

自社で大規模言語モデル(LLM)を運用したいけれど、セキュリティやコスト、何から手をつければ良いか分からず悩んでいませんか。クラウドAPIは手軽ですが、機密情報の扱いや利用料の増大が懸念されます。そんな中、解決策として注目されているのが「LLMサーバー」の自社構築です。
自社の閉じたネットワーク内でLLMを運用することで、情報漏洩リスクを根本から断ち切り、長期的なコスト削減も可能になります。この記事では、LLMサーバーを自社構築するメリット・デメリットから、具体的なシステム要件、構成例、さらにはおすすめのツールまで、成功の秘訣を網羅的に解説します。この記事を読めば、自社に最適なLLM環境を構築するための具体的な道筋が見えるはずです。
AI導入の具体的な進め方や、業務への活用方法をまとめた資料もご用意していますので、ぜひご活用ください。

法人向けAI研修
AX CAMP 無料資料
LLMサーバーとは?自社構築が注目される背景

結論として、LLMサーバーとは自社の管理下で大規模言語モデルを稼働させるための高性能なサーバー環境を指します。具体的には、LLMの巨大なモデルデータを高速処理するために、高性能なGPU(Graphics Processing Unit)や大容量メモリを搭載した物理サーバーや仮想サーバーのことです。
近年、多くの企業でLLMサーバーの自社構築(オンプレミス)が注目を集めています。その背景には、クラウドサービスを介さずに自社データを安全に扱いたいという、セキュリティとデータプライバシーに対する意識の高まりがあります。外部サービス利用時の情報漏洩リスクや、利用量に応じて増加するコストへの懸念が、自社管理への回帰を後押ししているのです。
クラウドAPIサービスとの根本的な違い
LLMを利用する方法は、自社構築の他にOpenAIのGPTシリーズなどをAPI経由で利用するクラウドサービスがあります。両者の最も大きな違いは、「データの管理場所」と「カスタマイズの自由度」にあります。
クラウドAPIサービスは、インターネット経由でデータを外部のサーバーに送信して処理します。手軽に最新のLLMを利用できる反面、機密情報や個人情報を外部に送信することへの懸念が残ります。一方、自社構築サーバーは、データを内部ネットワークに留めたまま処理できます。適切なアクセス管理や暗号化、運用体制を整えることで、外部クラウド利用時に比べて特定の情報漏洩リスクを低減できる場合があります。また、特定の業務に合わせてモデルを細かく調整(ファインチューニング)することも容易になるでしょう。
| 比較項目 | LLMサーバー(自社構築) | クラウドAPIサービス |
|---|---|---|
| データ管理 | 社内(クローズド環境) | 社外(クラウド事業者) |
| セキュリティ | データ主権を確保しやすい | 事業者のポリシーに依存 |
| カスタマイズ性 | 高い(独自ファインチューニング可) | 限定的 |
