

「生成AIの回答が不正確で、業務に使うには不安がある」
「社内データのような専門的で最新の情報に基づいて回答を生成させたい」このようにお考えではないでしょうか。生成AIは便利な一方、学習データにない情報は回答できず、時にはもっともらしい嘘(ハルシネ-ション)をつく課題がありました。この課題を解決する技術が
「RAG(ラグ)」です。
RAG(Retrieval-Augmented Generation:検索拡張生成)は、生成AIに外部の知識データベースをリアルタイムで参照させることで、回答の正確性と信頼性を飛躍的に向上させる技術です。 これにより、常に最新かつ正確な情報に基づいた回答を生成できます。この記事では、RAGの基本的な仕組みから、ビジネスにおける具体的な活用事例、導入を成功させるためのポイントまでを網羅的に解説します。AI活用を一歩先に進めたい方は、ぜひご一読ください。
また、AIの導入や活用に関するお悩みは、当社AX CAMPが提供する資料で解決できるかもしれません。AI導入の計画から実行までをサポートする実践的なノウハウをまとめているので、ぜひ一度ご覧ください。
記事:【AI導入しないことが経営リスクになる時代】先行企業が手にした圧倒的な競争優位とは?
- RAG(検索拡張生成)とは?生成AIの新たな可能性
- なぜ今RAGが注目されるのか?従来の生成AIが抱える課題
- RAGの仕組みを3つのステップでわかりやすく解説
- RAGとファインチューニングの決定的な違い
- RAG導入による主要なメリット
- 知っておくべきRAGのデメリットと対策
- 【2026年版】RAGの主な活用事例
- RAG導入を成功させるための重要なポイント
- RAGシステムの基本的な構築方法
- RAGの精度を最大化する先進的テクニック
- 【2026年最新】おすすめのRAG関連ツール・サービス
- 生成AIとRAGの今後の展望と未来予測
- 生成AIの導入・活用ならAX CAMP(エーエックスキャンプ)
- まとめ:生成AIとRAGを理解し、ビジネス活用を次のレベルへ
RAG(検索拡張生成)とは?生成AIの新たな可能性

RAG(Retrieval-Augmented Generation:検索拡張生成)とは、大規模言語モデル(LLM)などの生成AIが、外部の信頼できる情報源からリアルタイムで情報を検索し、その内容を基に回答を生成する技術です。(出典:「RAG」とは何か?~生成AIの信頼性を向上させるための仕組みを解説)これにより、生成AI単体が持つ知識の限界を超え、より正確で最新の、そして根拠の明確な回答を生み出せるようになります。
従来の生成AIは、事前に学習した膨大なデータの中にある知識だけで回答を作成していました。これは例えるなら、教科書の内容をすべて暗記してテストに臨むようなものです。一方、RAGは教科書や参考書の持ち込みが許可されたテストに近く、質問を受けてから必要な情報を調べて回答を作成します。この仕組みにより、生成AIの大きな課題であったハルシネーション(もっともらしい嘘)を抑制する効果が期待できるのです。
基本的な定義と役割
RAGの役割は、生成AIの「脳」であるLLMに対して、回答の材料となる正確で新鮮な情報を「外部から供給する」ことです。LLMは非常に高度な言語能力を持っていますが、その知識は学習した時点のものであり、社内文書のような限定的な情報も持っていません。
そこでRAGは、ユーザーからの質問に関連する情報を、指定されたデータベース(社内規定、製品マニュアル、最新の市場データなど)から瞬時に探し出します。そして、見つけ出した情報(コンテキスト)を元の質問と一緒にLLMへ渡すことで、LLMがその情報に基づいて回答を生成できるように支援します。この一連の流れが、RAGの基本的な役割です。
LLMの知識をリアルタイムで拡張する技術
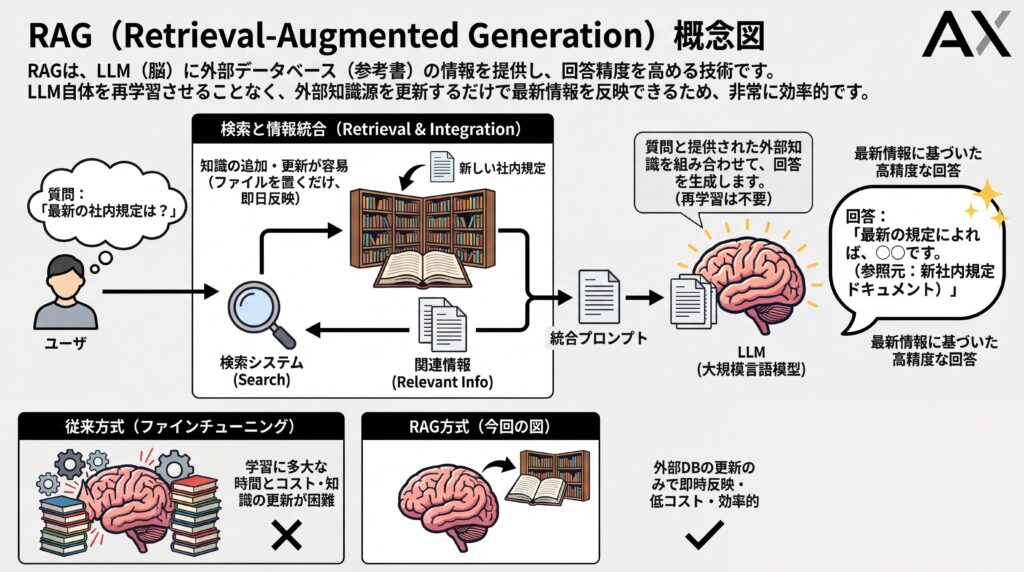
RAGは、LLMを再学習させることなく、その知識を動的に拡張できる点が画期的です。従来のLLMは、新しい情報を覚えさせるために「ファインチューニング」という追加学習が必要で、それには多くの時間とコストがかかりました。
しかしRAGは、知識源である外部データベースを更新するだけで、比較的短時間でLLMの回答に最新情報を反映させられます。例えば、新しい社内規定が追加された場合、そのファイルをデータベースに置くだけで、AIチャットボットは即日その規定に基づいた回答が可能です。(出典:ベクトル データベースとは)このように、RAGはLLMの知識を常に最新の状態に保つための、非常に効率的で強力な技術なのです。

