

自社専用のLLM(大規模言語モデル)を開発したいが、どこから手をつければ良いかわからない。そんな悩みを抱えるプロジェクトマネージャーやエンジニアは少なくありません。LLM開発には複数のアプローチがあり、それぞれにメリット・デメリットが存在するため、自社の目的やリソースに合った最適な手法を見極めることが成功の鍵となります。
この記事では、LLM開発の主要な3つのアプローチを徹底比較し、それぞれの具体的な開発フローから必要なリソース、性能を最大化する技術までを網羅的に解説します。最後まで読めば、自社に最適なLLM開発の道筋を描き、プロジェクトを成功に導くための具体的な知識が身につくでしょう。AI開発の企画や推進に役立つ「LLM導入・活用事例集」もご用意しておりますので、ぜひご活用ください。

法人向けAI研修
AX CAMP 無料資料
LLM(大規模言語モデル)とは?

LLM(Large Language Models)とは、膨大なテキストデータから言語のパターンを学習し、人間のように自然な文章を生成・理解する能力を持つAIモデルを指します。Transformerと呼ばれるニューラルネットワークアーキテクチャを基盤としており、複雑な文脈理解や高度な文章生成を実現しています。この革新的な技術は、質問応答、文章要約、翻訳、コンテンツ作成など、多岐にわたるタスクでその真価を発揮しています。
従来のAIが特定のタスクに特化して開発されていたのに対し、LLMは汎用的な言語能力を持つ点が大きな違いです。この特性により、一つのモデルで様々な応用が可能となり、ビジネスにおける活用の幅を大きく広げました。ただし、事実と異なる内容を生成する「ハルシネーション」という課題も存在するため、その特性を理解した上での活用が求められます。
生成AIとの関係性
生成AI(Generative AI)は、文章、画像、音声、コードといった新しいコンテンツを創出するAI技術の総称です。その中でLLMは、特にテキスト生成を担う中核的な技術として位置づけられています。例えば、ChatGPTのような対話型AIサービスは、ユーザーの入力に対して自然な対話文を生成するために、内部でGPTシリーズなどの高性能なLLMが稼働しています。つまり、LLMは多彩な生成AIを実現するための、強力な「エンジン」の一つと言えるのです。
基本的な仕組みと従来のAIとの違い
LLMの基本的な仕組みは、入力されたテキスト(プロンプト)に続く単語を確率的に予測し、それらを繋ぎ合わせて文章を生成することにあります。この予測精度を極限まで高めるために、インターネット上のテキストや書籍など、人間が生成した膨大な量のデータを学習します。このプロセスは「事前学習」と呼ばれています。
従来のAI、特にルールベースAIや統計的機械学習モデルとの決定的な違いは、学習データの規模とモデルの汎用性にあります。従来のAIは、特定の目的に合わせて人間が設計したルールや、比較的小規模なデータセットで学習していました。対照的に、LLMは何十億、何兆というパラメータを持ち、広範なデータセットで学習することで、特定のルールに縛られない柔軟で汎用的な言語能力を獲得しているのです。
https://media.a-x.inc/ai-llm
https://media.a-x.inc/ai-vs-ai
LLM開発の3つの主要アプローチ
LLMを自社で開発・活用するには、大きく分けて3つのアプローチが存在します。「ゼロからの構築(事前学習)」「既存モデルのカスタマイズ(ファインチューニング)」「外部APIの活用」の3つです。どのアプローチを選択するかは、プロジェクトの目的、予算、技術力、そして求める独自性のレベルによって大きく異なります。自社の状況を正確に把握し、最適な手法を選ぶことがプロジェクト成功の鍵を握ります。
ここでは、それぞれのメリット・デメリットを比較し、どのようなケースに適しているのかを解説していきましょう。
アプローチ1:ゼロからモデルを構築(事前学習)
