

自社に特化した大規模言語モデル(LLM)を開発したいけれど、何から手をつければ良いかわからない。そんな悩みを抱える企業は少なくありません。
「ファインチューニング」や「RAG」といった言葉は聞くものの、その違いや最適な手法の選び方でつまずいてしまうケースが多く見られます。コストを抑えつつ、自社のデータで高精度なAIを構築する鍵は「転移学習」にあります。
この記事では、LLMにおける転移学習の基本的な仕組みから、ファインチューニングなどの関連技術との違い、具体的な手法、ビジネスでの活用事例までを網羅的に解説します。最後まで読めば、自社専用AIモデルを構築するための具体的な道筋が見えるはずです。AI導入の具体的な進め方や、社内での活用人材育成に関心のある方は、AX CAMPが提供する資料もぜひ参考にしてください。
記事:【AI導入しないことが経営リスクになる時代】先行企業が手にした圧倒的な競争優位とは?
LLMの転移学習とは?その基本的な仕組み
LLMの転移学習とは、巨大なデータセットで事前にトレーニングされた「事前学習済みモデル」が持つ知識を、特定の専門分野や個別のタスクに適応させる技術です。これは、料理の初心者が一流シェフの完成されたレシピ(知識)を応用して、自分だけの新しい料理を作るプロセスに似ています。ゼロから膨大な知識を学習させる必要がないため、効率的に高性能なAIモデルを構築できるのです。
このアプローチにより、企業は自社が保有する比較的少量のデータを用いて、独自の課題解決に特化したAIを開発できるようになります。まさに、巨人の肩の上に立つことで、より遠くを見渡せるようになる技術と言えるでしょう。次のセクションでは、この転移学習がなぜ今注目されているのかを掘り下げていきます。
事前学習済みモデルが持つ汎用的な知識
転移学習の土台となるのが、GPTシリーズやGeminiといった「事前学習済みモデル」です。これらのモデルは、インターネット上の膨大なテキストや書籍、論文などのデータを学習しており、言語に関する非常に広範で汎用的な知識を獲得しています。文法や単語の意味はもちろん、一般的な事実の理解、文章の要約、翻訳、質疑応答といった多様な能力を備えている点が特徴です。(出典:Introducing GPT-5)
この汎用的な知識があるからこそ、私たちは少ない労力で特定の目的に合わせたカスタマイズが可能になります。いわば、あらゆる分野の基礎知識を網羅した「賢い脳」を借りてくるイメージであり、これが転移学習の出発点となります。
知識を特定のタスクへ「転移」させるプロセス
「転移」のプロセスでは、この汎用的な「賢い脳」に対して、特定のタスクに関連する専門データを追加で学習させます。例えば、法務分野に特化させたい場合、法律の条文や過去の判例データを学習させることで、モデルは法律に関する専門用語や特有の文脈を深く理解し、より正確な回答を生成できるようになります。
ただし、AIが生成する内容はあくまで参考情報であり、法的な助言ではありません。汎用モデルが持つ言語能力を維持しつつ、新たな専門知識を上乗せすることで、特定のドメインに最適化されたAIが完成しますが、最終的な判断には必ず弁護士などの専門家による確認が必要です。この仕組みを理解することが、適切なAI活用の第一歩です。

なぜ今LLMの転移学習が注目されるのか?

LLMの転移学習が注目される最大の理由は、AIモデルの開発コストと時間を劇的に削減しつつ、高い精度を実現できる点にあります。従来、高性能なAIを開発するには、莫大な計算資源と大規模なデータセット、そして専門的な知識を持つ人材が必要でした。しかし、転移学習の登場により、そのハードルは大きく下がりました。
特に、専門性が高くデータが限られる領域でもAI活用を可能にする点で、多くのビジネスから期待が寄せられています。これにより、AIの恩恵を受けられる企業の裾野が大きく広がり、新たなビジネスチャンスが生まれているのです。
開発コスト削減と少量データでの高精度化
LLMをゼロから事前学習させるには、数億円以上のコストと数ヶ月単位の時間が必要になることも珍しくありません。転移学習を活用すれば、この巨大な初期投資を回避できます。公開されている高性能な事前学習済みモデルを利用し、自社の持つ比較的少量の専門データで追加学習を行うだけで、実用的なレベルのAIを構築可能です。
この利点により、これまでAI開発をためらっていた中小企業や特定の部門でも、独自のAIモデルを持つことが現実的な選択肢となりました。まさに、AIの民主化を加速させる重要な技術と言えるでしょう。
特定ドメインへの柔軟な適応力
転移学習のもう一つの大きな魅力は、その柔軟性の高さにあります。医療、金融、法務、製造業など、各業界には特有の専門用語や知識、文脈が存在します。汎用的なLLMでは、これらの専門的な内容を正確に扱うことが難しい場合が少なくありません。
転移学習を用いれば、業界特有のドキュメントやデータを学習させることで、モデルをそのドメインに最適化できます。結果として、専門家の業務をサポートする高精度な文書作成、要約、分析ツールなどを開発できるようになり、ビジネスの競争力を直接的に高めることが可能です。 特に医療データのように機微な個人情報を取り扱う際は、個人情報保護法や医療情報のガイドラインを遵守し、厳格な手続きが求められます。