なぜ今RAGが注目されるのか?従来の生成AIが抱える課題
RAGが急速に注目を集めている背景には、従来の生成AIが抱える3つの根深い課題があります。これらの課題は、生成AIをビジネスの現場で本格的に活用する上での大きな障壁となっていました。RAGは、これらの課題に対する直接的かつ効果的な解決策を提示します。
具体的には、平気で嘘をつく「ハルシネーション」、情報が古くなる「知識の陳腐化」、そして回答の根拠が分からない「ブラックボックス問題」です。これらの問題点を理解することで、RAGの真価が見えてきます。
ハルシネーション(もっともらしい嘘)の問題
ハルシネーションとは、生成AIが事実に基づかない情報を、あたかも真実であるかのように生成する現象です。これは、AIが学習データに含まれる情報の関連性を確率的に判断して文章を生成する仕組みに起因します。そのため、特に専門的な内容や最新のトピックについて質問した場合、誤った情報を自信満々に回答してしまうことがありました。
この問題は、生成AIの回答を鵜呑みにできないという根本的な信頼性の欠如につながり、ビジネス利用における大きなリスクとなります。RAGは、回答を生成する際に必ず信頼できる外部情報源を参照するため、このハルシネーションを大幅に抑制できます。(出典:「RAG」とは何か?~生成AIの信頼性を向上させるための仕組みを解説)しかし、検索品質や知識ベースの正確性に依存するため、完全には排除されません。高信頼性が求められる用途では、人間によるレビューといった仕組みが依然として重要です。

学習データ以降の最新情報に対応できない限界
GPTシリーズやGeminiなどの大規模言語モデル(LLM)は、そのモデルが訓練された時点までの情報しか持っていません。そのため、新しい製品情報、法改正、市場の最新動向など、学習データに含まれていない新しい出来事については回答できないという限界がありました。
ビジネスの世界では、常に最新の情報に基づいた意思決定が求められます。情報が古いというだけで、生成AIの回答は価値を失ってしまうのです。RAGは、外部データベースからリアルタイムで情報を取得するため、LLMの知識を常に最新の状態に保つことができます。これにより、情報の鮮度が重要な業務でも生成AIを活用できるようになります。

回答の根拠が不明瞭なブラックボックス問題
従来の生成AIは、なぜその回答に至ったのか、その思考プロセスや根拠となった情報源がユーザーには分かりませんでした。これは「ブラックボックス問題」と呼ばれ、回答の妥当性を検証することが困難でした。
特に、コンプライアンスや正確性が厳しく問われる業務では、根拠不明な情報を利用することはできません。RAGは、回答を生成する際に参照した情報源を明示できるという大きな特長があります。これにより、ユーザーは回答の根拠を自ら確認し、その信頼性を判断できます。ただし、正確な出典を提示するためには、データの分割単位(チャンク)に文書IDやページ番号といったメタデータを適切に設計し、検証する仕組みを組み込むことが重要です。この透明性の高さが、ビジネス利用における安心感につながるのです。