| 導入コスト | 高い(初期投資) | 低い(従量課金) |
| 運用コスト | 固定的(ただし利用増で変動) | 変動的(利用量に比例) |
高まるセキュリティとデータプライバシーの重要性
ビジネスでAI活用が進むにつれて、顧客情報や技術情報といった機密データをLLMで扱う機会が増加しています。これらの情報をクラウドAPIで処理する場合、データが意図せずモデルの学習に使われたり、サイバー攻撃の標的になったりするリスクはゼロではありません。
オンプレミス運用は、外部クラウド事業者のデータ利用ポリシーに関するリスクを低減しますが、ゼロリスクを保証するものではありません。内部脅威や運用ミス、パッチ適用の遅延といった別のリスクが存在します。そのため、ゼロトラストの考え方に基づき、データの暗号化、厳格なアクセス管理、定期的な監査、物理セキュリティの確保といった多層的な対策を自社で講じることが不可欠です。
https://media.a-x.inc/ai-security
https://media.a-x.inc/llm-on-premise
LLMサーバーを自社構築するメリット・デメリット
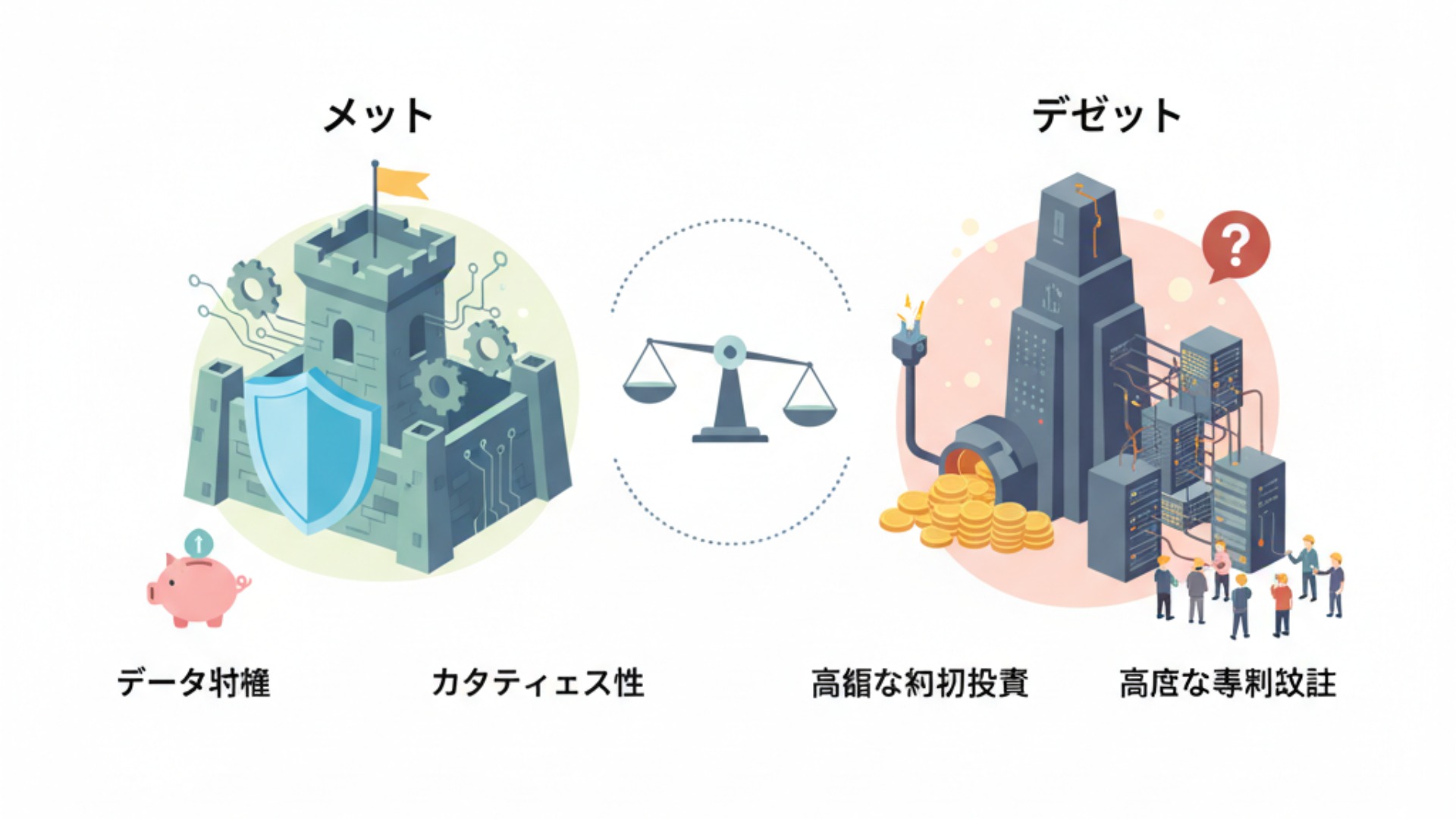
LLMサーバーの自社構築は、データ主権の確保、カスタマイズ性、そして特定の条件下でのコスト管理にメリットがある一方で、高額な初期投資や高度な専門知識が求められます。導入を検討する際は、これらの両側面を正確に理解し、自社の状況と照らし合わせて判断することが不可欠です。
長期的な視点でコストを最適化し、独自のAI活用を目指す企業にとって、自社構築は強力な選択肢となります。しかし、その実現には相応のリソースが必要となる点を念頭に置く必要があります。
主なメリット:コスト管理・セキュリティ・カスタマイズ性
自社でLLMサーバーを構築する主なメリットは、以下の3点に集約されます。(出典:オンプレミスLLMのメリットとデメリットは? クラウドLLMとの違いを比較)
- コスト管理の可能性:APIサービスのような従量課金制ではないため、一定の利用量を超えるとコストメリットが出る場合があります。ただし、高利用時には電力、冷却、保守、人件費が増加するため、クラウドとの費用分岐点は利用パターンや期間によって変動します。
- データ主権の確保:データを外部に出さないため、自社の管理下でデータをコントロールできます。ただし、金融や医療など特に高いデータガバナンスが求められる業界では、適切な法令・業界ガイドラインの要件(例:医療情報の扱い、金融データの管理)を満たすための追加措置が必要です。
- 高度なカスタマイズ性:オープンソースのLLMをベースに、自社の特定業務に特化した独自のファインチューニングを自由に行えます。これにより、他社にはない競争優位性を生み出すことも可能です。
注意すべきデメリット:初期投資・専門知識・運用保守
