルに変換する役割を担います。このモデルの性能が、意味の近さをどれだけ正確に捉えられるかを決定します。一般的な文書には汎用的なモデルで対応できますが、専門用語が多い技術文書などを扱う場合は、そのドメインに特化したエンベディングモデルを選ぶことで、検索精度を大幅に改善できます。
キーワード検索とベクトル検索のハイブリッド
RAGの中核をなすベクトル検索は「意味」の近さで検索できる非常に強力な手法ですが、万能ではありません。特定の製品型番や人名といった固有名詞など、キーワードが完全に一致する情報を探すのは苦手な場合があります。
この弱点を補うために有効なのが、従来のキーワード検索(BM25など)とベクトル検索を組み合わせた「ハイブリッド検索」です。まず両方の手法で検索を行い、それぞれの結果を統合して最適な情報を絞り込むことで、意味的な関連性とキーワードの正確性の両方を満たす、より精度の高い検索結果を得られます。このアプローチは、近年の高度な検索システムにおいて標準的な手法となりつつあります。
【2026年時点】LLM検索向けAPIサービス・ツール比較
LLM検索システムを構築するためのサービスやツールは、近年急速に多様化しています。自社の目的や技術力に応じて最適なものを選択することが重要です。ここでは、「検索特化型API」「クラウド統合型サービス」「ベクトルデータベース」「開発フレームワーク」の4つのカテゴリに分けて、主要なサービスを紹介します。
検索特化型APIサービス
自社で複雑なRAGの仕組みを構築することなく、APIを呼び出すだけで高度なLLM検索機能を利用できるサービスです。開発の手間を最小限に抑え、迅速にサービスを立ち上げたい場合に適しています。
- Perplexity API: 高度な対話型検索エンジンで知られるPerplexityが提供。Web上の最新情報をリアルタイムに反映した回答生成が得意。
- Brave Search API: プライバシー重視の検索エンジンBraveが提供。独自の検索インデックスを持ち、中立的な検索結果を返す点が特徴。
クラウド統合型サービス
大手クラウドプラットフォーム(AWS, Google Cloud, Azure)が提供する、LLM検索に必要な機能を統合したマネージドサービスです。自社のデータを安全なクラウド環境で扱いたい場合に最適です。
- Amazon Bedrock: AWSが提供。複数の高性能LLMモデルから選択でき、自社データを用いたRAGアプリケーションを容易に構築可能。
- Vertex AI Search (Google Cloud): Googleの強力な検索技術を基盤としたサービス。多様なデータソースに対応。(出典:Vertex AI Searchとは?料金や使い方、生成AIアプリの構築手順を解説)
- Azure AI Search: Microsoftが提供。ベクトル検索とキーワード検索のハイブリッド検索機能が強力で、Azure OpenAI Serviceとの連携もスムーズ。
主要なベクトルデータベース(Vector DB)
RAGシステムの「知識源」となるベクトルデータを格納・管理・検索するための専用データベースです。大規模なデータを扱い、高速な検索性能が求められる場合に不可欠となります。
| サービス名 | 特徴 | 適した用途 |
|---|---|---|
| Pinecone | フルマネージド型で導入が容易。高いパフォーマンスとスケーラビリティ。 | 本番環境での大規模アプリケーション |
| Weaviate | オープンソース。ハイブリッド検索やマルチモーダル検索に強い。 | 複雑な検索要件、テキスト以外のデータ活用 |
| Chroma | 軽量でローカル環境での開発が容易。Python中心の開発者に人気。 | プロトタイピング、小規模なアプリケーション |
| Qdrant | 高性能で低レイテンシ。高度なフィルタリング機能が特徴。 | リアルタイム性が求められるシステム |
開発を効率化するフレームワーク
LLMアプリケーション、特にRAGシステムの開発を効率化するためのオープンソースのライブラリです。データ連携からLLMとの対話まで、一連の処理をモジュール化して提供しており、開発工数を大幅に削減できます。
- LangChain: LLMアプリ開発のデファクトスタンダード。豊富なコンポーネントと柔軟な連携機能が特徴。
- LlamaIndex: RAGに特化したフレームワーク。データ取り込みからインデックス作成、検索の最適化まで、RAG構築に便利な機能が充実。
なお、基盤となるLLMモデルとしては、OpenAI社のGPT-5シリーズ、Google社のGemini 3シリーズ、Anthropic社のClaude 4.5シリーズなどが、2025年11月時点での主要な選択肢となります。各社が開発競争を繰り広げており、常に最新の動向を注視することが重要です。(出典:【2026年】生成AIのLLM(大規模言語モデル)を比較!おすすめは?)


