

Webサイトからの情報収集を効率化したい、と考えている担当者の方は多いのではないでしょうか。しかし、従来のスクレイピング手法はWebサイトの構造変更に弱く、頻繁なメンテナンスが必要になるという課題がありました。この問題を解決するのが、大規模言語モデル(LLM)を活用した次世代のスクレイピング技術です。
LLMスクレイピングは、人間のようにWebページの内容を意味的に理解するため、構造変更に強く、高精度なデータ抽出を実現します。この記事を読めば、LLMスクレイピングの基本的な仕組みから、具体的なメリット、2026年最新のおすすめツール、実践的なステップ、そして法的な注意点まで、網羅的に理解できるでしょう。データ収集業務を劇的に効率化するヒントがここにあります。
また、自社でAI活用を推進し、業務効率化をさらに加速させたい方向けに、具体的なノウハウをまとめた資料もご用意しています。ぜひ、貴社のAI導入の参考にしてください。

法人向けAI研修
AX CAMP 無料資料
LLMスクレイピングとは?従来の手法との違い

結論として、LLMスクレイピングとは、大規模言語モデル(LLM)が持つ高度な自然言語理解能力を用いて、Webページから必要な情報を抽出する技術です。HTMLの特定のタグやクラス名を指定する従来の手法とは異なり、Webページの内容を文脈で理解してデータを取得する点が最大の違いと言えます。
この特性により、Webサイトのレイアウトが変更されても、従来の手法に比べて安定して情報を収集し続けやすいのが特長です。まさに、データ収集のあり方を変える革新的なアプローチと言えるでしょう。(出典:LLM Scraper: Using Large Language Models for Web Scraping)しかし、LLMはレイアウト変更への耐性を高められますが、完全な無メンテナンスを保証するものではありません。実運用ではDOMパースやチャンク化、スキーマ検証、監視を併用して精度を担保するアプローチが現実的です。それでも、セレクタ変更のたびにコードを書き換える必要はなく、運用上の課題を大幅に軽減できる点は大きなメリットです。
LLMがWebページの構造を理解する仕組み
LLMは、WebページのHTMLコードをそのまま長大なテキストとして読み込むわけではありません。多くの場合、HTMLは解析器(パーサー)によってDOM(Document Object Model)と呼ばれるツリー構造に変換され、タグの階層関係を保ったまま抽出されます。特に大きなページでは、全文を一度に処理せず、意味のある単位で分割(チャンク化)したり、RAG(検索拡張生成)技術を使ったりして、必要な部分だけを効率的にモデルへ供給するのが一般的です。(出典:社内情報と連携するRAGとは?)RAGは、外部の最新情報や社内文書を検索し、その内容を基にLLMが回答を生成する仕組みで、情報の正確性を高める効果があります。
この仕組みにより、人間が「この部分が見出し」「ここが製品価格」と判断するように、LLMもコンテンツの役割を理解します。(出典:LLMを活用したWebスクレイピング)その精度を担保するためには、適切な前処理、抽出したいデータ構造の定義(スキーマ)、出力結果の検証、そして定期的な監視を組み合わせる必要があります。これらを組み合わせることで、LLMは構造ではなく意味をベースに情報を捉え、人間のように柔軟なデータ抽出を実現できるのです。例えば、「最も評価の高いレビューを3つ抽出して」といった自然言語での指示(プロンプト)を与えるだけで、LLMはHTMLの中から該当箇所を自律的に探し出し、指定された形式で情報を整理して出力できます。(出典:llm-scraper on GitHub)
従来手法の課題とLLMによる解決策
従来のスクレイピングは、CSSセレクタやXPathといった仕組みを使い、HTMLの特定の位置を指定して情報を抜き出していました。この手法には、主に以下の3つの課題がありました。
- サイトの変更耐性の低さ:デザイン変更で指定位置がずれ、すぐに動かなくなる。
- 複雑なサイト構造への対応:動的にコンテンツが生成されるサイトからの抽出が難しい。
- 非構造化データの抽出困難:自然な文章の中から特定の情報を抜き出すのが苦手。
Webサイトのデザインが少しでも変更されると、指定した位置情報がずれてしまい、データが取得できなくなります。そのため、定期的なプログラムのメンテナンスが不可欠で、多くの工数がかかっていました。
一方で、LLMスクレイピングはHTMLの構造ではなくコンテンツの意味を理解するため、サイトの軽微なデザイン変更の影響を受けにくいです。「製品名」という情報がどこに移動しても、LLMはそれを「製品名」として認識し、正確に抽出し続けます。これにより、メンテナンスコストを劇的に削減し、より重要な業務にリソースを集中させることができます。

