

「自社の専門知識を反映したAIを構築したいが、何から手をつければいいかわからない」
「ChatGPTの回答は一般的すぎて、そのままでは業務に活用しきれない」といった課題を抱えていませんか。その解決策は、LLM(大規模言語モデル)に自社独自のデータを学習させることにあります。汎用的なAIを、自社の業務や文脈を深く理解した「専門家」へと進化させることが可能です。
この記事では、LLMに自社データを学習させるための主要な手法から、具体的な5つのステップ、コスト感、そして注意すべきリスクまでを網羅的に解説します。最後まで読むことで、自社に最適なAIを構築し、ビジネスを加速させるための具体的な道筋が見えるはずです。AI活用のためのより詳しい情報や、他社の導入事例をまとめた資料もご用意しておりますので、ぜひご活用ください。

法人向けAI研修
AX CAMP 無料資料
LLMにデータを学習させる目的とメリット
LLMに自社データを学習させる最大の目的は、汎用的なAIを「自社専用の専門家」へと進化させることです。これにより、社内ナレッジの活用、顧客対応の質の向上、業務プロセスの自動化など多岐にわたるメリットが生まれます。適切に実装すれば、企業の競争力を飛躍的に高めることが期待できるでしょう。
特定ドメインへの特化と専門性の向上
汎用のLLMは広範な知識を持っていますが、特定の業界や企業に特有の専門用語、独自のノウハウ、社内ルールまでは網羅していません。そこで、社内マニュアル、過去のプロジェクト資料、顧客との応対履歴といった独自のデータを学習させることで、LLMは特定のドメイン(領域)に特化した知識を獲得します。
この特化により、専門的な問い合わせに対して、まるで社内のベテラン社員のように的確で文脈に沿った回答を生成できるようになります。結果として、従業員が情報を探す時間が大幅に短縮され、業務の生産性向上に直結するのです。
企業独自の応答スタイルやブランドボイスの実現
顧客とのコミュニケーションにおいて、企業独自のトーン&マナーやブランドイメージを維持することは非常に重要です。LLMに過去のプレスリリース、マーケティング資料、カスタマーサポートの優れた応対記録などを学習させることで、その企業らしい応答スタイルを再現できます。
例えば、丁寧で親しみやすい言葉遣いを徹底したり、常に企業のビジョンを反映した回答を生成したりすることが可能になります。これにより、AIチャットボットやメール自動作成ツールなどを活用しても、一貫したブランド体験を顧客に提供できるようになり、顧客満足度の向上にも繋がります。
最新情報への追随と知識の陳腐化防止
市場環境や社内ルールは常に変化しており、LLMが持つ知識も時間とともに古くなっていきます。自社データを継続的に学習させる仕組みを構築することで、LLMは常に最新の製品情報、業務フロー、法令改正などを反映した回答を生成し続けることが可能です。
これにより、従業員が古い情報に基づいて誤った判断を下すリスクを防ぎ、組織全体の意思決定の質を担保します。特に、情報の鮮度が重要となる金融や法務といった分野において、このメリットは計りれない価値を持つでしょう。

