

LLM(大規模言語モデル)の出力が毎回少しずつ違うことに、もどかしさを感じていませんか?
「もっと創造的な文章を生成させたい」
「事実に基づいた正確な回答だけが欲しい」
といったニーズがあるにもかかわらず、その調整方法がわからずお困りかもしれません。
この出力の「ブレ」を制御する鍵がtemperature(温度)というパラメータです。 temperatureを調整することで、LLMの応答をより予測可能で事実に忠実なものから、より多様で創造的なものまで、自在にコントロールできます。 この記事を読めば、temperatureの仕組みから、具体的な業務タスクに応じた最適な設定値、さらには他の重要パラメータとの使い分けまで、網羅的に理解できます。
AIの性能を最大限に引き出すための具体的なノウハウは、実践的な法人向けAI研修を提供するAX CAMPの資料でも詳しく解説しています。より高度なAI活用に興味のある方は、ぜひ一度ご覧ください。

法人向けAI研修
AX CAMP 無料資料
LLMにおけるtemperatureとは?
LLMにおけるtemperatureとは、生成されるテキストのランダム性(多様性)を調整するためのパラメータです。 この数値を変更することで、LLMが次に来る単語を予測する際の確率分布を変化させ、出力の「個性」をコントロールできます。temperatureの許容範囲はモデルやプロバイダーごとに異なり、例えばOpenAIのGPTシリーズでは0から2.0、AnthropicのClaudeシリーズでは0.0から1.0が一般的です。値が低いほど予測可能で一貫性のある文章を、高いほど多様で創造的な文章を生成する傾向があります。
temperatureの基本的な役割と仕組み
LLMは、文章を生成する際に、それまでの文脈に基づいて次に来る可能性が最も高い単語を確率的に予測しています。 例えば、「今日の天気は晴れ、絶好の」という文章の後には、「洗濯日和」「お出かけ日和」といった単語が続く確率が高いと判断します。
temperatureは、この単語ごとの出現確率(確率分布)を調整する役割を担います。 具体的には、softmax関数という計算式の中で確率を再計算する際に介入します。低いtemperature設定では、元々確率の高かった単語がさらに選ばれやすくなり、逆に高い設定では、確率の低い意外な単語が選ばれる可能性が高まるのです。
確率分布の変化をビジュアルで理解する
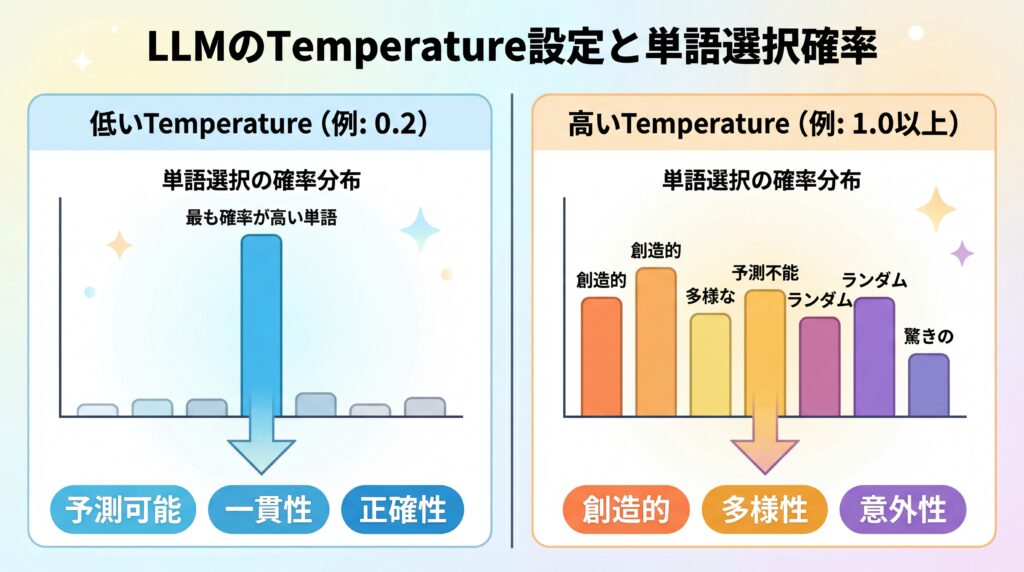
temperatureによる確率分布の変化は、棒グラフで考えると直感的に理解できます。各単語の出現確率を棒の高さで表したグラフを想像してください。
- 低いtemperature(例:0.2):最も確率の高い単語の棒だけが突出して高くなり、他の棒は非常に低くなります。これにより、モデルはほぼ毎回同じ、最も「ありきたり」な単語を選択します。
- 高いtemperature(例:1.0以上):全体の棒の高さが平均化され、なだらかになります。 これにより、確率が低かった単語にも選ばれるチャンスが生まれ、多様な表現が生まれるのです。
このように、temperatureはLLMの「性格」を決定づける重要なダイヤルと言えるでしょう。正確性が求められるタスクでは低く、アイデア出しのような創造性が求められるタスクでは高く設定するのが基本です。次のセクションでは、この設定値が具体的にどのような影響を与えるのかを詳しく見ていきます。