LLMでスクレイピングを行うメリット

LLMでスクレイピングを行う最大のメリットは、高精度かつ柔軟なデータ抽出と、開発・メンテナンス工数の大幅な削減という2つの側面に集約されます。これにより、これまで時間や技術的な制約で諦めていたデータ収集も可能になります。
単に作業を自動化するだけでなく、収集できるデータの質と量を飛躍的に向上させ、ビジネスにおけるデータ活用のレベルを一段階引き上げることができるでしょう。
高精度かつ柔軟なデータ抽出が可能になる
LLMは、単にテキストを抜き出すだけでなく、その内容を理解した上での抽出ができます。例えば、「製品レビューの中から、ポジティブな意見だけを要約して」といった曖昧で高度な要求にも応えられます。これは、従来のキーワードマッチングや正規表現では実現が困難でした。
さらに、表形式になっていない文章や、SNSの投稿のような非構造化データからも、「価格」「発売日」「機能」といった特定の情報を的確に抜き出す能力に長けています。この柔軟性により、これまで分析が難しかった定性的な情報も定量的なデータとして扱うことができ、分析の幅が大きく広がります。
開発・メンテナンスの工数を大幅に削減できる
従来の手法では、対象サイトごとにHTML構造を解析し、専用の抽出ロジックをプログラミングする必要がありました。しかし、LLMスクレイピングでは、抽出したい内容を自然言語のプロンプトで指示するだけで済むため、開発にかかる時間を劇的に短縮できます。
AXの支援先であるRoute66株式会社様の事例では、AIの活用により、これまで24時間かかっていた原稿執筆時間をわずか10秒に短縮することに成功しました。(出典:原稿執筆が24時間→10秒に!Route66社が実現したマーケ現場の生成AI内製化) これは情報収集を含むコンテンツ制作プロセスがいかに効率化されるかを示す好例です。ただし、これは特定の条件下での個別の事例であり、同様の成果を保証するものではありません。
また、前述の通り、サイト構造の変更に対する耐性が高いため、一度設定すれば長期間安定して動作し続けます。これにより、エラー発生時の修正対応といった煩雑なメンテナンス業務から解放されるのです。