LLM学習の具体的なユースケースと成功事例
では、実際にLLMに自社データを学習させると、どのようなことが可能になるのでしょうか。ここでは、LLM学習の具体的なユースケースと、それによってもたらされた成功事例をいくつかご紹介します。
- 社内向けAIヘルプデスク: 膨大な社内規定や業務マニュアルを学習させることで、従業員からの人事・経理・IT関連の質問に24時間365日即座に回答。ある企業では、このシステム導入により、バックオフィス部門への問い合わせ件数を60%削減しました。
- 高精度な顧客対応チャットボット: 過去の問い合わせ履歴や製品情報を学習させ、顧客の複雑な質問にも文脈を理解して的確に回答。大手ECサイトの成功事例では、AIチャットボットの自己解決率が40%から75%に向上し、顧客満足度とオペレーターの業務効率が大幅に改善されました。
- 専門文書の作成・レビュー支援: 契約書や技術仕様書、研究論文などの専門知識を学習させ、文書のドラフト作成やレビューを自動化。法務部門や開発部門の担当者が、より創造的な業務に集中できる環境を構築します。
これらの成功事例が示すように、自社データを取り込むことでAIは汎用的なアシスタントから、特定の業務領域における頼れる「専門家」へと進化します。これにより、これまで人手に頼っていた多くの業務が自動化・高度化され、企業の競争優位性の源泉となり得るのです。
LLMの主要な学習手法を比較解説
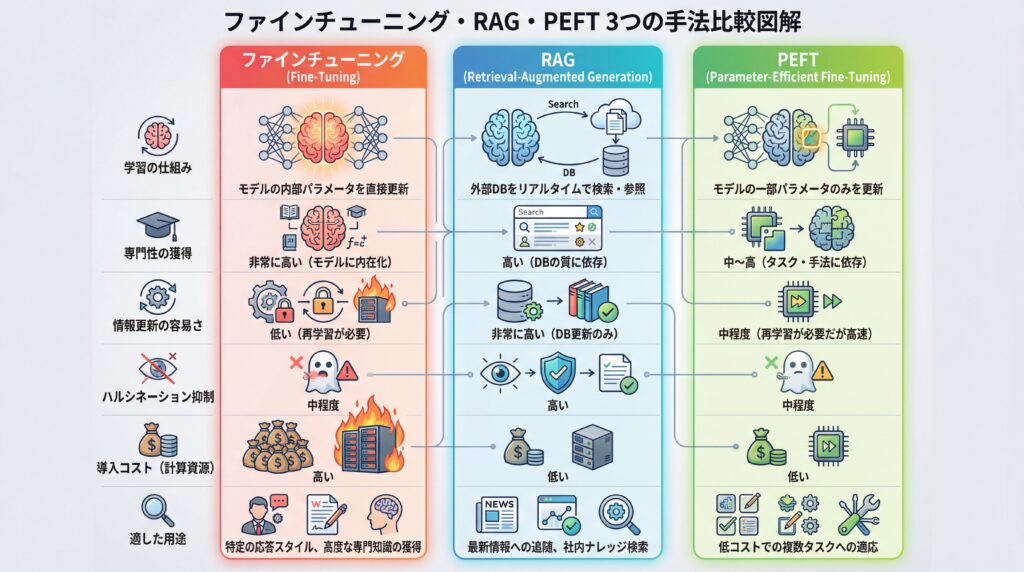
| 比較項目 | ファインチューニング | RAG | PEFT |
|---|---|---|---|
| 学習の仕組み | モデルの内部パラメータを直接更新 | 外部DBをリアルタイムで検索・参照 | モデルの一部パラメータのみを更新 |
| 専門性の獲得 | 非常に高い(モデルに内在化) | 高い(DBの質に依存) | 中〜高(タスク・手法に依存) |
| 情報更新の容易さ | 低い(再学習が必要) | 非常に高い(DB更新のみ) | 中程度(再学習が必要だが高速) |
| ハルシネーション抑制 | 中程度 | 高い | 中程度 |
| 導入コスト(計算資源) | 高い | 低い | 低い |
| 適した用途 | 特定の応答スタイル、高度な専門知識の獲得 | 最新情報への追随、社内ナレッジ検索 | 低コストでの複数タスクへの適応 |
LLMの主要な学習手法には「ファインチューニング」「RAG(Retrieval-Augmented Generation)」「PEFT(Parameter-Efficient Fine-Tuning)」の3つがあります。これらの手法はそれぞれ特性が異なり、目的、コスト、求める精度に応じて最適なものを選択することが成功の鍵です。一つの手法に固執せず、場合によってはこれらを組み合わせるハイブリッドなアプローチも有効と言えます。
ファインチューニング(Fine-tuning)
ファインチューニングは、既存の事前学習済みモデルに対し、特定のタスクやドメインに特化した小規模なデータセットを追加で学習させる手法です。このプロセスにより、モデルの内部パラメータが調整され、特定の応答スタイルや専門知識を「内在化」させることができます。例えば、法律相談に特化したAIを開発する場合、法律関連のQ&Aデータを学習させることで、法律用語や特有の論理展開を習得させることが可能です。
高い精度と特定のスタイル獲得が期待できる一方で、比較的大量の高品質な学習データが必要であり、学習プロセスには相応の計算コストと時間がかかる点がデメリットと言えます。
RAG(Retrieval-Augmented Generation)
RAGは、LLMに知識を直接学習させるのではなく、質問が来たタイミングで外部のデータベースから関連情報を検索(Retrieval)し、その情報を基に回答を生成(Generation)させる手法です。例えば、社内規定に関する質問があった場合、RAGシステムはまず社内規定データベースを検索し、該当する箇所を特定します。そして、その内容をLLMに提示し、「この情報に基づいて回答してください」と指示する仕組みです。
この手法の最大のメリットは、情報の更新が容易である点と、LLMが事実に基づかない情報を生成する「ハルシネーション」を抑制しやすい点です。データベースを更新するだけでLLMの知識を最新に保てるため、頻繁に情報が変わる業務に適しています。ファインチューニングに比べて導入コストが低い傾向にありますが、検索システムの精度が回答の質を大きく左右します。
PEFT(Parameter-Efficient Fine-Tuning)
PEFTは、ファインチューニングの一種ですが、モデルの全パラメータではなく、ごく一部のパラメータのみを更新することで、計算コストを大幅に削減する手法群の総称です。LoRA(Low-Rank Adaptation)などが代表的な手法として知られています。
PEFTは、少ない計算リソースと短い時間でモデルを特定のタスクに適応させることができるため、特にリソースが限られている場合や、複数の異なるタスクに対応するモデルを効率的に開発したい場合に非常に有効です。フルファインチューニングに近い性能を低コストで実現できる可能性がある一方で、タスクの複雑さによってはフルファインチューニングほどの精度が出ない場合もあります。