LLM検索導入における注意点と対策

LLM検索は非常に強力な技術ですが、ビジネスに導入する際にはいくつかの注意点が存在します。特に「運用コスト」「セキュリティリスク」「継続的な精度管理」の3点は、事前に十分な検討と対策が必要です。これらの課題を軽視すると、予期せぬトラブルや期待した効果が得られない結果に繋がりかねません。
ここでは、それぞれの注意点と具体的な対策について解説します。
- 運用コストの管理
LLMのAPI利用料やベクトルデータベースの運用費など、LLM検索システムの運用には継続的なコストが発生します。対策としては、利用状況を常にモニタリングし、コストパフォーマンスに優れたLLMモデルを選択することや、質問の複雑さに応じてモデルを使い分けるといった工夫が有効です。(出典:生成AI・LLM導入の主なリスクと対策をわかりやすく解説) - セキュリティと情報漏洩リスク
社内の機密情報をRAGのデータソースとして扱う場合、情報漏洩対策は最重要課題です。対策としては、データを自社の閉じたネットワーク内で管理できるクラウドサービスやオンプレミス型のLLMを選択すること、そして従業員ごとのアクセス権限をデータソースに厳密に設定することが不可欠です。 - 継続的な精度管理
LLM検索システムは、一度構築して終わりではありません。対策としては、ユーザーからのフィードバック(回答が役に立ったかなど)を収集する仕組みを導入し、定期的に回答精度を評価することが重要です。評価結果に基づき、インデックスを更新したり、検索ロジックをチューニングしたりといった継続的なメンテナンスがシステムの価値を維持・向上させます。


LLM検索の今後の展望と未来

LLM検索技術は、今もなお急速なスピードで進化を続けています。今後の展望として特に注目されるのが、「マルチモーダル検索への進化」と「自律型AIエージェントとの連携強化」です。これらの進化は、私たちの情報との関わり方をさらに根底から変えていくことになるでしょう。
未来の検索技術がどのような姿になるのか、その可能性を探ります。
マルチモーダル検索への進化
これまでの検索はテキスト情報が中心でしたが、今後は画像、音声、動画といった多様な形式の情報を統合的に扱える「マルチモーダル検索」が主流になっていきます。最新のLLMは、既に高度なマルチモーダル能力を備え始めています。
例えば、スマートフォンのカメラで撮影した機械の部品について「この部品の仕様とメンテナンス方法は?」と質問するだけで、AIが画像を認識し、関連するマニュアルから最適な回答を生成することが可能になります。これにより、製造業の現場作業などが劇的に効率化されると期待されています。(出典:生成AIの未来とは?技術の進化とビジネスへの影響を専門家が解説)
自律型AIエージェントとの連携強化
LLM検索は、単に情報を見つけるだけでなく、その情報に基づいて次のアクションを自律的に実行する「AIエージェント」と強力に連携していきます。AIエージェントとは、与えられた目標を達成するために、自ら計画を立て、必要なツールを使いこなしながらタスクを遂行するAIのことです。
例えば、「来週の大阪出張の最適なプランを作成して」と指示するだけで、AIエージェントがLLM検索で最新の交通機関やホテルの空き状況を調べ、最適な旅程を提案した上で予約まで完了させる、といった未来が現実のものとなります。検索が思考や行動とシームレスに繋がり、人間の知的生産活動をより高度なレベルで支援するパートナーへと進化していくでしょう。

LLMや最先端AIのビジネス活用ならAX CAMPへ

LLM検索やRAGの可能性を感じつつも、「自社で導入するには何から手をつければ良いのか分からない」「専門的な知識を持つ人材が社内にいない」といった課題をお持ちではないでしょうか。最先端のAI技術をビジネスに実装するには、技術の理解だけでなく、業務プロセスへの深い洞察と戦略的な計画が不可欠です。
もし、AI活用を本格的に、かつ着実に推進したいとお考えなら、ぜひAX CAMPの法人向けAI研修・伴走支援サービスをご検討ください。AX CAMPは、単なるツールの使い方を教える研修ではありません。貴社の具体的な業務課題をヒアリングし、LLM検索システムの導入をはじめとする、成果に直結するAI活用法をオーダーメイドでご提案します。
経験豊富な専門家が、企画立案から開発、社内への定着まで一気通貫でサポートするため、AIプロジェクトの失敗リスクを最小限に抑えられます。「自社専用のナレッジ検索システムを構築したい」「顧客対応をAIで自動化し、コストを削減したい」といった具体的なご要望はもちろん、「まずは何ができるか知りたい」という段階でも構いません。貴社のAI活用の第一歩を、私たちと一緒に踏み出しませんか。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLM検索を理解し、次世代の情報活用を実現しよう
本記事では、大規模言語モデル(LLM)を活用した次世代の検索技術「LLM検索」について、その中核をなすRAGの仕組みから、ビジネスでの具体的な活用事例、導入のステップ、最新ツールまでを網羅的に解説しました。
最後に、この記事の重要なポイントをまとめます。
- LLM検索はAIが質問意図を理解し、対話形式で回答する技術
- RAGがLLMの弱点(ハルシネーション等)を補い、精度と信頼性を担保
- 社内ナレッジ検索や顧客対応自動化で大きな業務効率化を実現
- 導入成功には目的定義と継続的な精度管理が不可欠
- 今後はマルチモーダル化とAIエージェント連携が加速する
LLM検索は、もはや単なる未来の技術ではありません。情報活用のあり方を根本から変え、企業の競争力を左右する重要な経営基盤となりつつあります。この記事で得た知識を基に、ぜひ自社での活用を具体的に検討してみてください。
もし、LLM検索システムの導入や、その他AIを活用した業務効率化に関して、「専門家の具体的なアドバイスが欲しい」「自社のケースに最適な進め方を知りたい」とお考えでしたら、ぜひAX CAMPの無料相談をご活用ください。貴社の課題に合わせた最適なAI導入プランをご提案し、プロジェクトの成功を力強くサポートします。

法人向けAI研修
AX CAMP 無料資料