法人向けAI研修
AX CAMP 無料資料
LLMスクレイピングの主な手法と仕組み

LLMスクレイピングには、大きく分けて3つの主要なアプローチが存在します。どの手法を選択するかは、対象となるWebページの複雑さ、抽出したい情報の種類、そして利用するLLMの性能によって決まります。それぞれの仕組みを理解することで、より効果的なスクレイピング戦略を立てることができます。
基本的な手法は、HTMLをテキストとしてLLMに渡す方法ですが、その渡し方や、画像を活用する方法など、いくつかのバリエーションがあります。ここでは、代表的な手法とその特徴を解説します。
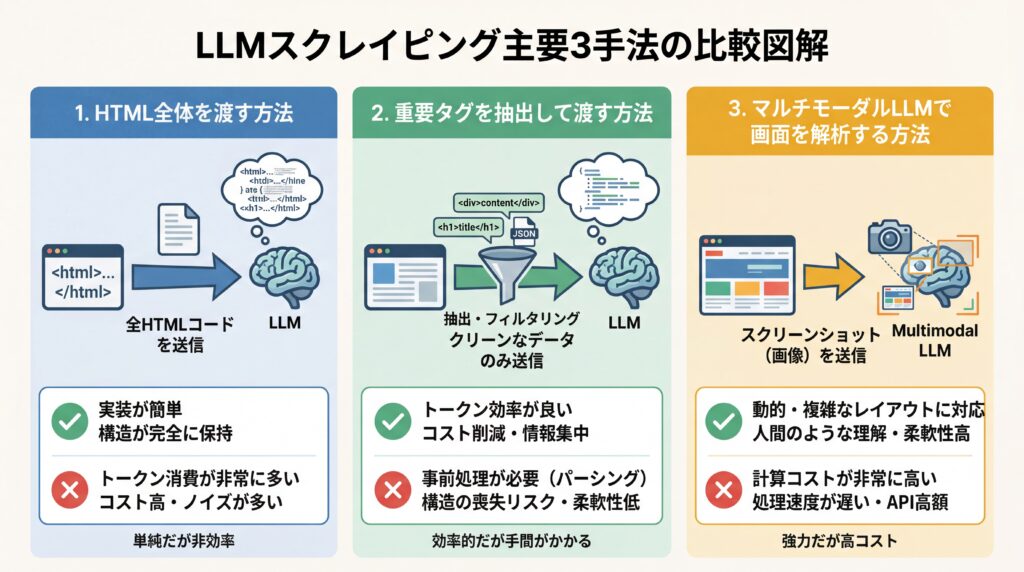
| 手法 | 概要 | メリット | デメリット |
|---|---|---|---|
| HTML全体を渡す | WebページのHTMLコンテンツ全体をLLMに入力し、必要な情報を抽出させる。 | 最もシンプルで実装が容易。ページの全情報を網羅的に解析できる。 | LLMのコンテキスト長を超える長大なページには不向き。ノイズが多く精度が落ちる場合がある。 |
| 重要タグを抽出して渡す | Beautiful Soupなどで主要なタグ(例:`<main>`, `<article>`)のみを抽出し、その部分だけをLLMに入力する。 | 不要な情報を削ぎ落とすため、LLMの処理負荷が減り、精度と速度が向上する。コンテキスト長の制約を回避しやすい。 | 事前のタグ選定が必要。選定を誤ると必要な情報が欠落するリスクがある。 |
| マルチモーダルLLMで画面を解析 | Webページのスクリーンショットを撮影し、画像認識が可能なマルチモーダルLLM(例:GPT-5, Gemini 2.5 Proなど)に解析させる。 | JavaScriptで動的に生成されるコンテンツや、HTML構造が複雑なサイトにも強い。人間が視覚的に認識する情報をそのまま抽出できます。 | テキスト情報が画像化されるため、コピー&ペーストができない。テキスト抽出に比べ、処理コストが高くなる傾向があります。 |
最も手軽なのはHTML全体を渡す方法ですが、精度を高めるためには、重要なタグに絞って情報を渡す前処理が有効です。また、近年進化が著しいマルチモーダルLLMを使えば、人間がブラウザで見る画面そのものを解析対象とすることができ、対応できるサイトの種類が大きく広がります。
【2026年】LLMスクレイピングにおすすめのツール・ライブラリ7選