法人向けAI研修
AX CAMP 無料資料
RAGの仕組みを3つのステップでわかりやすく解説
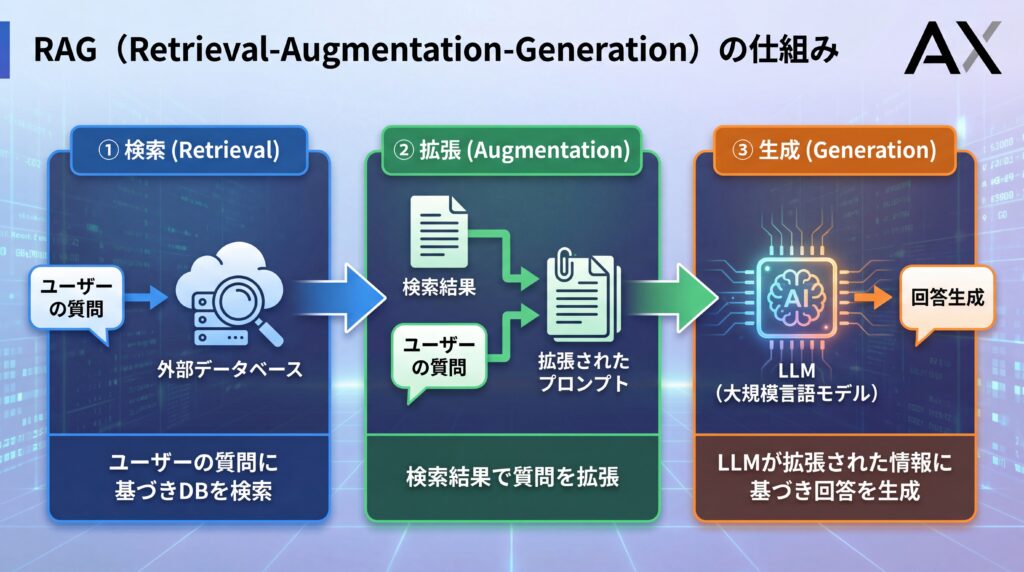
RAGの仕組みは、一見複雑に思えるかもしれませんが、実際には「検索」「拡張」「生成」という3つのシンプルなステップで構成されています。この一連の流れによって、生成AIは外部の知識を活用し、正確で信頼性の高い回答を生み出すことができます。それぞれのステップがどのように連携して機能するのかを具体的に見ていきましょう。
ステップ1:検索(Retrieval)- 関連情報の特定
最初のステップは「検索(Retrieval)」です。ユーザーから質問(プロンプト)が入力されると、RAGシステムはまず、その質問内容と関連性の高い情報を、あらかじめ接続されている外部の知識データベースから探し出します。
このとき、単なるキーワード検索ではなく、質問の意図や文脈を理解して意味的に近い情報を特定する「ベクトル検索」という技術が主に使われます。(出典:ベクトル データベースとは)例えば、「昨年度のIT部門の経費削減実績は?」という質問に対し、「経費」「削減」「IT」といったキーワードだけでなく、関連する稟議書や予算実績報告書などを的確に見つけ出します。
ステップ2:拡張(Augmentation)- プロンプトの強化
次のステップは「拡張(Augmentation)」です。ステップ1で検索された関連情報(コンテキスト)を使って、元の質問(プロンプト)を強化・拡張します。具体的には、元の質問文と、検索で見つかった情報を組み合わせて、新しいプロンプトを作成します。
例えば、元の質問が「テレワークの新しい規定について教えて」だった場合、検索で見つかった「テレワーク勤務規程第3版.pdf」の内容をプロンプトに追加します。これにより、LLMに対して「『テレワーク勤務規程第3版.pdf』の内容に基づいて、テレワークの新しい規定について教えてください」という、より具体的で情報が豊富な指示を与えられます。
ステップ3:生成(Generation)- 回答の作成
最後のステップが「生成(Generation)」です。ステップ2で拡張されたプロンプトが、GPTシリーズなどの大規模言語モデル(LLM)に送られます。LLMは、与えられた外部情報(コンテキスト)を最優先の参考資料としますが、その情報を完全に鵜呑みにするわけではありません。
LLMは自身の内部知識も参照しますが、プロンプトで与えられた外部情報に矛盾しないように回答を作成するため、ハルシネーションが起こりにくくなります。(出典:「RAG」とは何か?~生成AIの信頼性を向上させるための仕組みを解説) さらに、参照した情報源を回答と共に出力するように設定すれば、ユーザーはいつでもその根拠を確認できます。この3ステップにより、RAGは高精度な回答生成を実現しているのです。
RAGとファインチューニングの決定的な違い
RAGとよく比較される技術に「ファインチューニング」があります。どちらもLLMの性能を向上させる手法ですが、その目的とアプローチは根本的に異なります。ビジネス要件に合った最適な手法を選ぶためには、両者の違いを正確に理解しておくことが重要です。
端的に言えば、RAGは「知識」を外部から与える技術であり、ファインチューニングは「振る舞いや口調」をモデル内部に学習させる技術です。この違いが、コストや更新性、柔軟性に大きな差を生みます。
目的とアプローチの違い
RAGの主な目的は、LLMが持っていない最新情報や専門知識をリアルタイムで提供し、回答の正確性を高めることです。アプローチとしては、外部のデータベースを検索し、得られた情報を基に回答を生成します。
一方、ファインチューニングの目的は、特定のタスクや文体に合わせてLLMの応答スタイルや振る舞いを調整することです。例えば、特定のキャラクターのような口調で話させたり、特定の形式(メール作成、要約など)の文章生成に特化させたりする場合に有効です。アプローチとしては、追加の学習データセットを用いてLLM自体を再トレーニングします。
コスト・更新性・柔軟性の比較
RAGとファインチューニングは、実用面で大きな違いがあります。以下の比較表で、自社の目的にどちらが適しているかを確認しましょう。
| 比較項目 | RAG(検索拡張生成) | ファインチューニング |
|---|---|---|
| 目的 | 知識の外部注入、回答の正確性向上 | 応答スタイル、振る舞いの調整 |
| コスト | ケースバイケース(DB運用コストは継続的に発生) | ケースバイケース(PEFT等で安価な場合もある) |
| 情報の更新性 | 非常に高い(DBの更新で反映) | 低い(再学習が必要) |
| 根拠の提示 | 可能(参照元を明示できる) | 不可能(回答の根拠は不明瞭) |
| 導入の手軽さ | 比較的容易 | 専門知識と時間が必要 |
コストはユースケースによって変動するため、一概にどちらが優れているとは言えません。RAGは初期導入が比較的早いものの、継続的な検索・推論コストやベクトルデータベースの運用コストがかかります。一方で、LoRAなどの効率的な手法(PEFT)を用いれば、ファインチューニングが安価に済む場合もあります。最新情報への対応や事実に基づいた回答が求められる多くのビジネスシーンではRAGが有効ですが、最適な手法は要件次第と言えるでしょう。