これは、独自のデータセットを用いて、LLMそのものをゼロから学習させる最も高度なアプローチです。特定のドメインに完全に特化した、他にはない独自の言語モデルを開発できます。しかし、その実現には膨大な計算リソースと大規模なデータセット、そして高度な専門知識を持つAIエンジニアチームが不可欠です。(出典:AI Index Report 2024)スタンフォード大学の「AI Index Report 2024」によると、GoogleのGemini Ultraの推定訓練コストは1億9,100万ドル(約286億円)に達するとされており、コストは数十億から数百億円規模になることも珍しくありません。開発期間も年単位に及ぶため、ごく一部の研究機関や巨大テック企業に限られるのが現状です。
アプローチ2:既存の基盤モデルをカスタマイズ(ファインチューニング)
ファインチューニングは、OpenAIのGPTシリーズやGoogleのGeminiなど、既に事前学習済みの強力な基盤モデルに対し、自社独自のデータを追加で学習させる手法です。これにより、基盤モデルの汎用的な能力を維持しつつ、特定の業界用語や社内独自の対話スタイル、専門知識などをモデルに反映させられます。ゼロからの構築に比べて、コストと期間を大幅に抑えながら、高い独自性と性能を両立できるため、多くの企業にとって最も現実的で効果的な選択肢と言えます。ただし、高品質な学習データの準備や、過学習(特定のデータに最適化されすぎて汎用性を失うこと)を防ぐための専門知識が求められます。

アプローチ3:外部APIを活用してサービスを開発
これは、OpenAIやGoogleなどが提供するLLMのAPI(Application Programming Interface)を利用して、自社のアプリケーションやサービスにAI機能を組み込むアプローチです。モデルの開発や学習は一切不要で、APIを呼び出すだけで高度な言語処理機能を利用できます。そのため、最も迅速かつ低コストでLLMの導入が可能です。多くのSaaSプロダクトやチャットボットがこの方法で開発されています。一方で、モデル自体をカスタマイズすることはできないため、独自性の確保や、非常に専門的なタスクへの対応には限界があります。また、APIの利用料金や外部サービスへの依存がデメリットとなる場合もあります。(出典:生成AIのAPI連携とは?メリット・デメリットや料金、活用事例を解説)
法人向けAI研修
AX CAMP 無料資料
【実践】LLM開発の具体的なフロー
LLMの開発は、どのアプローチを選択するにしても、体系的なフローに沿って進めることが重要です。一般的に、開発プロセスは「データセットの準備」「モデルの学習と評価」「デプロイと運用・保守」という3つの主要なフェーズに分けられます。これらの各ステップを丁寧に進めることで、高品質で信頼性の高いLLMアプリケーションを構築できます。(出典:LLM導入の5ステップと開発アプローチを解説)
以下では、特に「ゼロから構築」や「ファインチューニング」を行う際の具体的な流れを解説します。
データセットの収集と前処理
LLMの性能は、学習データの質と量に大きく左右されます。開発の最初のステップは、目的に合った高品質なテキストデータを大量に収集することです。収集元としては、社内ドキュメント、ウェブサイトのテキスト、書籍、専門論文などが考えられます。ただし、データを収集する際は、著作権や利用規約、個人情報保護法を遵守することが極めて重要です。特にウェブサイトからのスクレイピングや書籍・論文の利用には、権利者の許諾が必要となるケースがあるため、法的な確認が不可欠です。
収集したデータはそのままでは使えず、「前処理」と呼ばれる工程が必要です。これには、不要な記号やHTMLタグの除去、テキストの形式統一などが含まれます。個人情報を含むデータを扱う場合は、利用目的の明確化や適切な匿名化処理など、社内の個人情報保護方針や法令に厳密に従う必要があります。これらの処理を経て、テキストをモデルが処理できる最小単位(トークン)に分割する「トークン化」を行います。この地道な準備が、最終的なモデルの精度を決定づける非常に重要な工程です。