メリットの裏返しとして、注意すべきデメリットも存在します。特に以下の3点は、導入の障壁となり得ます。
- 高額な初期投資:LLMを快適に動作させるには、高性能なGPUを多数搭載したサーバーが必要であり、ハードウェアだけで数百万円から数千万円規模の投資が発生します。
- 高度な専門知識:サーバーの設計・構築からAIモデルのデプロイ、セキュリティ対策まで、インフラとAIの幅広い専門知識を持つ人材が不可欠です。
- 継続的な運用保守:導入後もハードウェアのメンテナンス、ソフトウェアのアップデート、セキュリティパッチの適用など、安定稼働を維持するための運用保守業務が継続的に発生します。
https://media.a-x.inc/ai-benefits
https://media.a-x.inc/disadvantages-of-ai
https://media.a-x.inc/ai-risk
LLMサーバー構築に必要なシステム要件

LLMサーバーの性能を最大限に引き出すためには、システム要件を正しく理解することが極めて重要です。特に、LLMの計算処理の核となるGPUの選定が、プロジェクトの成否を分ける最大のポイントと言っても過言ではありません。GPUの性能、特に搭載されているVRAM(ビデオメモリ)の容量が、扱えるモデルの規模や処理速度を直接決定します。
もちろん、GPUだけでなく、それを支えるCPUやメインメモリ、ストレージもバランス良く構成する必要があります。これらの要素が一体となって、初めて高性能なLLMサーバーが実現するのです。(出典:Getting Started with NVIDIA NIM for LLMs)
GPU選定のポイント(VRAM容量と性能)
LLMのモデルは、その構造上、膨大な数のパラメータを持っています。このパラメータを一時的に記憶する場所がGPUのVRAMです。そのため、利用したいLLMのパラメータサイズを十分に格納できるVRAM容量を持つGPUを選ぶことが絶対条件となります。
例えば、パラメータ数が700億(70B)のモデルを動かす場合、単純計算でも最低140GB以上のVRAMが必要となります(FP16精度の場合)。(出典:ローカルLLMに最適なPC構成とは? VRAM使用量の計算方法から解説)しかし、実運用では推論中のKVキャッシュやAttentionの計算(アクティベーション)などで追加のメモリが消費されます。INT8/4量子化やvLLMのような最適化技術でメモリ要件を削減することも可能ですが、まずは想定モデルでの実測に基づいた設計が不可欠です。(出典:GKE で LLM サービング用の GPU を選択する)
現在、LLMサーバーで主流となっているのはNVIDIA社のデータセンター向けGPUです。代表的なモデルには以下のようなものがあります。
- NVIDIA H100 (80GB)
- NVIDIA A100 (40GB/80GB)