法人向けAI研修
AX CAMP 無料資料
RAG導入による主要なメリット

RAGを導入することで、企業は生成AIの活用レベルを大きく引き上げることができます。そのメリットは多岐にわたりますが、特にビジネスインパクトが大きいのは「回答の信頼性向上」「情報の最新性と専門性の確保」「開発コストと時間の削減」という3つの点です。
1. 回答の信頼性向上(ハルシネーション抑制と根拠提示)
RAG導入の大きなメリットは、回答の信頼性が向上する点です。生成AIの最大の欠点であったハルシネーション(もっともらしい嘘)は、信頼できる社内データや公式文書といった外部情報源を基に回答を生成することで、大幅に抑制されることが期待できます。(出典:「RAG」とは何か?~生成AIの信頼性を向上させるための仕組みを解説)
さらに、RAGは回答と同時に根拠となった情報源(どの文書の何ページを参照したかなど)を提示できます。これにより、ユーザーは回答の正しさを簡単に検証でき、安心してAIの回答を業務に利用できます。(出典:RAGで生成AIの「うそ」は減らせる? 仕組みや活用例、課題を解説)この透明性は、金融や法務など、情報の正確性が極めて重要な業界でのAI活用を可能にします。
2. 情報の最新性と専門性の確保
ビジネス環境は常に変化しており、最新の情報に基づいた判断が不可欠です。RAGは、外部データベースを更新するだけで、常に最新の情報を回答に反映させることができます。これにより、LLM本体を再学習させる手間とコストをかけることなく、情報の鮮度を維持できます。
また、社内マニュアル、研究開発データ、顧客からのフィードバックといった、インターネット上には存在しない専門的かつクローズドな情報を知識源として活用できるのも大きな強みです。これにより、自社の状況に即した、より価値の高い回答をAIに生成させることが可能になります。
3. 開発コストと時間の削減
特定の業務に特化したAIを開発する際、従来はファインチューニングが主な手法でしたが、これには高品質な学習データを大量に用意し、膨大な計算コストをかけてモデルを再学習させる必要がありました。
RAGは、既存のLLMはそのままに、知識源となるデータを準備するだけで済むため、開発にかかるコストと時間を大幅に削減できる場合があります。多くの企業にとって、AI導入のハードルを大きく下げる要因となるでしょう。プロトタイプの開発も迅速に行えるため、スモールスタートでAI活用の効果を検証しやすい点もメリットです。

知っておくべきRAGのデメリットと対策
RAGは非常に強力な技術ですが、万能というわけではありません。導入を成功させるためには、そのデメリットや注意点を理解し、あらかじめ対策を講じておくことが重要です。主な課題は「検索精度への依存性」と「システム構成の複雑化」の2点です。
検索精度への依存性と対策
RAGの回答品質は、ステップ1の「検索(Retrieval)」の精度に大きく依存します。質問に対して適切な情報を見つけられなければ、たとえ高性能なLLMを使っても、的外れな回答や不正確な回答が生成されてしまいます。「ゴミを入れればゴミが出る(Garbage In, Garbage Out)」という原則が、RAGにも当てはまるのです。
この課題への対策は以下の通りです。
- 高品質な知識ベースの構築:参照するデータは事前にクレンジングし、整理しておく必要があります。
- 高性能な検索技術の採用:キーワード検索とベクトル検索を組み合わせた「ハイブリッド検索」などが有効です。
- データの定期的な棚卸し:情報が古くならないよう、定期的なメンテナンスが不可欠です。
これらの対策を通じて、知識源となるデータベースの品質を担保することが、RAGの性能を最大限に引き出す上で極めて重要になります。
システム構成の複雑化とデータ管理の重要性
RAGシステムは、LLMに加えて、データを取り込む部分、情報をベクトル化して保存するベクトルデータベース、検索を実行する部分など、複数のコンポーネントを組み合わせる必要があり、システム構成が複雑になりがちです。
この課題への対策は以下の通りです。
- マネージドサービスの活用:AWSやAzureなどが提供するサービスを利用し、構築・運用の手間を削減します。
- データガバナンスの徹底:機密情報が漏洩しないよう、アクセス権限を適切に管理することが重要です。
- スモールスタートでの導入:まずは限定的な範囲で導入し、知見を蓄積しながら段階的に拡大します。
特に、誰がどのデータにアクセスできるかを管理するデータガバナンスは、セキュリティを確保する上で欠かせない要素です。
法人向けAI研修
AX CAMP 無料資料
【2026年版】RAGの主な活用事例
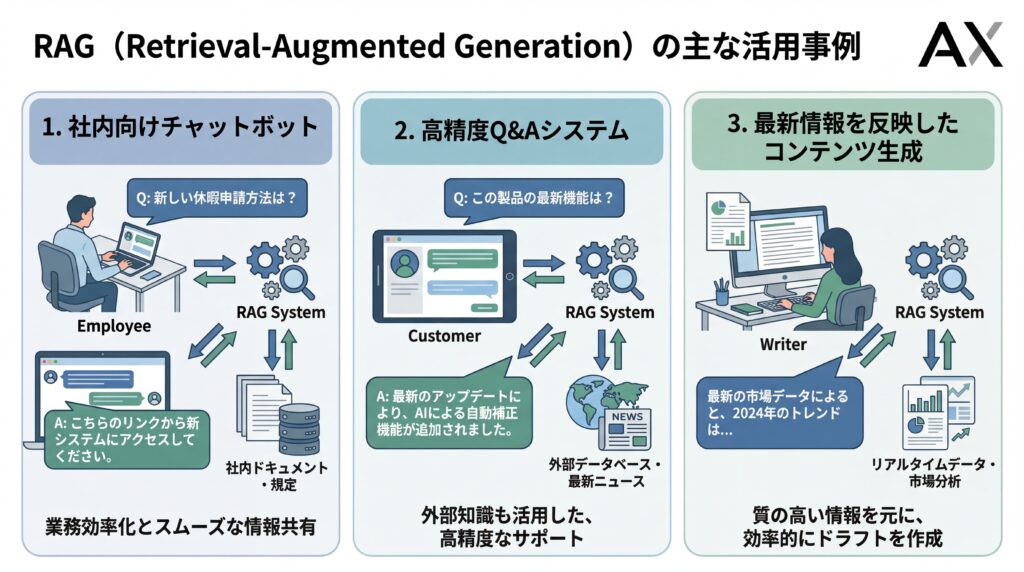
RAGの技術は、すでに多くの企業で実用化が進んでおり、業務効率化や顧客満足度向上に大きく貢献しています。ここでは、具体的な活用イメージを掴んでいただくために、代表的な3つのユースケースと、当社AX CAMP(エーエックスキャンプ)の支援を通じて成果を上げた企業の事例をご紹介します。
高精度な社内向けAIチャットボット
RAGの最も代表的な活用例が、社内向けの高精度なAIチャットボットです。経費精算の規定、IT機器のトラブルシューティング、人事関連の手続きなど、社員からの頻繁な問い合わせに対して、社内規定やマニュアルに基づき24時間365日、参照データに基づく回答を行います。ただし、生成された回答の最終的な確認は人間が行うことが重要です。
これにより、バックオフィス部門の担当者は定型的な問い合わせ対応から解放され、より付加価値の高い業務に集中できます。また、社員は必要な情報をいつでも迅速に入手できるため、業務の生産性が向上します。例えば、三井住友フィナンシャルグループでは、約130万件の社内ファイルを対象としたRAGシステムを導入し、業務効率化を進めていると報告されています。(出典:三井住友FGが「約130万件の社内ファイル」を食わせた生成AIの正体)