https://media.a-x.inc/llm-data
モデルの学習と評価
データセットの準備が完了したら、次はいよいよモデルの学習です。ゼロから構築する場合は、モデルのアーキテクチャ(構造)を設計し、膨大な計算リソースを使って事前学習を行います。ファインチューニングの場合は、既存の基盤モデルに準備した独自データセットを追加学習させます。(出典:LLM開発の全体像:データ収集からデプロイまで)
学習がある程度進んだら、その性能を客観的に評価する必要があります。評価用のデータセットをあらかじめ用意しておき、正解率や、生成された文章の流暢さ・一貫性などを測る指標を用いてモデルの精度を検証します。かつて機械翻訳の評価で主流だったBLEUスコアのような単純な単語一致率だけでなく、近年ではBERTScoreなど文脈の類似性を測る指標や、タスク固有の正答率などを組み合わせます。 さらに、最終的には専門家による人間評価(A/Bテストや品質評価)を通じて、モデルの実用的な価値を多角的に判断することが不可欠です。 この学習と評価のサイクルを繰り返し、目標とする性能に達するまでモデルを改良していきます。
デプロイと運用・保守
目標性能に達したモデルは、実際のサービスで利用できるように「デプロイ」されます。これには、モデルをサーバーに配置し、APIを通じてアプリケーションから呼び出せるようにする作業が含まれます。
デプロイ後も開発は終わりではありません。ユーザーの利用状況を監視し、予期せぬエラーや性能の劣化が起きていないかを継続的にチェックする「運用・保守」フェーズに入ります。ユーザーからのフィードバックや新たに蓄積されたデータを基に、定期的にモデルを再学習させ、継続的に性能を改善していく(LLMOps)ことが、サービスの価値を維持・向上させる上で不可欠です。
https://media.a-x.inc/llm-implementation
LLM開発に必要なリソースとチーム構成
LLMの開発、特にゼロからの構築や大規模なファインチューニングを成功させるためには、高性能な計算資源、大規模データセット、そして専門知識を持つチームという3つの要素が不可欠です。これらのリソースを事前に確保し、適切な計画を立てることがプロジェクトの成否を分けます。リソースが不足している場合は、API活用など別のアプローチを検討する必要があります。
ここでは、具体的にどのようなリソースが必要で、どのようなスキルを持つ人材でチームを構成すべきかを解説します。
高性能な計算資源と大規模データセット
LLMの学習には、膨大な量の計算が要求されるため、NVIDIA社のH100や、次世代のBlackwellアーキテクチャを採用したB200といった最新の高性能GPU(Graphics Processing Unit)が多数必要になります。(出典:NVIDIA Blackwell プラットフォームが生成 AI のコンピューティング新時代を牽引)自社でこれらのサーバーを多数保有する「オンプレミス」環境を構築するか、AWS、Google Cloud、Microsoft Azureなどのクラウドサービスを利用するのが一般的です。クラウドサービスは、初期投資を抑え、必要に応じてリソースを柔軟に拡張できるメリットがあります。
また、モデルの性能を決定づける大規模で高品質なデータセットも欠かせません。データの量だけでなく、多様性や正確性も重要であり、場合によっては専門のデータベンダーから購入したり、自社でアノテーション(データへのタグ付け)作業を行ったりする必要も出てきます。
専門知識を持つ開発チームの構成
LLM開発プロジェクトを推進するためには、多様な専門性を持つメンバーで構成されたチームが必要です。一般的には、以下のような役割が考えられます。