法人向けAI研修
AX CAMP 無料資料
転移学習と関連技術との違いを整理
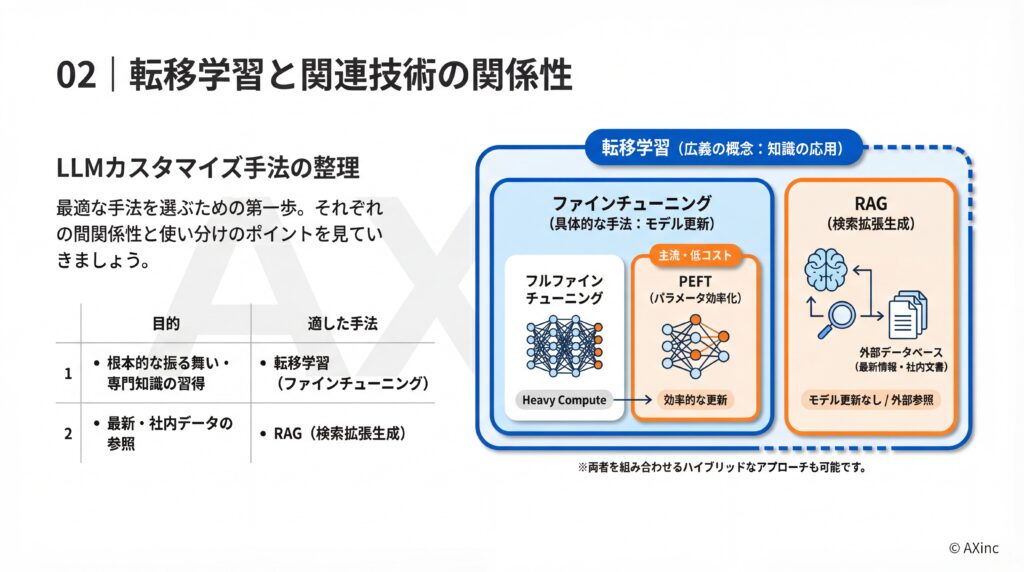
LLMのカスタマイズを検討する際、「転移学習」「ファインチューニング」「RAG」「PEFT」といった用語が登場します。これらの技術は密接に関連していますが、その目的とアプローチには明確な違いがあります。自社の課題や保有データ、予算に応じて最適な手法を選択することが重要です。
ここでは、それぞれの技術がどのような関係性にあり、どのように使い分けるべきかを整理して解説します。この違いを理解することが、適切な技術選定の第一歩です。
ファインチューニングとの関係性
結論から言うと、転移学習は広範な概念であり、ファインチューニングはその具体的な手法の一つです。 転移学習は「事前学習で得た知識を別のタスクに役立てる」という考え方そのものを指します。一方で、ファインチューニングは、その転移学習を実現するための代表的なアプローチを指します。
具体的には、ファインチューニングとはベースモデルの重み(パラメータ)の全体または一部を、新しい専門データで更新するプロセスです。 このプロセスは、更新する範囲によって「フルファインチューニング」と、後述する「PEFT(パラメータ効率的ファインチューニング)」に大別されます。
RAG(検索拡張生成)との使い分け
RAG(Retrieval-Augmented Generation)は、モデルの知識を直接更新するのではなく、外部のデータベースから関連情報を検索し、その情報を基に回答を生成する技術です。モデルの知識は固定されたままで、常に最新の情報や社内の特定ドキュメントを参照して回答させたい場合に有効な手法となります。
使い分けのポイントは、モデルに何を学ばせたいかによって決まります。
- 転移学習(ファインチューニング):モデルの根本的な知識や振る舞い(文体、応答スタイル、専門知識)を特定のドメインに適合させたい場合に適しています。
- RAG:最新情報や頻繁に更新される情報(製品マニュアル、FAQ、今日のニュースなど)に基づいて回答を生成させたい場合に適しています。
両者を組み合わせて、モデルの基礎能力を転移学習で高めつつ、RAGで最新情報に対応させるハイブリッドなアプローチも可能です。