専門的なQ&Aシステムの構築
法律、医療、金融といった高度な専門知識が求められる分野でも、RAGは非常に有効です。膨大な量の専門文献、判例、論文などを知識データベースとすることで、専門家の調査・分析業務を支援するQ&Aシステムを構築できます。
例えば、弁護士が過去の類似判例を検索したり、医師が最新の治療ガイドラインを確認したりする際に、RAGシステムが瞬時に適切な情報を提供します。ただし、これらはあくまで支援ツールであり、診断や最終的な法的判断は必ず各分野の専門家が行う必要があり、参照情報の正確性についても専門家による検証が不可欠です。
最新情報を反映したコンテンツ生成支援
マーケティング部門におけるコンテンツ制作も、RAGによって大きく効率化できます。最新の市場調査レポート、競合製品のニュースリリース、自社のアクセス解析データなどを知識源とすることで、時事性の高いブログ記事やSNS投稿、メルマガの原稿などをAIが生成します。
これにより、コンテンツ制作者は情報収集や下書き作成の時間を削減し、企画やクリエイティブな作業に注力できます。常に最新のトレンドを反映した、質の高いコンテンツを安定的に発信することが可能になります。
C社様(SNSマーケティング事業)の事例
SNSマーケティング事業を手がけるC社様は、業務の属人化とSNS投稿の成果に伸び悩みを抱えていました。AX CAMP(エーエックスキャンプ)の支援のもと、非エンジニアチームがAIを活用し、SNS運用の自動化システムを内製化。その結果、RAGを活用して最新のトレンドやデータを反映した投稿案を自動生成できるようになり、1日3時間かかっていた運用業務をわずか1時間に短縮(66%削減)し、月間1,000万インプレッションを達成しました。(出典:【AX CAMP】非エンジニアがAIで月間1,000万impのSNS運用を自動化!C社が実現したAI活用が当たり前の文化とは?)
WISDOM合同会社様(広告・動画制作事業)の事例
SNS広告やショート動画制作を行うWISDOM合同会社様は、事業拡大に伴う人材採用のコストと業務負荷の増大が課題でした。AX CAMP(エーエックスキャンプ)の研修を通じてAIスキルを習得し、RAGを活用した情報検索システムや定型業務の自動化を推進。結果として、新たに採用予定だった2名分の業務をAIが代替し、採用計画を見直すほどの成果を上げ、コストをかけずに事業を成長させることに成功しました。(出典:【AX CAMP】AI導入で採用2名分の人件費を削減!WISDOM社が実現した事業成長と業務効率化の両立)
株式会社エムスタイルジャパン様(美容健康食品事業)の事例
美容健康食品の製造販売を行う株式会社エムスタイルジャパン様では、コールセンターでの顧客対応履歴の確認や、手作業での広告レポート作成に多くの時間を費やしていました。AX CAMP(エーエックスキャンプ)で学んだスキルを活かし、GAS(Google Apps Script)とAIを連携させたRAGシステムを構築。これにより、月16時間かかっていたコールセンターの確認業務がほぼ0時間になり、全社で月100時間以上の業務削減を達成しました。(出典:【AX CAMP】月100時間以上の“ムダ業務”をカット!エムスタイルジャパン社が築いた「AIは当たり前文化」の軌跡)