- AIエンジニア/研究者:モデルのアーキテクチャ設計や学習アルゴリズムの開発を担当。
- データサイエンティスト:学習データの収集、分析、前処理を行い、データの品質を担保。
- MLOpsエンジニア:学習からデプロイ、運用までの一連のパイプラインを構築・自動化し、安定稼働を実現。
- プロジェクトマネージャー:全体の進捗、予算、リソースを管理し、プロジェクトを成功に導く。
- ドメイン専門家:開発対象となる業界や業務の専門知識を提供し、モデルの実用性を高める。
これらの役割は、プロジェクトの規模やフェーズによって兼任されることもあります。各分野の専門家が連携することで、より実用的で価値の高いLLMを開発できるのです。
https://media.a-x.inc/llm-engineer
法人向けAI研修
AX CAMP 無料資料
LLMの性能を最大化する重要技術
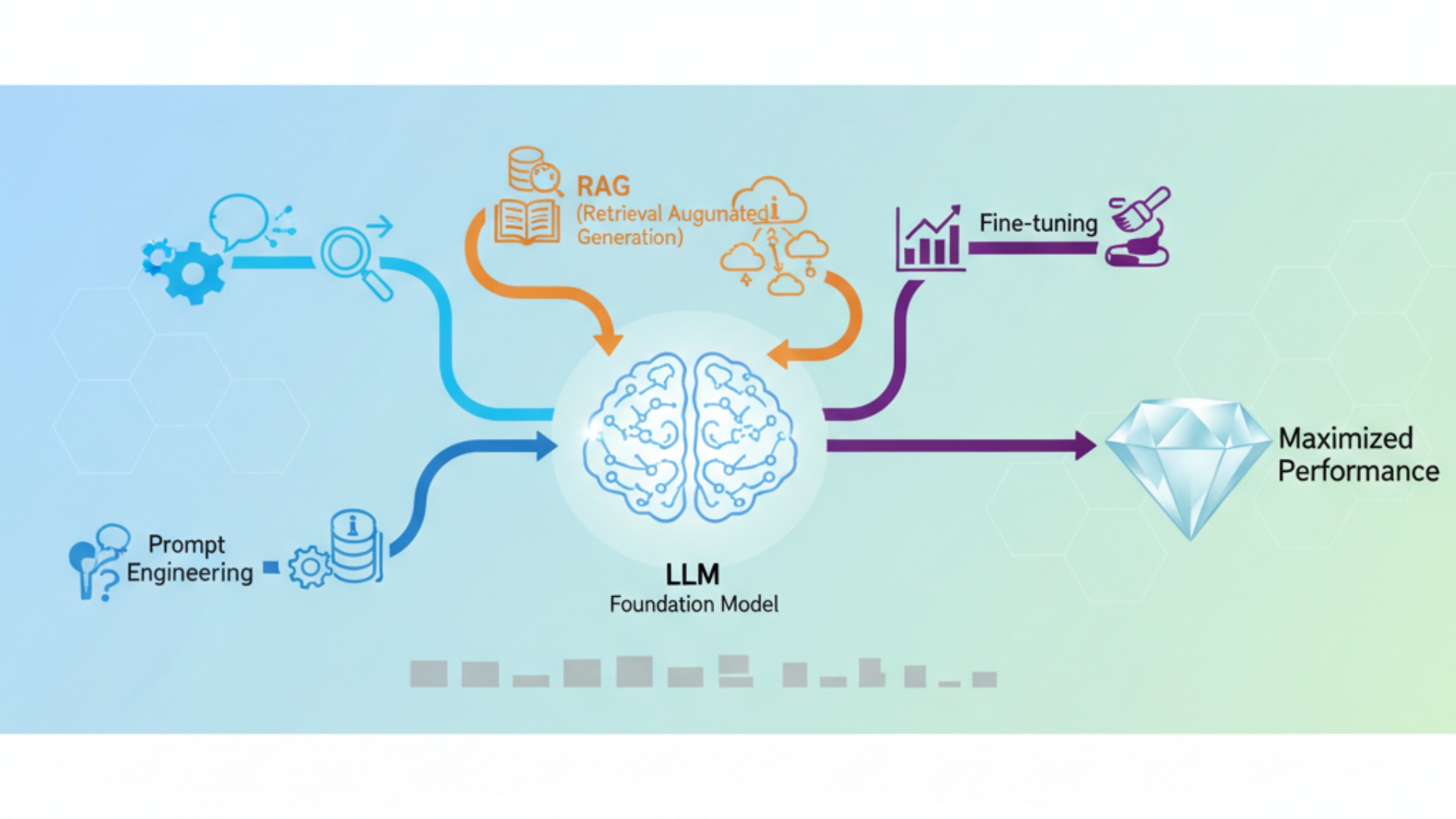
LLMの基盤モデルをそのまま利用するだけでなく、いくつかの重要な技術を組み合わせることで、その性能を飛躍的に向上させ、特定のタスクに最適化できます。特に「プロンプトエンジニアリング」「RAG(検索拡張生成)」「ファインチューニング」は、現代のLLM活用において必須とも言える技術です。これらの技術を理解し、適切に使い分けることが、LLMのポテンシャルを最大限に引き出す鍵となります。
ここでは、それぞれの技術がどのようなもので、どのように性能向上に寄与するのかを解説します。
プロンプトエンジニアリングとRAGによる精度向上
プロンプトエンジニアリングとは、LLMへの指示や質問(プロンプト)を工夫することで、より高品質で意図した通りの回答を引き出す技術です。例えば、「ステップバイステップで考えてください」といった一文を加えるだけで、複雑な問題に対する推論精度が向上することが知られています(Chain-of-Thought)。これは、モデル開発や追加学習なしで、すぐに実践できる非常にコストパフォーマンスの高い手法です。
RAG(Retrieval-Augmented Generation)は、LLMが回答を生成する際に、社内文書やデータベースといった外部の信頼できる情報源をリアルタイムで検索し、その内容を根拠として利用する仕組みです。これにより、LLMが学習していない最新の情報や、社外秘の専門知識に基づいた回答が可能になります。また、LLMが事実に基づかない情報を生成してしまう「ハルシネーション」の発生率を低減させる効果が期待でき、回答の信頼性を高める上で重要な技術です。ただし、RAGはハルシネーションを完全に排除するものではなく、検索した情報自体が誤っている可能性もあるため、根拠の提示と検証プロセスを組み合わせた運用が求められます。(出典:プロンプトエンジニアリングとは?コツや使えるテンプレートを紹介)

ファインチューニングによる特化
前述の通り、ファインチューニングは既存の基盤モデルに対して、特定のドメインやタスクに特化したデータを追加学習させることで、モデルの挙動をカスタマイズする技術です。例えば、法律相談用のチャットボットを開発する場合、過去の判例や法律文書を学習させることで、法律用語の正確な理解や、法律家のような堅い文体での回答生成が可能になります。プロンプトエンジニアリングやRAGだけでは対応が難しい、モデルの根本的な知識や応答スタイルそのものを特定の用途に「特化」させたい場合に非常に有効な手段です。
https://media.a-x.inc/llm-rag-finetuning
2026年最新の主要LLM基盤モデル5選

LLMの開発競争は熾烈を極めており、各社から次々と新しい高性能モデルがリリースされています。2025年現在、市場をリードしているのはOpenAI、Google、Anthropicなどの巨大テック企業が開発するモデル群です。どの基盤モデルを選択するかは、開発するアプリケーションの性能、コスト、そして特性を大きく左右します。(出典:【2026年最新】LLM(大規模言語モデル)比較!)ここでは、現在最も注目されている主要なLLM基盤モデルを5つ紹介し、その特徴を比較します。