PEFT(パラメータ効率的ファインチューニング)との関連
PEFT(Parameter-Efficient Fine-Tuning)は、ファインチューニングをより低コストかつ効率的に行うための技術群の総称です。 従来のファインチューニング(フルファインチューニング)では、モデルの全てのパラメータ(数千億個にもなる)を更新するため、膨大な計算資源が必要でした。
PEFTは、モデルのごく一部のパラメータのみを更新、または追加の小さなパラメータを学習させることで、計算コストを大幅に削減します。 LoRA(Low-Rank Adaptation)などが代表的な手法で、少ない計算資源でもフルファインチューニングに近い性能を達成できるため、近年の主流となっています。 つまり、PEFTは転移学習をより手軽に実現するための重要な選択肢と言えるのです。
LLMにおける転移学習の主要な手法
LLMの転移学習を実現するには、いくつかの具体的なアプローチが存在します。どの手法を選択するかは、目的とするタスクの複雑さ、利用可能なデータ量、そして計算資源(コスト)によって決まります。代表的な手法として、「特徴抽出」「フルファインチューニング」、そして近年注目される「PEFT」の3つが挙げられます。
それぞれのメリット・デメリットを理解し、プロジェクトの要件に最適な手法を選ぶことが成功の鍵となります。
特徴抽出(Feature Extraction)
特徴抽出は、事前学習済みモデルのパラメータを一切変更せず、固定した状態で利用する手法です。モデルにテキストを入力し、その中間層から得られる出力(特徴量)を、別の新しい小規模なモデル(分類器など)の学習に利用します。例えば、文章がポジティブかネガティブかを判定する感情分析タスクなどで用いられます。(出典:New and improved embedding model)
この手法の最大のメリットは、計算コストが非常に低い点です。事前学習済みモデルの再学習が不要なため、迅速に試すことができます。ただし、モデル自体の知識は更新されないため、タスクへの適応能力には限界があることも理解しておく必要があります。
フルファインチューニング(Full Fine-Tuning)
フルファインチューニングは、事前学習済みモデルの全ての層のパラメータを、新しいデータセットで再学習させる手法です。モデル全体をターゲットタスクに最適化するため、最も高い性能が期待できます。モデルの応答スタイルや専門知識を根本的に変化させたい場合に適しています。
一方で、全てのパラメータを更新するため、膨大な計算資源と時間が必要です。業務で利用する際は、モデルの挙動をテスト・検証するフェーズを設け、導入後も継続的な監視や人的レビュー、インシデント発生時の対応フローを整備するなど、厳格な安全管理体制が不可欠です。
パラメータ効率的な手法(PEFT)の活用
前述の通り、PEFTはフルファインチューニングの性能を、より低いコストで実現することを目指した手法群です。代表的な手法であるLoRAでは、既存のパラメータは凍結したまま、ごく少数の新しいパラメータ(アダプタ)を追加し、その部分だけを学習させます。ある研究では、訓練可能なパラメータ数を減らし、GPUメモリ要件を大幅に削減したと報告されています。(出典:NVIDIA TensorRT-LLM を使用した LoRA LLM のチューニングと展開)
PEFTは、コストと性能のバランスに優れているため、多くのビジネスシーンで現実的な選択肢となります。計算コストを大幅に削減できることが期待されますが、実際の削減率はベースモデルやタスクの条件に依存するため、事前の検証が重要です。

法人向けAI研修
AX CAMP 無料資料
LLMの転移学習におけるモデル選定のポイント

転移学習の成功は、土台となる「ベースモデル」の選定に大きく左右されます。数多くのLLMの中から、自社の目的や要件に合致したモデルをいかに選ぶか。重要な判断基準は「ベースモデルの性能とライセンス」と「ターゲットタスクとの類似性」の2点です。
これらのポイントを慎重に検討することで、後のファインチューニング作業を効率化し、より高い成果を得ることができます。
ベースモデルの性能とライセンス
まず考慮すべきは、ベースモデルが持つ基本的な性能とライセンスです。GPTシリーズなどのクローズドモデルは高性能ですが、API利用が基本で規約の制約があります。 一方で、Llama 3などのオープンソースモデルは、カスタマイズの自由度が高いという利点があります。(出典:llama.com)
ただし、モデルごとにライセンスが異なり、商用利用の可否や条件が厳密に定められています。 商用利用を検討している場合は、Apache 2.0やMITライセンスなど、ビジネスでの利用が許可されているモデルを選ぶ必要があります。 また、学習データに由来する著作権リスクも考慮しなくてはなりません。ライセンスの解釈やリスク評価については、弁護士など法務の専門家に確認することを強く推奨します。(出典:Apache License 2.0)