これらのGPUを複数枚サーバーに搭載し、合計のVRAM容量を確保します。また、GPU同士を高速に接続するNVLinkのような技術も、大規模モデルを効率的に処理する上で重要な要素となります。
CPU・メモリ・ストレージの推奨スペック
GPUがLLMの「頭脳」だとすれば、CPU、メモリ、ストレージはそれを支える「身体」の役割を担います。これらのスペックが低いと、いくら高性能なGPUを搭載しても、データ供給が追いつかずに性能を全く発揮できません(ボトルネック)。
CPUは、データの準備やGPUへの転送など、計算以外の処理全般を担当します。コア数が多く、PCI Expressのレーン数が多いモデルが適しています。メインメモリは、学習データセットや前処理済みデータを保持するために重要です。搭載するGPUの総VRAM容量と同等以上、できれば2倍程度の容量を搭載することが推奨されます。例えば、総VRAMが320GB(80GB×4基)のサーバーであれば、640GB以上のメインメモリを搭載するのが一つの目安です。ストレージには、巨大なLLMモデルやデータセットを保存します。読み書き速度が非常に高速なNVMe対応のSSDを選択することで、データ読み込み時間を短縮し、全体の処理効率を高めることができます。
https://media.a-x.inc/ai-gpu
https://media.a-x.inc/llm-memory
https://media.a-x.inc/llm-parameters
LLMサーバーの代表的なシステム構成例
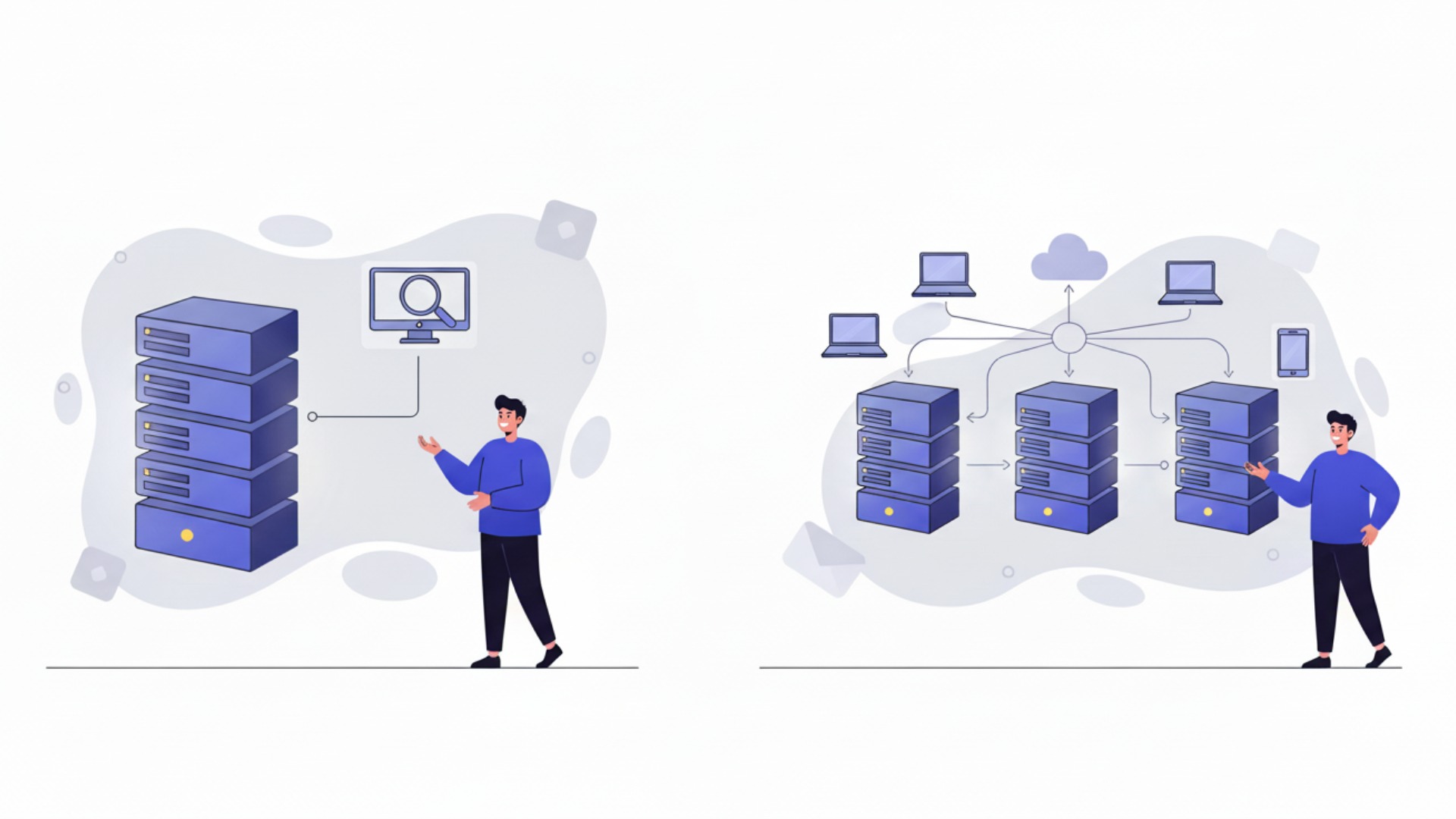
LLMサーバーのシステム構成は、利用目的や規模に応じて大きく2つのパターンに分けられます。小規模な利用や実証実験(PoC)から始める場合は「単一サーバー構成」、全社的な大規模利用や高い可用性が求められる場合は「分散サーバー構成」が基本となります。それぞれの構成には特徴があり、予算や求める性能に応じて適切なものを選択することが成功への第一歩です。
まずは単一サーバーでスモールスタートし、利用拡大に合わせて分散構成へスケールアップしていくという段階的なアプローチも有効な戦略と言えるでしょう。
単一サーバー構成:スモールスタート向け
単一サーバー構成は、1台の物理サーバーに複数のGPUを搭載する、最もシンプルで導入しやすい構成です。特定の部門での利用や、まずはLLMで何ができるかを試したい、といったスモールスタートの用途に適しています。
例えば、1台のサーバーにNVIDIA H100 GPUを4基または8基搭載し、CPU、メモリ、ストレージをバランス良く組み合わせます。この構成でも、中規模のオープンソースLLM(例: Llama 3 70B)を快適に動かすことが可能です。(出典:Supported Models – NVIDIA NIM for LLMs)初期投資を抑えつつ、迅速にLLM環境を立ち上げられる点が最大のメリットです。ただし、サーバー自体が故障するとサービスが完全に停止してしまう単一障害点(SPOF)となるため、ミッションクリティカルな用途には向きません。