RAG導入を成功させるための重要なポイント
RAGの導入を成功に導くためには、技術的な側面だけでなく、戦略的な視点が不可欠です。やみくもに導入するのではなく、「目的の明確化とスモールスタート」および「高品質なデータと最適な技術の選定」という2つの重要なポイントを押さえることが成功のカギとなります。
目的の明確化とスモールスタート
まず最も重要なのは、「RAGを導入して、どのような課題を解決したいのか」という目的を明確にすることです。「社内の問い合わせ対応工数を30%削減する」「マーケティングコンテンツの制作時間を半分にする」など、具体的で測定可能な目標を設定しましょう。
目的が明確になったら、いきなり全社展開を目指すのではなく、特定の部門や業務に絞ってスモールスタートで始めることを推奨します。例えば、まずは人事部のFAQ対応チャットボットから始めるなど、効果を検証しやすく、影響範囲が限定的な領域から着手することで、リスクを抑えながら知見を蓄積できます。ここで得られた成功体験と課題を基に、段階的に適用範囲を拡大していくのが成功への近道です。
高品質なデータと最適な技術の選定
前述の通り、RAGの性能は知識源となるデータの品質に大きく左右されます。導入プロジェクトの初期段階で、利用するデータソースを特定し、その品質を評価・整備することが不可欠です。文書のフォーマットが統一されていなかったり、古い情報や誤った情報が含まれていたりする場合は、事前にデータをクレンジングし、整理しておく必要があります。
また、RAGを実現するための技術要素(ベクトルデータベース、検索アルゴリズム、LLMなど)には様々な選択肢があります。自社の要件(セキュリティ、コスト、拡張性など)や技術チームのスキルセットに合わせて、最適な技術スタックを選定することが重要です。クラウドサービスを活用するのか、オープンソースを組み合わせるのかなど、長期的な運用を見据えた選択が求められます。
法人向けAI研修
AX CAMP 無料資料
RAGシステムの基本的な構築方法
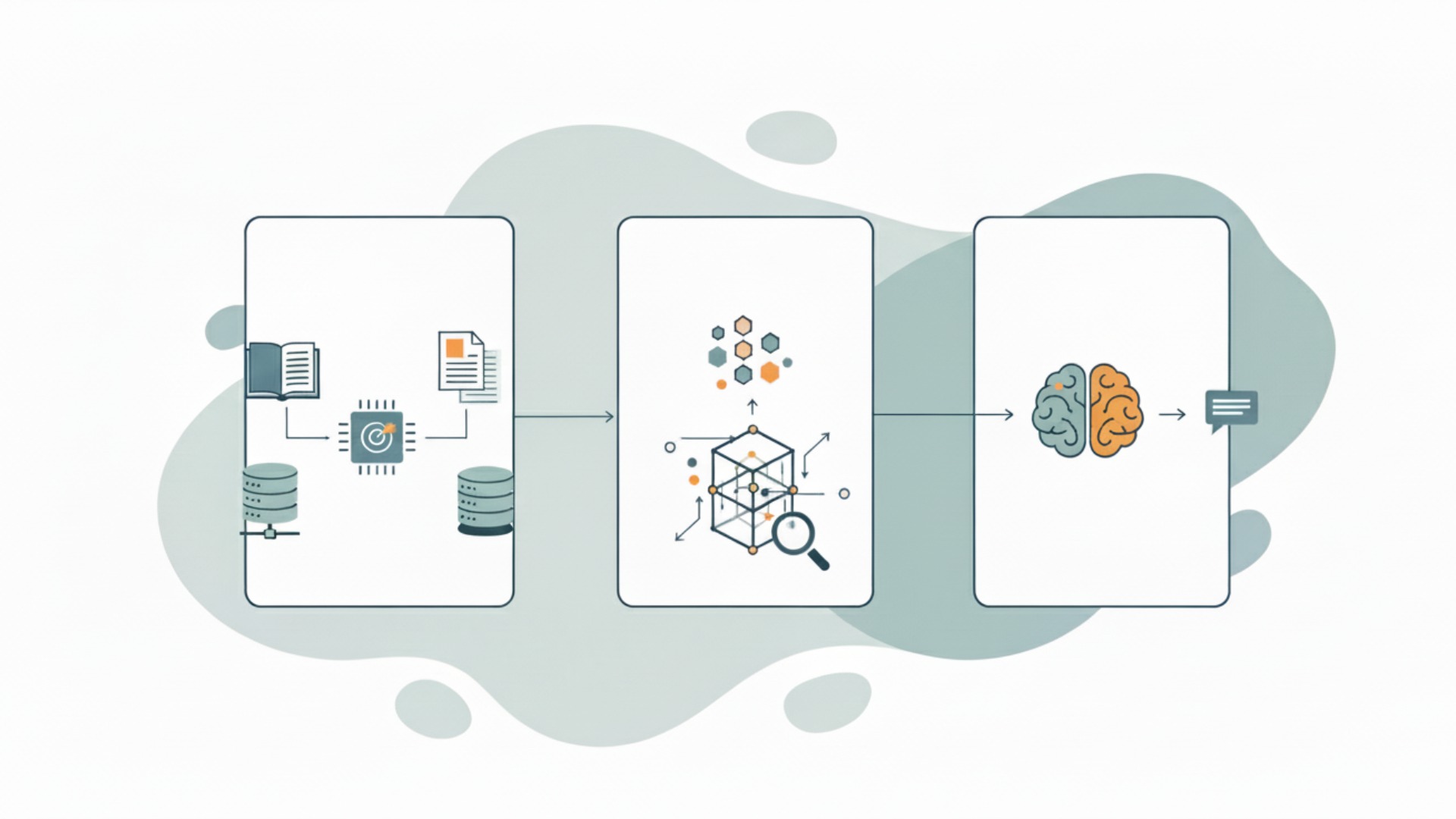
RAGシステムを構築するプロセスは、大きく3つのステップに分けられます。それは「データソースの準備」「エンベディングとベクトルデータベースの選定」「LLMの選択と連携」です。ここでは、それぞれのステップで具体的に何を行うのか、その概要を解説します。
データソース(ナレッジベース)の準備と前処理
最初のステップは、RAGの知識源となるデータソース(ナレッジベース)を準備することです。社内規定のPDF、業務マニュアルのWordファイル、過去の問い合わせ履歴が記録されたExcelファイルなど、AIに参照させたいあらゆるドキュメントが対象となります。
集めたデータは、そのままではAIが処理しにくいため、前処理が必要です。具体的には、ドキュメントを意味のある単位(段落など)で小さな塊(チャンク)に分割します。このチャンク化の粒度が、後の検索精度に影響を与えるため、非常に重要な工程です。不要なヘッダーやフッターを削除するなどのデータクレンジングもこの段階で行います。
エンベディングモデルとベクトルデータベースの選定
次に、前処理したテキストデータ(チャンク)を、AIが意味を理解できる数値の羅列、すなわち「ベクトル」に変換します。この処理を「エンベディング」と呼び、専用のエンベディングモデルを使用します。
変換されたベクトルデータは、「ベクトルデータベース」という専用のデータベースに格納されます。ベクトルデータベースは、ベクトルの類似度を高速に計算し、関連性の高い情報を瞬時に検索することに特化しています。Pinecone、Milvus、Chroma DBといった多様な選択肢があり、プロジェクトの規模や要件に応じて最適なものを選定します。
LLM(大規模言語モデル)の選択と連携
最後のステップは、中核となるLLM(大規模言語モデル)を選び、システム全体を連携させることです。LLMにはOpenAIのGPTシリーズ、GoogleのGemini、AnthropicのClaudeシリーズなど、様々なモデルが存在します。それぞれのモデルに得意・不得意があるため、コスト、性能、セキュリティ要件などを考慮して最適なLLMを選択します。
そして、ユーザーからの質問入力、ベクトルデータベースでの検索、検索結果と質問を組み合わせたプロンプトの作成、LLMへの送信、そして最終的な回答の生成という一連の流れをプログラムとして実装します。この全体の処理フローを効率的に構築するために、後述するLangChainやLlamaIndexといったフレームワークがよく利用されます。
RAGの精度を最大化する先進的テクニック
基本的なRAGシステムを構築した上で、さらに回答の精度を追求するためには、いくつかの先進的なテクニックを導入することが有効です。ここでは、「ハイブリッド検索」や「クエリ変換・リランキング・自己修正」といった、より高度なRAGの手法について紹介します。これらの技術を組み合わせることで、複雑な質問に対しても的確な回答を生成できる可能性が高まります。
ハイブリッド検索による検索精度の向上
RAGの根幹である検索ステップの精度を高めるために、複数の検索手法を組み合わせる「ハイブリッド検索」が注目されています。これは、従来からあるキーワードベースの検索(BM25など)と、意味の類似性で検索するベクトル検索を組み合わせるアプローチです。
ベクトル検索は文脈を捉えるのが得意ですが、特定の固有名詞や製品型番などのキーワードを正確に捉えられないことがあります。一方でキーワード検索はその逆です。両者を組み合わせることで、互いの弱点を補い、より網羅的で精度の高い検索結果を得ることができ、最終的な回答の品質向上につながります。
クエリ変換・リランキング・自己修正による回答品質の向上
検索精度だけでなく、LLMに渡す情報の質を高めるためのテクニックも進化しています。
- クエリ変換:ユーザーの曖昧な質問を、検索に適した明確な質問にLLM自身が書き換える技術です。
- リランキング:一度検索した結果を、再度LLMが評価し、質問との関連性が最も高い順に並べ替える手法です。
- 自己修正(Self-Correction):生成した回答が元の質問の意図と合っているかなどをLLMが自らチェックし、問題があれば修正する技術です。
これらの手法により、RAGシステムはより高度な対話能力を持つようになります。特に自己修正は、自己完結的な品質向上サイクルを実現する点で非常に強力です。
法人向けAI研修
AX CAMP 無料資料
【2026年最新】おすすめのRAG関連ツール・サービス