ターゲットタスクとの類似性
ベースモデルがどのようなデータで事前学習されたかは、転移学習の効率に影響します。例えば、ターゲットタスクがプログラムコードの生成である場合、一般的な対話データで学習したモデルよりも、GitHubなどのコードデータで学習したモデル(例:Code Llama)をベースにする方が、より少ないデータで高い性能を達成できる可能性が高いです。
同様に、医療分野の文書を扱うなら医学論文で学習したモデル、金融分野なら経済レポートで学習したモデルを選ぶなど、ターゲットタスクと事前学習データのドメインが近いほど、知識の転移がスムーズに進みます。モデル選定の段階で、この類似性を考慮することがプロジェクト成功の確度を高めます。
LLMの転移学習を成功させるための注意点
LLMの転移学習は強力な手法ですが、その導入と運用には注意すべき点が存在します。特に、技術的なリスクへの対策と、倫理的な側面への配慮は不可欠です。これらの注意点を事前に理解し、適切な対策を講じることで、予期せぬトラブルを回避し、プロジェクトを成功に導くことができます。
ここでは、代表的なリスクとその対策について解説します。
技術的リスク(破滅的忘却・過学習)と対策
転移学習において注意すべき技術的リスクとして、「破滅的忘却」と「過学習」が挙げられます。
- 破滅的忘却:新しいタスクの学習に集中するあまり、ベースモデルが元々持っていた汎用的な知識を忘れてしまう現象です。
- 過学習:追加学習で用いた少量のデータに過剰に適合してしまい、未知のデータに対する予測精度が低下する現象を指します。
これらのリスクを軽減するためには、学習率を適切に調整する、正則化と呼ばれる手法で学習を安定させる、あるいは過去のタスクと新しいタスクを同時に学習させるといった対策が有効です。 専門的な知識が求められる部分であり、慎重なチューニングが必要となります。
倫理的配慮とバイアスの転移
もう一つ重要な注意点が、倫理的な問題です。ベースモデルは、インターネット上の膨大なデータを学習していますが、そのデータには社会的な偏見や差別的な表現といったバイアスが含まれている可能性があります。転移学習を行う際、これらのバイアスが意図せず引き継がれ、特定のタスクで増幅されてしまう危険性があります。
対策としては、追加学習に用いるデータセットの偏りをなくす努力をするとともに、モデルの出力を継続的に監視し、問題のある挙動が見られた場合には速やかに修正する体制を整えることが重要です。特に個人情報を含むデータを扱う際は、個人情報保護法などの関連法令を遵守しなくてはなりません。
LLM開発・活用を加速させるならAX CAMP

LLMの転移学習は、自社専用AIを構築するための強力なアプローチですが、その実践にはモデル選定、データ準備、チューニング、リスク管理といった専門的な知識とスキルが求められます。「何から手をつければ良いかわからない」「社内に専門家がいない」といった課題に直面することも少なくありません。
自社のビジネス課題解決に向けて、最短距離でAI活用を進めたいとお考えなら、法人向けAI研修・伴走支援サービス「AX CAMP」がその道のりをサポートします。AX CAMPは、単なる知識の提供に留まりません。貴社の課題に合わせたカスタマイズ研修、手を動かしながら学ぶハンズオン形式、そして研修後も安心の継続的サポートを通じて、実務で成果を出すためのスキル習得を徹底的に支援します。
経験豊富な専門家が伴走し、技術的な疑問からビジネスへの応用まで、あらゆる相談に対応します。机上の空論で終わらない、成果に直結するAI活用を実現するために、まずは無料の資料請求や個別相談会で、AX CAMPがどのように貴社のAI導入を加速できるかをご確認ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMの転移学習で自社専用AIモデルの構築を
本記事では、LLMの転移学習について、その基本的な仕組みから関連技術との違い、具体的な手法、ビジネス活用事例、そして成功のための注意点までを網羅的に解説しました。改めて、重要なポイントを振り返ります。
- 転移学習は事前学習モデルの知識を応用する技術
- 開発コストを抑え少量データで高精度化が可能
- ファインチューニングやRAGとは目的別に使い分ける
- モデル選定とリスク対策が成功の鍵を握る
転移学習を正しく理解し活用することで、これまで技術やコストの壁で諦めていた「自社専用AI」の構築が現実的な選択肢となります。社内の問い合わせ対応、専門文書の処理、高精度な需要予測など、その応用範囲は広く、ビジネスに大きな変革をもたらすポテンシャルを秘めています。
もし、この記事を読んで「自社でも転移学習に挑戦してみたいが、具体的な進め方がわからない」と感じたなら、ぜひAX CAMPにご相談ください。専門的な支援を通じて、記事で紹介したようなAI施策を確実に実現し、貴社の業務効率化と新たな価値創造を強力にサポートします。

法人向けAI研修
AX CAMP 無料資料