分散サーバー構成:大規模利用・高可用性向け
分散サーバー構成は、複数のLLMサーバーを高速なネットワークで接続し、全体として一つの巨大な計算リソースとして利用する構成です。パラメータ数が数千億を超えるような非常に大規模なモデルの運用や、多数のユーザーが同時に利用する全社的なAI基盤の構築に適しています。
この構成では、InfiniBandなどの超低遅延・広帯域なネットワーク技術を用いてサーバー間を接続するのが一般的です。複数のサーバーに処理を分散させることで、単一サーバーでは扱えない巨大なモデルを動かしたり、複数のユーザーからのリクエストを並行して処理したりできます。また、一部のサーバーが故障しても他のサーバーで処理を継続できるため、可用性が非常に高いシステムを構築できるのも大きな利点です。
https://media.a-x.inc/llm-build
https://media.a-x.inc/llm-architecture
【2026年】LLMサーバー構築におすすめのツール・フレームワーク

LLMサーバーを効率的に構築・運用するためには、適切なツールやフレームワークの選定が不可欠です。2025年現在、コンテナ技術である「Docker」と、その管理・自動化を行う「Kubernetes」を中核としたエコシステムがデファクトスタンダードとなっています。これらの技術を活用することで、環境構築の再現性を高め、GPUリソースを効率的に管理できます。(出典:GKE で LLM サービング用の GPU を選択する)
さらに、推論処理を高速化する専用サーバーソフトウェアや、モデルのライフサイクル全体を管理するMLOps(機械学習基盤)ツールを組み合わせることで、より高度で安定したLLM運用が実現します。最近では、NVIDIA社が提供する推論用マイクロサービス「NVIDIA NIM」なども登場し、本番環境へのAIモデルのデプロイを簡素化する選択肢が増えています。(出典:Getting Started with NVIDIA NIM for LLMs)
代表的なツール・フレームワークは以下の通りです。
- コンテナ化技術:Dockerが広く使われ、アプリケーションとその依存関係をパッケージ化します。これにより、どんな環境でも同じように動作させることが可能です。
- コンテナオーケストレーション:Kubernetesが中心的な役割を担い、多数のコンテナのデプロイ、スケーリング、管理を自動化します。GPUリソースを扱うには、NVIDIA GPU Operatorなどの連携が一般的です。
- LLM推論サーバー:推論処理を高速化する専用サーバーも重要です。vLLM、NVIDIAのTensorRT-LLM、Triton Inference Serverなどが有名で、スループットを大幅に向上させます。