RAGシステムをゼロから構築するのは大変ですが、幸いなことに、開発を効率化し、高度な機能を実現するための様々なツールやサービスが存在します。これらは大きく「主要クラウドプラットフォーム」が提供するマネージドサービスと、「オープンソースフレームワーク」に大別されます。自社の状況に合わせてこれらを適切に選択・活用することが、RAG導入の成功につながります。
主要クラウドプラットフォーム(AWS, Azure, Google Cloud)
大手クラウドベンダーは、RAGシステムの構築に必要なコンポーネントを統合し、簡単に利用できるサービスを提供しています。これらを利用することで、インフラ管理の手間を大幅に削減し、アプリケーション開発に集中できます。
- Amazon Web Services (AWS):エンタープライズ向け検索サービス「Amazon Kendra」やベクトルデータベース機能を持つ「Amazon OpenSearch Service」などを提供。
- Microsoft Azure:「Azure AI Search」が中核となり、Azure OpenAI Serviceとシームレスに連携できます。
- Google Cloud:「Vertex AI Search」が同様の機能を提供しており、GeminiなどのLLMと強力に連携します。
これらのサービスは、各社のLLMとスムーズに連携できる点が大きな強みです。
オープンソースフレームワーク(LangChain, LlamaIndex)
より柔軟なカスタマイズや、特定のクラウドに依存しないシステム構築を目指す場合には、オープンソースのフレームワークが有力な選択肢となります。中でも、LangChainとLlamaIndexは、RAG開発の主要フレームワークとして広く採用されています。
- LangChain:LLMアプリケーション開発のための汎用的なフレームワークで、データ連携からエージェント機能まで幅広くカバーします。
- LlamaIndex:RAGの構築、特にデータのインデックス作成と検索機能に特化したフレームワークで、効率的なデータ検索パイプラインの構築に強みがあります。
LangChainとLlamaIndexは競合するだけでなく、それぞれの得意な機能を組み合わせて利用することも可能です。
生成AIとRAGの今後の展望と未来予測