ファインチューニングとRAG(Retrieval-Augmented Generation)の使い分け
LLMを特定の目的に合わせてカスタマイズする際、特に代表的な「ファインチューニング」と「RAG(Retrieval-Augmented Generation)」のどちらを選ぶべきか、という問題は多くの開発者が直面します。この使い分けを判断する最もシンプルな考え方は、「モデルの振る舞い(スタイル)を変えたい」のか、「モデルが参照する知識(データ)を拡張・最新化したい」のかという視点です。
- ファインチューニングが適しているケース: モデル自体に特定の口調や思考プロセスを「内在化」させたい場合に有効です。例えば、「特定のキャラクターのような砕けた口調で返答するチャットボット」や、「法律専門家のような論理的な文章を生成するAI」の開発に向いています。
- RAGが適しているケース: 最新の情報や、社内文書のような限定的なデータソースに基づいて正確な回答を生成させたい場合に最適です。昨日更新された社内規定に関する質問への回答や、刻々と変わる市場データに基づいた分析レポートの生成などで効果を発揮し、LLMの弱点であるハルシネーション(事実に基づかない情報の生成)を抑制する効果も期待できます。
端的に言えば、ファインチューニングは「LLMそのものの能力を鍛え直す」アプローチ、RAGは「LLMに最新・正確なカンニングペーパーを持たせる」アプローチと言えるでしょう。この基本的な使い分けを理解することが、効果的なLLMアプリケーション開発の第一歩となります。
LLM学習の基本プロセス【5ステップで解説】