- MLOpsプラットフォーム:モデルの開発からデプロイ、監視までを一元管理するMLflowやKubeflowなどを導入することで、属人化を防ぎ、継続的なモデル改善のサイクルを回しやすくなります。
https://media.a-x.inc/llm-open-source
https://media.a-x.inc/llm-inference
LLMサーバー導入・運用後の効果

LLMサーバーを自社で構築・運用することにより、単なる業務効率化に留まらない、事業そのものを変革するような大きな効果が期待できます。適切な体制が整えば、これまで外部委託していた業務の内製化や、全く新しいサービスの創出といった機会が生まれる可能性があります。ただし、その実現度は業務内容や社内リソースに大きく依存します。実際に、当社のAI研修サービス「AX CAMP」を導入し、AI活用を推進した企業では、目覚ましい成果が生まれています。(出典:【2026年最新】AIの企業・行政での活用事例33選!)
ここでは、具体的な企業事例を通じて、LLMサーバー導入後の世界をイメージしてみましょう。
Foxx様の事例
D2C・EC領域に特化した広告代理店事業を手がけるFoxx様は、属人化した定型業務に多くの時間を費やしていました。AX CAMPの研修を通じてAI活用のスキルを習得し、AIを「思考のパートナー」として活用。その結果、月75時間かかっていた定型業務の時間を創出し、新規事業の立ち上げを実現しました。これは、自社で自由にAIを試せる環境を整えたからこそ成し得た成果と言えるでしょう。(出典:月75時間の運用業務を「AIとの対話」で変革!Foxx社、新規事業創出も実現)
WISDOM合同会社様の事例
SNS広告やショート動画制作を行うWISDOM合同会社様では、事業拡大に伴う人材採用コストと業務負荷の増大が課題でした。AX CAMPで得た知見を活かし、定型的な業務をAIで自動化する仕組みを構築。その結果、採用予定だった2名分の業務をAIが代替することに成功しました。これは、特定の定型業務(例:レポート作成、データ入力など)を自動化したことによる工数削減効果を人件費に換算したもので、採用コストを削減しつつ、既存の従業員はより創造的な業務に集中できる環境を整えました。(出典:【導入事例】採用2名分の業務をAIが代替。WISDOM合同会社が実現した、AI人材育成による事業拡大とは)
エムスタイルジャパン様の事例
美容健康食品の製造販売を行うエムスタイルジャパン様は、コールセンターの履歴確認や広告レポート作成に多くの時間を費やしていました。AX CAMPの研修で習得したスキルを活用し、これらの業務を自動化。その結果、これまで月16時間かかっていたコールセンターの確認業務がほぼ0時間になるなど、全社で月100時間以上の業務削減を達成したと報告されています。(出典:RAGとは?LLMのハルシネーションを防ぐ仕組みを初心者向けに解説)