| モデル名 | 開発元 | 特徴 |
|---|---|---|
| GPTシリーズ (GPT-5等) | OpenAI | 業界最高水準の総合性能を誇るモデル群。自然な対話、複雑な文章生成、高度な推論能力に優れ、多くのアプリケーションの基盤となっている。次世代モデルにも期待が集まる。 |
| Geminiシリーズ (Gemini 2.5 Pro等) | Googleの膨大なデータと検索技術が強み。特に長文の文脈理解能力や情報の正確性に定評がある。テキスト、画像、音声を統合的に扱うマルチモーダル対応も強力。 | |
| Claudeシリーズ (Claude Sonnet 4.5等) | Anthropic | 安全性と倫理性を重視した設計が特徴。長文の読解・要約能力が非常に高く、特に法務や金融など、信頼性が求められる分野での評価が高い。 |
| Llama 3 | Meta | Meta社が提供する、オープンウェイト(公開ウェイト)の高性能モデル。自社環境で自由にカスタマイズできる点が魅力。 |
| Command R+ | Cohere | ビジネスユースに特化し、特にRAGとの連携性能が高いモデル。信頼性の高い情報源に基づいた回答生成を得意とし、エンタープライズ向けの機能が豊富。 |
これらのモデルは、それぞれAPIを通じて利用できます。汎用性や創造性を求めるならGPTシリーズ、長文処理や信頼性を重視するならClaudeシリーズ、コストを抑えつつ自由にカスタマイズしたいならLlama 3など、用途に応じて最適なモデルを選択することが重要です。なお、Llama 3は利用に独自のライセンス条件があり、月間アクティブユーザー数が7億を超える場合は別途ライセンス申請が必要な点にご注意ください。
https://media.a-x.inc/ai-model
https://media.a-x.inc/llm-compare
法人向けAI研修
AX CAMP 無料資料
LLM開発における課題と今後の展望

LLM開発は技術的に大きな進歩を遂げましたが、依然としていくつかの重要な課題を抱えています。これらの課題を理解し、対策を講じることが、責任あるLLMの活用には不可欠です。一方で、これらの課題を克服するための研究も活発に進められており、LLMの未来は大きな可能性を秘めています。
ここでは、LLM開発が直面する主要な課題と、今後の技術的な展望について解説します。また、開発のハードルは高いものの、既存技術の応用によって大きな業務効率化を達成した事例も紹介します。
ハルシネーションと倫理的課題
LLMが直面する最も深刻な課題の一つが「ハルシネーション(Hallucination)」です。これは、モデルが事実に基づかない情報を、あたかも真実であるかのように堂々と生成してしまう現象を指します。(出典:AIの失敗事例7選!原因と対策を徹底解説)この問題は、特に医療や金融など、情報の正確性が極めて重要な分野で大きなリスクとなります。RAG(検索拡張生成)を含む様々な技術でハルシネーションを抑制する努力が進んでいますが、完全な解決には至っていません。
また、学習データに含まれるバイアスをモデルが再生産してしまう問題や、偽情報の拡散、プライバシー侵害といった倫理的な課題も指摘されています。開発者は、これらのリスクを最小化するための技術的・倫理的なガイドラインを遵守する必要があります。(出典:AI導入の課題とは?7つの壁と解決策を解説)
開発コストと専門人材の不足
高性能なLLMをゼロから開発するには、膨大な計算リソースとそれに伴う莫大な電力、そして多額の資金が必要です。このコストの問題が、LLM開発の参入障壁を高くしています。また、LLMの開発・運用には、AI、データサイエンス、MLOpsなど、複数の分野にまたがる高度な専門知識が求められますが、これらのスキルを持つ人材は世界的に不足しており、多くの企業にとって深刻な課題となっています。