LLMの学習は、思いつきで始められるものではなく、計画的かつ体系的なアプローチが不可欠です。成功の確度を高めるためには、目的設定からデプロイ後の運用までを見通した5つのステップを踏むことが重要です。このプロセスを丁寧に進めることで、手戻りを防ぎ、投資対効果の高いモデル開発を実現できます。
1. 目的設定とベースモデルの選定
最初のステップは、LLMを学習させて「何を達成したいのか」を具体的に定義することです。例えば、「カスタマーサポートの一次対応を自動化し、応答時間を80%削減する」「法務部門の契約書レビュー業務を支援し、確認作業を50%効率化する」のように、定量的で明確な目標を設定します。(出典:契約書チェックにおけるAI活用のためのガイドラインとは | Hakky Handbook)
目的が明確になったら、その土台となるベースモデルを選定します。OpenAIのGPT-5、GoogleのGemini 2.5 Pro、AnthropicのClaude Opus 4.1など、各モデルには得意なタスクや性能、コストに違いがあります。(出典:Introducing the next generation of Claude)目的達成に最も適した性能を持ち、予算内で利用できるモデルを選ぶことが重要です。
2. 学習データの収集と前処理
モデルの性能を決定づける最も重要なステップが、学習データの準備です。社内に散在するマニュアル、FAQ、議事録、メール、チャット履歴など、目的に関連するあらゆるデータを収集します。収集したデータは、そのままでは使えないことがほとんどです。
そのため、「前処理」と呼ばれる作業が必要になります。個人情報や機密情報のマスキング、表記揺れの統一、誤字脱字の修正、不要な情報の削除といったデータクレンジングを行い、モデルが学習しやすい形式に整えます。この工程の質が、最終的なAIの精度を大きく左右します。
3. 学習環境の構築と実行
データの準備ができたら、次にモデルを学習させるための環境を構築します。これには、高性能なGPU(Graphics Processing Unit)を備えたコンピューティングリソースが必要です。自社でサーバーを用意するオンプレミス環境か、AWS、Google Cloud、Microsoft Azureなどのクラウドサービスを利用する方法があります。
近年では、クラウドサービスを利用する方が初期投資を抑えられ、必要に応じてリソースを柔軟に拡張できるため一般的です。環境が整ったら、前処理済みのデータを使って、選定した手法(ファインチューニングやPEFTなど)で学習を実行します。
4. モデルの評価と精度検証
学習が完了したモデルが、本当に目的を達成できる性能を持っているかを確認するステップです。事前に用意しておいた「評価用データセット」(学習には使っていない未知のデータ)を使って、モデルの回答精度、応答速度、堅牢性などを多角的に評価します。
評価結果が設定した目標に満たない場合は、学習データを見直したり、モデルのパラメータ(ハイパーパラメータ)を調整したりして、再度学習と評価を繰り返します。この試行錯誤のサイクルを回すことで、モデルの性能を目標レベルまで引き上げていきます。
5. デプロイと継続的なモニタリング
モデルの性能が目標を達成したら、いよいよ実業務で利用できるようにシステムに組み込み(デプロイ)ます。例えば、社内チャットボットとして公開したり、既存の業務アプリケーションとAPI連携させたりします。
しかし、デプロイして終わりではありません。実際にユーザーがどのように利用しているか、どのような質問でうまく答えられていないかを継続的にモニタリングし、定期的にデータを追加して再学習させることが重要です。この継続的な改善サイクルを回すことで、LLMは常にビジネス価値を生み出し続ける存在となります。


高精度な学習を実現するデータ準備のポイント

高精度なLLMを学習させる上で最も重要な要素は、「質の高い学習データ」を「十分な量」準備することです。モデルの性能は、学習データの品質によってほぼ決まると言っても過言ではありません。「ゴミを入れればゴミが出てくる(Garbage In, Garbage Out)」という原則は、LLMの学習においても同様です。以下のポイントを押さえることで、モデルの能力を最大限に引き出すことができます。(出典:LLMのファインチューニングにおけるデータ作成の勘所)
まず、データの網羅性と多様性を確保することが不可欠です。モデルに対応させたい業務範囲や質問パターンをできるだけ広くカバーするデータを集めましょう。成功事例だけでなく、失敗事例や例外的なケースに関するデータも含めることで、モデルはより複雑な状況判断能力を身につけることができます。
次に、データの一貫性と正確性が求められます。特にファインチューニングを行う場合、表記揺れ(例:「Web」「ウェブ」)や専門用語の使い方が統一されていることが重要です。また、データに含まれる情報が事実として正確であることは大前提です。誤った情報を学習させると、モデルが自信を持って嘘をつく(ハルシネーション)原因となります。
さらに、データのクリーニングとフォーマットの整理も欠かせません。個人情報や企業の機密情報は、PマークやISO27001に準拠した匿名加工処理を施すなど、厳格な管理が求められます。具体的には、データの最小化、アクセス制御、ログ管理といった措置を講じる必要があります。また、モデルが効率的に学習できるよう、データをJSONL形式の対話フォーマットに整形する作業も重要です。