temperatureがLLMの出力に与える影響
temperatureの設定値は、LLMが生成する文章の質とスタイルに直接的な影響を与えます。低い設定は一貫性と正確性を高め、高い設定は創造性と多様性を引き出します。この特性を理解し、目的に応じて使い分けることが、LLMを効果的に活用する上で不可欠です。(出典:LLMの主要パラメータ解説:temperature, Top-p, Top-kの違いとは)
低いtemperature(0に近い値)の特徴と生成例
temperatureを0に近い値(例:0.0〜0.3)に設定すると、モデルは最も確率の高い単語を一貫して選択するようになります。これにより、出力は非常に予測可能で、事実に基づいた安定した文章になります。
- 特徴:決定論的、反復的、一貫性がある、事実に基づきやすい
- 適した用途:翻訳、要約、質疑応答、データ抽出、コード生成など、正確性が最優先されるタスク
例えば、「日本の首都はどこですか?」という質問に対して、低いtemperatureで生成させると、ほぼ確実に「東京です。」という最も確率の高い回答が返ってきます。余計な装飾やブレが生じないため、信頼性の高い情報を得るのに適しています。
高いtemperature(1以上の値)の特徴と生成例
一方で、temperatureを1以上の高い値(例:0.8〜1.5)に設定すると、モデルは確率の低い単語も積極的に選択するようになります。 これにより、出力は多様性に富み、独創的で意外性のある文章になります。
- 特徴:創造的、多様性がある、意外性がある、時に支離滅裂になるリスクも
- 適した用途:小説や詩の執筆、キャッチコピーの考案、ブレインストーミング、多様なアイデア出しなど
同じく、「新しいコーヒーショップのキャッチコピーを考えてください」という指示に対して、高いtemperatureで生成させると、「一杯の静寂が、日常を旅に変える。」といった、より詩的で創造的な表現が生まれる可能性があります。ただし、設定が高すぎると文脈から外れたり、意味不明な文章になったりするリスクも増大するため注意が必要です。
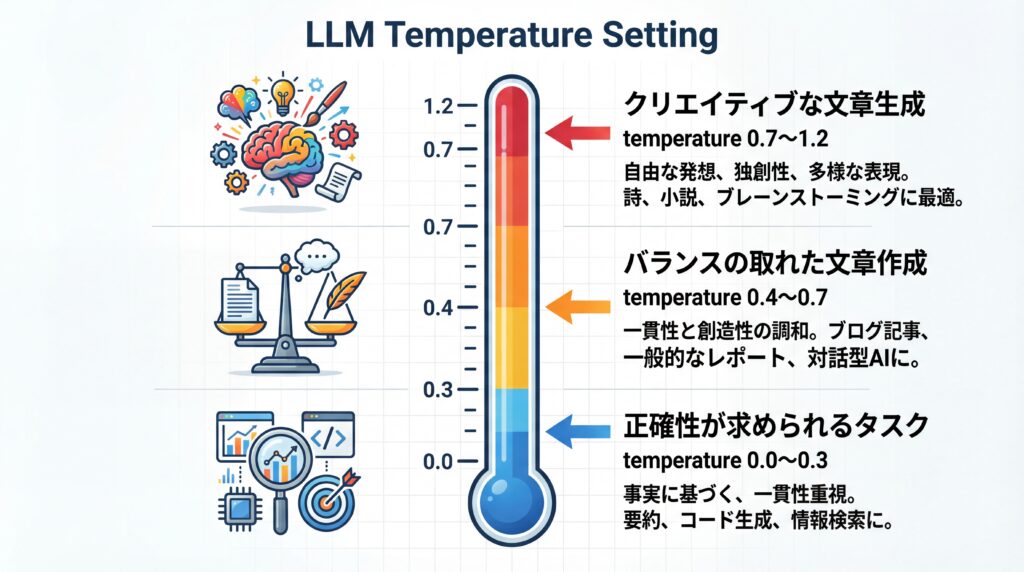
用途別に見るtemperatureの最適な設定値
LLMのtemperatureに唯一の「正解」はなく、タスクの目的に応じて最適な値を設定することが成果を最大化する鍵です。 クリエイティブな発想が欲しいのか、それとも鉄壁の正確性が必要なのかによって、推奨される設定値は大きく異なります。ここでは、代表的な用途ごとの設定値の目安を紹介します。(出典:今更聞けないLLMの「温度」の話を徹底解説)
クリエイティブな文章生成での活用(小説・キャッチコピーなど)
小説のプロット作成、魅力的なマーケティングコピー、あるいは新しい企画のブレインストーミングなど、独創性や多様なアイデアが求められる場面では、比較的高めのtemperature設定が有効です。具体的には0.7から1.2程度の範囲で調整するのが一般的です。
この設定により、モデルはありきたりな表現を避け、意外な単語の組み合わせや斬新な言い回しを生成しやすくなります。ただし、1.2を超えてくると、文章としてのまとまりを失う可能性が高まるため、生成された内容を確認しながら微調整することが重要です。
正確性が求められるタスクでの活用(要約・翻訳・質疑応答など)
長文の要約、外国語への翻訳、社内規定に関するFAQチャットボットなど、事実に基づいた正確で一貫性のある回答が不可欠なタスクでは、低いtemperature設定が必須です。推奨される値は0.0から0.3程度です。
temperatureを0に近づけると、モデルは最も確率の高い単語を選びやすくなります。しかし、完全に0に設定しても、バックエンドの実装やハードウェアの並列処理に起因する微細な計算誤差などにより、出力が常に同一になることは保証されません。再現性が厳密に必要な場合は、シード値の固定(APIがサポートする場合)や出力のキャッシュなど、別の仕組みを検討する必要があります。
多様性と一貫性のバランスを取る設定
ビジネスメールの作成やブログ記事の執筆など、ある程度の正確性を保ちつつも、少しだけ表現の幅を持せたい場合があります。このような多様性と一貫性のバランスが求められるタスクでは、0.4から0.7程度の中間的な設定が適しています。
この範囲であれば、文章の骨子は維持しつつ、毎回少しずつ異なる言い回しや表現を生成させることができます。これにより、文章が単調になるのを防ぎ、より自然で人間らしいテキストを作成することが可能になります。
| 用途 | 推奨temperature | 特徴 |
|---|---|---|
| クリエイティブな文章生成 | 0.7 ~ 1.2 | 多様で独創的なアイデアを生成 |
| バランスの取れた文章作成 | 0.4 ~ 0.7 | 一貫性を保ちつつ表現に幅を持たせる |
| 正確性が求められるタスク | 0.0 ~ 0.3 | 事実に基づいた信頼性の高い回答を生成 |