https://media.a-x.inc/ai-use-case
https://media.a-x.inc/llm-use-cases
https://media.a-x.inc/ai-efficiency
LLMサーバー運用における課題と解決策
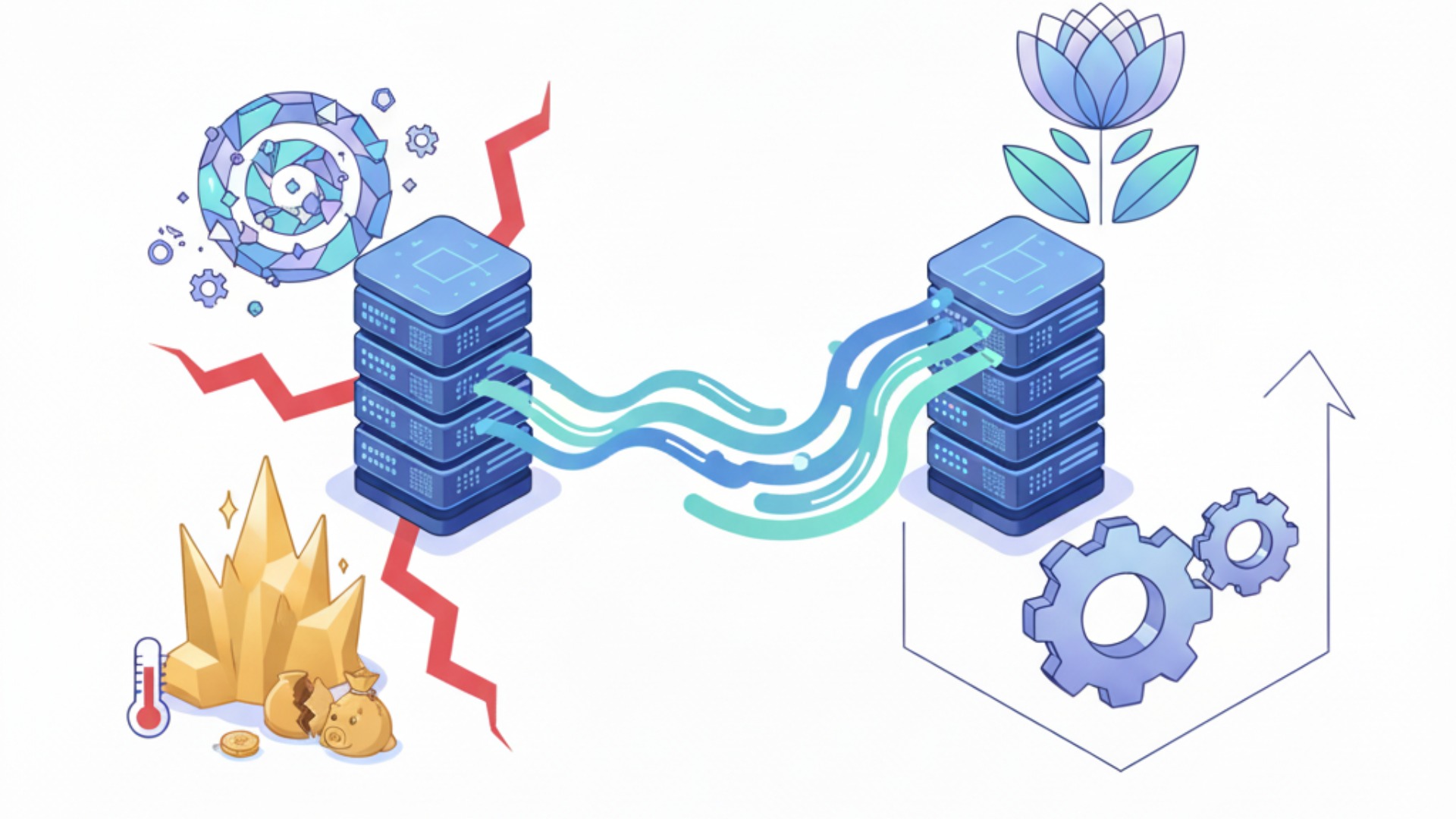
LLMサーバーは構築して終わりではなく、その後の安定的な運用こそが真の価値を生み出します。しかし、運用段階では「モデルの継続的なアップデート」と「高価なGPUリソースの効率活用」という2つの大きな課題に直面することが少なくありません。これらの課題への対策をあらかじめ計画に織り込んでおくことが、LLMサーバーへの投資対効果を最大化する鍵となります。
幸い、これらの課題には先人たちの知見に基づいた効果的な解決策が存在します。
課題1:モデルの継続的なアップデートと管理
LLMの世界は日進月歩であり、GPT-5のような、より高性能なモデルが次々と登場します。 自社サーバーで運用しているモデルが陳腐化しないよう、これらの新しいモデルに追従し、継続的にアップデートしていく必要があります。(出典:Introducing GPT-5)また、自社データでファインチューニングしたモデルも、新しいデータを取り込んで定期的に再学習させなければ、性能が劣化してしまいます。
この課題への解決策は、CI/CD(継続的インテグレーション/継続的デリバリー)の考え方を導入することです。モデルの学習、評価、デプロイといった一連のプロセスを自動化するパイプラインを構築することで、アップデート作業の手間を大幅に削減し、迅速かつ安全に新しいモデルを本番環境に反映させることができます。Gitのようなバージョン管理システムでモデルや学習コードを管理することも不可欠です。
課題2:GPUリソースの効率的な活用
GPUはLLMサーバーの中で最も高価なコンポーネントであり、その稼働率をいかに高めるかがコスト効率に直結します。特定のユーザーがGPUを長時間占有する状況は避けなければなりません。特に、複数の部門で1つのLLMサーバーを共有する場合は、リソースの公平な分配が課題となります。
この課題に対しては、Kubernetesのようなコンテナオーケストレーションツールによるリソース管理が極めて有効です。KubernetesとNVIDIA GPU Operatorなどを組み合わせ、MIG(Multi-Instance GPU)やタイムスライシングを用いることで、1つの物理GPUを複数のコンテナで分割・共有できます。MIGはメモリやフォールトが分離されるため安定性が高い一方、タイムスライシングはより柔軟な共有が可能です。これらの技術とジョブキューイングシステムを組み合わせることで、GPUの遊休時間を減らし、サーバー全体のスループットを向上させます。