LLM学習におすすめのモデルとプラットフォーム4選

LLMの学習には、用途や開発スキル、予算に応じて適切なモデルとプラットフォームを選ぶことが成功の鍵となります。現在、主要なクラウドプロバイダーがそれぞれ特色あるプラットフォームを提供しており、最新かつ高性能なモデルを手軽に利用できる環境が整っています。ここでは、代表的な4つの選択肢を紹介します。※各モデルの名称やバージョンは記事執筆時点のものであり、将来変更される可能性があります。
1. OpenAI API(GPTシリーズ)
ChatGPTで知られるOpenAIが提供するAPIは、LLM活用のデファクトスタンダードと言える存在です。GPT-5をはじめとする高性能なモデルを、API経由で手軽に利用できます。特にファインチューニング機能が充実しており、比較的少ない手順で自社データに適応させたカスタムモデルを作成できます。ただし、API利用時のデータ処理ポリシー(学習への使用可否、オプトアウト方法、データ保管場所)は、契約前に必ず確認することが極めて重要です。
2. Google Cloud Vertex AI
Google Cloudが提供する統合AIプラットフォームがVertex AIです。Googleが開発した高性能モデル「Gemini 2.5 Pro」などを利用できます。 データの前処理からモデルの学習、評価、デプロイまで、AI開発に必要なツールが一気通貫で提供されているのが特徴です。BigQueryなどのGoogle Cloudの他のサービスとの連携もスムーズで、大規模なデータを活用した本格的なモデル開発に適しています。
3. Amazon Bedrock
Amazon Bedrockは、Amazon Web Services(AWS)が提供するフルマネージドサービスで、複数のAI企業の高性能な基盤モデルを単一のAPIで利用できるのが最大の特徴です。Anthropic社の「Claude Opus 4.1」やAmazon自身の「Titan」といった複数の高性能モデルを、単一の統合環境から選択できる点が強みです。(出典:Amazon Bedrock でサポートされている基盤モデル)既存のAWS環境との親和性が高く、セキュリティや運用管理の面でAWSの豊富なサービスを活用できるため、エンタープライズでの利用に適しています。
4. Hugging Face
Hugging Faceは、AIモデルやデータセットの共有プラットフォームとして、世界中の開発者に利用されています。特にオープンソースのLLMを扱う上で中心的な存在であり、数万もの事前学習済みモデルが公開されています。(出典:Inference with Community models)利用する際は、各モデルのライセンスを必ず確認し、商用利用の可否や条件を遵守することが不可欠です。Transformersライブラリを使えば、様々なモデルをダウンロードし、自社の環境で自由にファインチューニングを行えます。
https://media.a-x.inc/ai-model
https://media.a-x.inc/llm-open-source
LLM学習にかかるコストと期間の目安

LLMの学習にかかるコストと期間は、プロジェクトの目的や規模、選択する手法によって大きく変動します。ゼロからモデルを事前学習する場合、その規模や要件に大きく依存しますが、一般的には数千万円から数億円以上のコストと数ヶ月の期間が必要とされるケースも珍しくありません。(出典:LLMのコスト構造とビジネス活用のための費用対効果分析 | 東京大学松尾研究室)
コストの主な内訳は、人件費、インフラ利用料(クラウド費用など)、API利用料の3つです。コスト感はプロジェクトの要件で大きく変動しますが、目安として以下のように整理できます。
- 小規模なPoC(概念実証):数十万円~数百万円(クラウドAPI利用、小規模なPEFT/RAG構築など)
- 本格的なシステム開発:数百万円~数千万円(フルファインチューニング、大規模なRAGシステム構築など)
- オンプレミスでの独自モデル導入:数千万円以上
(出典:生成AIを開発する料金相場は?開発費用を抑える方法や注意点を徹底解説 | WEEL)これらは開発初期費用であり、運用・保守コストが別途発生する点も考慮が必要です。期間については、データ準備に数週間から数ヶ月、モデル学習と評価・調整に数週間を要するため、小規模でも最低1〜2ヶ月、大規模なものでは半年以上を見込むのが現実的です。
LLMを学習させる際の注意点とリスク管理