temperatureと他の主要パラメータとの関係

LLMの出力を制御するパラメータはtemperatureだけではありません。特に重要なのがTop-pとTop-kで、これらをtemperatureと組み合わせることで、よりきめ細やかな出力調整が可能になります。それぞれの役割を理解し、適切に使い分けることが重要です。
Top-p (Nucleus Sampling) との違いと使い分け
Top-pは「Nucleus Sampling」とも呼ばれ、次に来る単語の候補を、確率の高いものから足し合わせていき、その合計が指定したp値(例:0.9)を超えるまでの単語群に限定するという手法です。 例えばTop-pを0.9に設定すると、確率上位の単語の累計が90%に達するまでの単語リストの中から、次の単語が選ばれます。
temperatureが全体の確率分布をなだらかにしたり急にしたりするのに対し、Top-pは選択肢となる単語の「数」を動的に変更する点が異なります。 一般的には、temperatureかTop-pのどちらか一方を調整することが推奨されています。 両方を同時に高く設定すると、予期せぬ挙動をすることがあるためです。より直感的に多様性を制御したい場合はtemperature、より厳密に候補単語を絞り込みたい場合はTop-pが向いています。
Top-k Samplingとの組み合わせ方
Top-kは、単純に次に来る単語の候補を、確率上位k個に限定する手法です。 例えばTop-kを5に設定すれば、最も確率の高い5つの単語の中から次の単語が選ばれます。
Top-kは非常にシンプルで分かりやすいですが、文脈によっては確率の低い単語が多数存在する場面で、質の低い選択肢まで含めてしまう可能性があります。一方で、Top-pは文脈に応じて候補リストのサイズを柔軟に変えられるため、より洗練された方法とされています。 temperatureと組み合わせることも可能ですが、現在ではTop-pの方がより一般的に利用される傾向にあります。
https://media.a-x.inc/llm-parameters
主要LLMモデルにおけるtemperature設定のポイント