https://media.a-x.inc/ai-challenges
https://media.a-x.inc/llm-finetune-dataset
LLMサーバーの構築・運用を成功させたいならAX CAMP

LLMサーバーの自社構築は、データガバナンスやコスト面で大きなメリットをもたらしますが、その実現にはGPUの選定からシステム構成、運用ツールの導入まで、高度で幅広い専門知識が不可欠です。何から手をつければ良いか、どの技術を選べば良いか、自社の人材だけで進めることへの不安を感じる方も多いのではないでしょうか。
そのような課題を解決し、LLMサーバーの構築・運用を成功に導くのが、当社が提供する実践型の法人向けAI研修「AX CAMP」です。AX CAMPでは、机上の空論ではない、実務に直結するカリキュラムを通じて、LLM環境の構築から運用、そして業務活用までを体系的に学ぶことができます。
私たちの強みは、単なる知識の提供に留まらない伴走型のサポート体制にあります。貴社の具体的な課題や目的に合わせて研修内容をカスタマイズし、経験豊富な講師がプロジェクトの立ち上げから実装までをしっかりと支援します。自社でLLMを使いこなし、ビジネスを加速させるための最短ルートを、私たちと一緒に見つけませんか。ご興味のある方は、ぜひ一度、無料のオンライン相談会にご参加ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMサーバーの自社構築を成功させ、AI活用を次のステージへ
本記事では、LLMサーバーを自社で構築するためのメリット・デメリットから、具体的なシステム要件、構成例、そして運用上の課題と解決策までを網羅的に解説しました。最後に、重要なポイントを改めて振り返ります。
- LLMサーバーの自社構築は、データ主権の確保とコスト管理に可能性がある
- メリット(データ主権、カスタマイズ性)とデメリット(初期投資、専門知識、運用責務)の理解が重要
- システム要件で最も重要なのはGPUのVRAM容量と関連スペック
- DockerとKubernetesの活用が効率的な構築・運用の鍵
- 導入後の効果を最大化するには、継続的なモデル更新とリソース管理が不可欠
LLMサーバーの自社構築は、決して簡単なプロジェクトではありません。しかし、それを乗り越えた先には、データを社外に出すことなく安全にAIの恩恵を最大限に享受し、競合他社にはない独自の強みを築く未来が待っています。
もし、自社だけでの構築・運用に少しでも不安があれば、専門家の力を借りるのが成功への近道です。「AX CAMP」では、貴社の状況に合わせた最適なLLM導入プランの策定から、それを実現するための人材育成まで、一気通貫でサポートします。AI活用を次のステージへと進めるため、まずはお気軽にご相談ください。

法人向けAI研修
AX CAMP 無料資料