RAG技術は、生成AIの可能性を大きく広げ、今もなお急速な進化を続けています。今後は、テキスト情報だけでなく、画像や音声といった多様なデータを扱う「マルチモーダルRAG」や、自律的にタスクを遂行する「AIエージェント」との連携が、RAGの新たなフロンティアになると予測されています。
マルチモーダルRAGの進化
現在のRAGは、主にテキストデータを知識源としていますが、将来的には、画像、音声、動画、図面といった非構造化データも統合的に扱える「マルチモーダルRAG」へと進化していくでしょう。例えば、製品の設計図(画像)を読み込ませて仕様に関する質問に答えさせたり、会議の録音(音声)を基に議事録を要約させたりすることが可能になります。
これにより、RAGの活用範囲は製造業の設計部門や、メディア業界のコンテンツ管理など、これまで以上に幅広い分野へと拡大していきます。テキストと画像を組み合わせた検索など、より人間に近い高度な情報検索が実現されると期待されています。

自律型AIエージェントとの連携
もう一つの重要なトレンドは、RAGと自律型AIエージェントの融合です。AIエージェントとは、与えられた目標に対して、自ら計画を立て、必要なツール(RAGによる情報検索を含む)を使いこなしながらタスクを遂行するAIのことです。
例えば、「競合A社の新製品の評判を調査してレポートを作成して」と指示すると、AIエージェントが自律的にWeb検索を行い、関連ニュースやSNSの投稿をRAGで収集・分析し、最終的なレポートを生成する、といったことが可能になります。RAGがエージェントの「知識収集能力」を担うことで、AIは単なる応答システムから、能動的に業務を遂行するパートナーへと進化していくでしょう。

法人向けAI研修
AX CAMP 無料資料
生成AIの導入・活用ならAX CAMP(エーエックスキャンプ)

生成AI、特にRAGのような先進技術の導入には、専門的な知識と戦略的なアプローチが不可欠です。しかし、「何から手をつければ良いかわからない」「社内にAIに詳しい人材がいない」といった課題を抱える企業は少なくありません。もし貴社が同様の課題を感じているなら、実践型の法人向けAI研修・伴走支援サービス「AX CAMP(エーエックスキャンプ)」がお役に立てるかもしれません。
AX CAMP(エーエックスキャンプ)は、単なる知識の提供に留まりません。貴社の具体的な業務課題をヒアリングし、RAGを活用した社内チャットボットの開発や業務自動化システムの構築など、実務に直結するテーマで研修をカスタマイズします。非エンジニアの方でも、手を動かしながらAI開発のスキルを習得できるカリキュラムが特長です。
研修後も、専門家による伴走支援を通じて、現場でのAI活用が定着するまでを徹底的にサポートします。RAG導入の企画から、データ準備、システム構築、そして社内展開まで、一気通貫でご支援することで、AI活用の成功確率を最大化します。AI導入の第一歩を確実に踏み出したい、また、既存の取り組みをさらに加速させたいとお考えでしたら、まずは無料相談からお気軽にお問い合わせください。

法人向けAI研修
AX CAMP 無料資料
まとめ:生成AIとRAGを理解し、ビジネス活用を次のレベルへ
本記事では、生成AIの回答精度と信頼性を飛躍的に向上させる技術「RAG(検索拡張生成)」について、その仕組みからメリット、具体的な活用事例、導入のポイントまでを網羅的に解説しました。最後に、重要なポイントを振り返ります。
- 外部DBの参照:RAGは外部の知識データベースを参照して回答を生成する技術です。
- 信頼性の向上:ハルシネーションを抑制し、回答の根拠を提示できます。
- 情報の鮮度:常に最新かつ専門的な情報をAIの回答に反映させることが可能です。
- コスト効率:ファインチューニングに比べて低コストかつ迅速に導入できる場合があります。
- 成功の鍵:導入目的の明確化と、参照するデータの品質担保が重要です。
RAGは、生成AIが抱えていた「不正確さ」や「情報の古さ」といった課題を克服し、ビジネスの現場で本格的に活用するための鍵となる技術です。社内情報の検索、顧客対応の自動化、専門的な調査業務の支援など、その応用範囲は非常に広く、多くの企業にとって大きな業務効率化と生産性向上をもたらすポテンシャルを秘めています。
もし、この記事を読んで「自社でもRAGを活用してみたい」「AI導入を具体的に進めたい」と感じられたなら、ぜひAX CAMP(エーエックスキャンプ)にご相談ください。専門的な知見と豊富な支援実績を持つ私たちが、貴社のAI活用を成功へと導くための最適なプランをご提案します。AIを単なるツールとしてではなく、事業成長を加速させる強力な武器とするために、私たちと一緒に最初の一歩を踏み出しましょう。

法人向けAI研修
AX CAMP 無料資料