LLMのtemperature設定は、モデルを提供する企業によってデフォルト値や許容範囲が異なります。主要なモデルの特性を理解し、それぞれの公式APIドキュメントを確認しながら調整することが、意図した通りの出力を得るための近道です。ここでは、代表的なモデルにおける設定のポイントを解説します。
OpenAI (GPTシリーズ) での設定推奨値とAPIでの指定方法
OpenAIのGPTシリーズ(GPT-5など)では、temperatureは通常0から2.0の範囲で設定でき、デフォルトはモデルによって0.7や1.0など様々です。 モデルのバージョンや利用するAPIのエンドポイントによってパラメータの挙動や推奨値が変わることがあるため、常に公式ドキュメントを参照することが重要です。
APIで指定する場合は、リクエストボディに以下のように含めます。
{ "model": "gpt-4o", "messages": [{"role": "user", "content": "こんにちは"}], "temperature": 0.8 }
多くのモデルでtemperatureは有効ですが、モデルやタスクによってはサポートされない場合もあります。そのため、利用するモデルとエンドポイントの公式ドキュメントで、最新の仕様を確認する習慣をつけるのが良いでしょう。
Google (Gemini) やAnthropic (Claude) での考え方
GoogleのGeminiシリーズでは、モデルによって許容レンジが異なりますが、一般的には0.0から2.0の範囲で設定可能で、デフォルトは1.0であることが多いです。 ただし、モデルやタスクによっては、デフォルト値のまま使用することが推奨される場合もあります。必ず使用するモデルのAPIドキュメントで推奨値を確認してください。
AnthropicのClaudeシリーズでは、temperatureは一般的に0.0から1.0の範囲で設定されます。 Claudeは安全性と信頼性を重視しており、デフォルト設定でもハルシネーション(事実に基づかない情報の生成)が起きにくいとされています。そのため、クリエイティブなタスクであっても、まずは0.7前後から試してみるのが良いでしょう。
どのモデルを使うにせよ、基本的な考え方は同じです。まずはデフォルト値で試し、求める出力に応じて少しずつ値を増減させ、最適なバランスを見つけるアプローチが重要です。

temperature設定時の注意点とよくある失敗例
temperatureはLLMの出力を強力に制御できる一方、設定を誤ると期待から大きく外れた結果を招くことがあります。特に「過度に高く設定しすぎること」と「タスク内容を無視した画一的な設定」は、よくある失敗例です。これらのリスクを理解し、慎重にパラメータを調整することが高品質な出力を得るために不可欠です。
過度に高く設定するリスク(ハルシネーション・意味不明な文章)
temperatureを高く設定しすぎると、モデルは確率の低い単語を頻繁に選択するようになります。これにより、文章の論理的なつながりが失われ、支離滅裂な内容になったり、事実に基づかない情報を生成する「ハルシネーション」のリスクが急激に高まります。
例えば、企業のプレスリリース作成をtemperature=1.8のような極端に高い値で指示した場合、「当社の新製品は、銀河系の平和を守るために開発されました」といった、文脈から完全に逸脱した非現実的な文章が生成される可能性があります。創造性を求める場合でも、まずは1.0前後から始め、少しずつ上げていくのが安全です。
Inmark様の事例:広告チェック業務を大幅に自動化
Web広告運用代行を手がけるInmark様は、毎日の広告チェック業務に多くの時間を費やしていました。AX CAMPでAIの活用法を学び、毎日1時間以上かかっていたチェック業務の大幅な自動化に成功しました。この事例のように、定型的で正確性が求められる業務の自動化では、低いtemperature設定が成果に直結します。(出典:AI導入のよくある失敗事例5選|成功に導くためのポイントも解説)
モデルの特性を無視した画一的な設定の危険性
もう一つの失敗例は、あらゆるタスクに対して同じtemperature設定を使い回してしまうことです。LLMは汎用的に見えますが、その能力を最大限に引き出すには、タスクの性質に合わせたチューニングが欠かせません。
例えば、デフォルト値の0.7を、顧客からの問い合わせに回答するチャットボットにそのまま適用したとします。すると、毎回回答のニュアンスが微妙に異なったり、時には不正確な情報を含んだりする可能性があり、顧客の混乱を招きかねません。タスクごとに最適な設定を見極めることが重要です。
WISDOM合同会社様の事例:AI活用で採用2名分の業務を代替
SNS広告などを手掛けるWISDOM合同会社様は、事業拡大に伴う人材採用のコストと業務負荷に課題を抱えていました。AX CAMPの研修を通じて業務の自動化を推進した結果、AIが採用予定2名分の業務を代替するほどの効率化を達成しました。適切なAI活用は、人材不足という経営課題の解決にも繋がります。(出典:【参加無料】業務で使える生成AIの基礎知識や活用方法が学べる実践型AIセミナー)
エムスタイルジャパン様の事例:全社で月100時間以上の業務を削減
美容健康食品メーカーのエムスタイルジャパン様では、コールセンターの履歴確認や広告レポート作成といった手作業が多く発生していました。AX CAMPでGAS(Google Apps Script)とAIを組み合わせた自動化を実践し、コールセンター業務をほぼ0に、全社で月100時間以上の業務削減を実現しました。これも、タスクに適したAIツールの選定と設定がもたらした成果です。(出典:月100時間以上の”ムダ業務”をカット!エムスタイルジャパン社が築いた「AIは当たり前文化」の軌跡)