LLMに自社データを学習させることは大きなメリットをもたらす一方で、いくつかの重要な注意点とリスクが伴います。これらのリスクを事前に理解し、適切な対策を講じなければ、情報漏洩や著作権侵害といった重大な問題に発展しかねません。安全な活用のためには、技術的な対策と組織的なルール整備の両輪が不可欠です。
最も注意すべきは、情報漏洩のリスクです。学習データに個人情報や顧客の機密情報が含まれていると、モデルが意図せずそれらの情報を回答として生成してしまう可能性があります。これを防ぐためには、データの前処理段階で個人情報などを厳格に匿名化・マスキングすることが絶対条件です。また、OpenAI APIなどの外部サービスを利用する際は、入力データがモデルの再学習に使われない設定(オプトアウト)になっているか、利用規約を必ず確認する必要があります。
次に、著作権や法的なリスクも考慮しなければなりません。学習データに著作権で保護されたコンテンツが含まれている場合、生成物が著作権侵害にあたる可能性が指摘されています。社内文書であっても、他社から提供された資料などが含まれていないか、データの出所を明確にし、利用許諾を確認することが重要です。(出典:契約書チェックにおけるAI活用のためのガイドラインとは | Hakky Handbook)また、業界によっては特定の規制やガイドラインが存在する場合があるため、法務部門と連携してコンプライアンスを確保する必要があります。
さらに、ハルシネーション(もっともらしい嘘の情報を生成する現象)のリスクも無視できません。自社データを学習させても、モデルが情報を誤って解釈したり、知識の隙間を不正確な推測で埋めたりすることがあります。これを完全に防ぐことは困難ですが、RAGを導入して回答の根拠を明示させる、あるいは生成された内容を人間が最終確認するワークフローを組むといった対策で、リスクを低減させることが可能です。
https://media.a-x.inc/ai-security
https://media.a-x.inc/ai-copyright
https://media.a-x.inc/ai-hallucination
https://media.a-x.inc/ai-risk
LLMの学習やAI人材育成ならAX CAMPにお任せください

自社専用のLLMを構築し、ビジネスに活用していくためには、本記事で解説したような専門的な知識と技術が不可欠です。「何から手をつければ良いのかわからない」「社内にAIを推進できる人材がいない」といった課題をお持ちの企業様も多いのではないでしょうか。
私たち株式会社AXが提供する「AX CAMP」は、そのような課題を解決するための実践的な法人向けAI研修・伴走支援サービスです。単なる知識のインプットに留まらず、貴社の具体的な業務課題をヒアリングし、最適な学習手法の選定からデータ準備、モデル構築、そして業務への実装までを、経験豊富な専門家がハンズオンでサポートします。
AX CAMPの特長は、実務直結のカリキュラムと徹底した伴走支援にあります。例えば、研修を通じてSNS運用時間を3時間から1時間へ66%削減し、月間1,000万インプレッションを達成したC社様の事例もございます。貴社の状況に合わせたオーダーメイドの研修プログラムを設計し、受講者が自走してAI活用を推進できる人材になることを目指します。LLMの学習だけでなく、AIを活用した業務効率化や新規事業創出まで、企業のAIトランスフォーメーションをトータルでご支援します。まずは無料相談にて、貴社が抱える課題やAI活用に関するお悩みをお聞かせください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMを学習させる手法を理解しビジネスを加速させよう
本記事では、LLMに自社データを学習させるための目的、主要な手法、具体的なプロセス、そしてリスク管理について解説しました。汎用的なLLMを自社の業務に合わせてカスタマイズすることで、AIを単なるツールから、ビジネスを加速させる強力なパートナーへと進化させることができます。
最後に、この記事の重要なポイントをまとめます。
- LLM学習の目的:AIを「自社専用の専門家」に進化させ、専門性の向上、ブランドボイスの統一、情報の最新化を実現する。
- 主要な3つの手法:高品質な「ファインチューニング」、情報更新が容易な「RAG」、低コストな「PEFT」を、目的に応じて使い分けることが重要。
- 成功の鍵はデータ:高精度なモデルを構築するためには、質の高い学習データを十分に準備することが最も重要。
- 計画的なプロセス:目的設定から実装・監視までの5つのステップを計画的に進めることで、手戻りを防ぎ、成果を最大化できる。
- リスク管理の徹底:情報漏洩や著作権、ハルシネーションといったリスクを理解し、技術的・組織的な対策を講じることが不可欠。
これらの手法を自社で実践し、確実な成果に繋げるには、専門的な知識と経験が求められます。もし、AI導入の具体的な進め方や人材育成にお悩みであれば、ぜひ一度「AX CAMP」にご相談ください。貴社の状況に合わせた最適なプランをご提案し、AIによるビジネス変革の実現を強力にサポートします。

法人向けAI研修
AX CAMP 無料資料