グラシズ様の事例:AI活用による業務効率化
LLMの独自開発はハードルが高い一方、既存のAI技術を業務に応用するだけでも大きな成果が期待できます。Webコンサルティング事業を展開するグラシズ様では、AX CAMPで学んだプロンプトエンジニアリングを活用し、これまで外注していたLPライティング業務を内製化しました。その結果、1件あたり10万円かかっていた外注費を0円に削減し、制作時間も3営業日からわずか2時間へと大幅に短縮することに成功しました。(出典:【AX CAMP導入事例】LPライティング外注費10万円が0円に!プロンプト活用で制作時間も3営業日から2時間へ短縮したグラシズ社のAI活用術)
LLM開発・活用を加速させるならAX CAMP

LLMの開発やビジネスへの応用は、多くの企業にとって大きな挑戦です。「何から手をつければいいのかわからない」「自社に最適な開発アプローチが判断できない」「推進できる専門人材が社内にいない」といった課題は、プロジェクトを停滞させる大きな要因となります。
このような課題を解決し、LLM開発・活用の道のりを最短距離で進むために、AX CAMPは実践的な法人向けAI研修・伴走支援サービスを提供しています。単なる知識の提供に留まらず、貴社の具体的なビジネス課題に寄り添い、最適なLLMの選定から、ファインチューニングやRAGの実装、プロンプトエンジニアリングの最適化まで、実務に直結するスキル習得を徹底的にサポートします。(出典:AI開発におすすめのノーコードツール9選!)
AX CAMPの強みは、経験豊富な専門家による伴走支援です。研修で学んだ内容を実際の業務に適用する過程で生じる疑問や課題に対し、専属のコンサルタントが的確なアドバイスを提供します。これにより、研修で終わらせることなく、具体的な業務改善やサービス開発といった成果に繋げることが期待できます。自社だけで悩む時間をなくし、専門家と共にLLM活用の成功確率を高めませんか。ご興味のある方は、まずは無料の資料請求で詳細をご確認ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:自社に最適なLLM開発方法を見つけよう
本記事では、LLM開発の全体像を掴むために、その定義から3つの主要な開発アプローチ、具体的なフロー、そして最新の基盤モデルまでを網羅的に解説しました。(出典:LLM(大規模言語モデル)とは?開発の仕組みや課題、活用事例を解説)自社でLLMを開発・活用する上での重要なポイントを以下にまとめます。
- アプローチの選択:目的とリソースに応じて「API活用」「ファインチューニング」「ゼロから構築」の3つから最適な手法を選ぶ。
- 迅速な導入:最も早く低コストで始めるなら、外部APIの活用が第一候補となる。
- 独自性の確保:専門性や独自の応答スタイルが求められる場合は、ファインチューニングが効果的。
- 性能の最大化:プロンプトエンジニアリングやRAGといった技術を組み合わせることで、モデルの精度は飛躍的に向上する。
- 課題への理解:ハルシネーションやコストといった課題を認識し、対策を講じることが重要。
LLM開発は複雑で多くのリソースを要しますが、そのポテンシャルは計り知れません。自社の目的、予算、技術力を正確に評価し、最適なアプローチを選択することが成功への第一歩です。
もし、どの手法が自社に最適か判断に迷う場合や、開発を推進する人材が不足している場合は、専門家の支援を受けることが有効な選択肢となります。AX CAMPのような実践的な研修・伴走支援サービスを活用することで、プロジェクトの成功確度を高め、LLMがもたらすビジネス価値の最大化を支援します。まずは第一歩として、情報収集から始めてみてはいかがでしょうか。

法人向けAI研修
AX CAMP 無料資料