LLMの性能をビジネスで最大化するならAX CAMP

LLMのtemperatureのようなパラメータを理解することは、AIをビジネスに活用する第一歩です。しかし、理論を知るだけでは、実際の業務課題を解決し、具体的な成果に結びつけるのは容易ではありません。本当に重要なのは、これらの知識を自社の業務プロセスにどう組み込み、どう効率化を実現するかという実践的なノウハウです。
AX CAMPは、まさにその「実践」に重きを置いた法人向けのAI研修・伴走支援サービスです。単なるツールの使い方を学ぶのではなく、貴社の具体的な業務課題をヒアリングし、それに合わせたカリキュラムを構築。広告チェックの自動化やレポート作成の効率化など、明日から使える具体的なAI活用術を、ハンズオン形式で習得できます。(出典:法人向けAI研修・伴走支援 AX CAMP)
Inmark様やWISDOM様のように、AI導入によって劇的な業務効率化を実現した企業は少なくありません。AIを「知っている」段階から「使いこなし、成果を出す」段階へとステップアップするために、専門家のサポートは非常に有効です。自社だけでAI導入を進めることに不安を感じている、あるいは何から手をつければ良いかわからないという方は、ぜひ一度、AX CAMPの無料相談をご活用ください。貴社の課題に合わせた最適なAI活用プランをご提案します。(出典:生成AIの法人向け研修サービス AX CAMP 導入事例)

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMのtemperatureを理解して出力品質を向上させよう
本記事では、LLMの出力品質を左右する重要なパラメータ「temperature」について、その仕組みから最適な設定方法、注意点までを網羅的に解説しました。最後に、重要なポイントを振り返ります。
- temperatureの役割:LLMが生成するテキストのランダム性(創造性)と予測可能性(一貫性)のバランスを調整する。
- 低い設定(0.0〜0.3):要約や翻訳など、正確性が求められるタスクに最適。
- 高い設定(0.7以上):アイデア出しやクリエイティブな文章作成に向いている。
- モデルごとの違い:許容範囲やデフォルト値が異なるため、利用するモデルの公式ドキュメントを必ず確認する。
- 注意点:設定が高すぎるとハルシネーションのリスクが増大し、タスク内容を無視した画一的な設定は非効率。
temperatureを適切に使いこなすことは、LLMを単なる「便利なツール」から「戦略的なビジネスパートナー」へと進化させるための鍵です。しかし、これらの技術を自社の業務に最適化し、全社的な生産性向上に繋げるには、専門的な知識と体系的な導入計画が不可欠です。
AX CAMPでは、今回ご紹介したような専門知識の提供はもちろん、貴社のビジネス課題に直結するAI活用法の策定から、社員のスキルアップ、定着化までをワンストップで支援します。エムスタイルジャパン様が実現した月100時間以上の業務削減のように、AIは正しく導入すれば絶大な効果を発揮します。AI導入の第一歩を踏み出したい、あるいは現在の活用レベルをさらに引き上げたいとお考えでしたら、ぜひ下記の資料請求または無料相談をご検討ください。(出典:AI導入・業務フロー構築支援)

法人向けAI研修
AX CAMP 無料資料