本記事で紹介する情報は2025年11月時点のものです。LLMスクレイピングを実践するためのツールは、プログラミング不要で使えるものから、開発者が柔軟にカスタマイズできるライブラリまで、様々な選択肢が登場しています。自身のスキルレベルと目的に合ったツールを選ぶことが、成功への第一歩です。
ここでは、2025年現在、特におすすめできるツールやライブラリを「初心者向け」と「開発者向け」に分けて合計7つ紹介します。ここで紹介するツール群は、国内外の技術コミュニティでの議論や比較記事を参考に選定しています。(出典:AIを活用したWebスクレイピング手法とツールまとめ)それぞれの特徴を比較し、最適なものを見つけてください。
【初心者向け】手軽に始められるツール3選
プログラミングの知識がなくても、直感的な操作でLLMスクレイピングを始められるツールです。多くはブラウザ拡張機能やWebサービスとして提供されており、手軽に試すことができます。
| ツール名 | 特徴 | 料金目安(執筆時点の例) |
|---|---|---|
| Browse AI | ブラウザ操作を記録させるだけで、スクレイピングロボットを自動作成。LLMによるデータ解釈機能も統合。 | 無料プランあり。有料プランはStarterプランが月額$19〜など。 詳細は公式ページで最新価格をご確認ください。 |
| Octoparse | 豊富なテンプレートとポイント&クリックの簡単な操作性が魅力。AIが自動でページ構造を認識する機能も搭載。 | 無料プランあり。Standardプランが月額$89〜(年払い時)など。 最新情報は公式サイトでの確認が必要です。 |
| FireCrawl | URLを入力するだけで、AIがサイト全体をクロールし、構造化されたデータを自動で抽出。API経由での利用がメイン。 | 無料クレジットあり。従量課金制。 |
これらのツールは、定型的なデータ収集を素早く自動化したいマーケターや営業担当者におすすめです。まずは無料プランで使い勝手を試してみると良いでしょう。
【開発者向け】カスタマイズ性の高いライブラリ・フレームワーク4選
より複雑で大規模なデータ収集や、独自のアプリケーションへの組み込みを行いたい開発者向けの選択肢です。主にPythonのライブラリとして提供されています。
| ライブラリ名 | 特徴 | 主な用途 |
|---|---|---|
| LangChain | LLMアプリケーション開発のデファクトスタンダード。HTMLローダーやパーサーが豊富で、LLMと組み合わせたスクレイピング処理を柔軟に構築可能。 | 複雑なデータ抽出・加工パイプラインの構築。 |
| LlamaIndex | 非構造化データを取り込み、LLMが検索・対話できるようにするためのフレームワーク。Webページを取り込み、Q&Aシステムを構築する用途に強い。 | Webサイトの内容に関する質問応答システムの開発。 |
| Beautiful Soup + LLM API | 定番のHTML解析ライブラリ「Beautiful Soup」で必要な部分を抽出し、そのテキストをGPT-5などのLLM APIに渡して解析する古典的かつ強力な手法。 | 既存のスクレイピング処理にLLMの能力を追加。 |
| Scrapy + LLM | 大規模なクローリングに対応したフレームワーク「Scrapy」とLLMを連携。サイト全体を体系的に収集・解析するのに適している。 | 大規模サイトの網羅的なデータ収集と解析。 |
これらのライブラリを使いこなすことで、ビジネス要件に合わせたオーダーメイドのデータ収集システムを構築できます。特にLangChainは機能が豊富で、多くの開発者に支持されています。
法人向けAI研修
AX CAMP 無料資料
LLMスクレイピングを実践する基本ステップ
LLMスクレイピングを成功させるためには、計画的なアプローチが重要です。基本的には、「目的設定とツール選定」という準備段階と、「プロンプト設計から実行・検証」という実践段階の2つの大きなステップで進めます。
いきなりツールを使い始めるのではなく、まず何のためにデータを集めるのかを明確にすることが、後の工程をスムーズにし、最終的な成果の質を高めることに繋がります。
ステップ1:目的設定とツール選定
最初に、「何の情報を」「どのような目的で」収集するのかを具体的に定義します。例えば、「競合他社の新製品の価格とスペックを毎週リスト化し、マーケティング戦略の参考にしたい」といったレベルまで明確にしましょう。
目的が定まれば、おのずと必要なツールが見えてきます。簡単なリスト作成であれば初心者向けツールで十分ですし、収集したデータを自社のデータベースと連携させたいのであれば開発者向けライブラリの利用を検討します。目的とスキルレベルに応じて最適なツールを選ぶことが肝心です。
この段階で、対象サイトの利用規約やrobots.txtを必ず確認します。(出典:AI開発における要件定義の進め方) 特に個人情報が含まれる可能性がある場合、収集目的の明確化、必要最小限のデータ取得、保存期間の設定といった原則を遵守しなくてはなりません。技術的な安全管理措置や社内での取り扱い手順を定め、万が一の第三者提供時には本人の同意取得、あるいは匿名加工情報の活用を検討すべきです。国外のサーバーへデータを移転する際は、当該国の法制度も確認が必要です。これらの判断には専門知識が求められるため、事前に法務部門や個人情報保護の担当者と連携することを強く推奨します。
ステップ2:プロンプト設計から実行・検証
ツールの準備ができたら、LLMに指示を出すためのプロンプトを設計します。プロンプトは、LLMスクレイピングの精度を左右する最も重要な要素です。以下の点を意識すると、質の高いプロンプトを作成できます。
- 抽出したい項目を明確に指定
- 出力形式を指定(JSON, CSVなど)
- 役割を与える(例: 「あなたは優秀なデータアナリストです」)
- いくつかの例(Few-shot)を提示
例えば、「以下のHTMLから、製品名、価格、レビュー数をJSON形式で抽出してください」のように、具体的かつ明確に指示することがコツです。プロンプトが完成したら、実際にスクレイピングを実行し、得られたデータが想定通りかを確認します。もし精度が低い場合は、プロンプトを修正したり、前処理の方法を見直したりといった改善サイクルを回していくことが重要です。
AX CAMPの研修を受講されたWISDOM合同会社様の事例では、AI活用スキルを習得した結果、これまで採用2名分に相当した業務負荷をAIで代替することに成功しました。(出典:採用予定2名分の業務をAIが代替!WISDOM社、毎日2時間の調整業務を自動化) このように、正しいステップで実践スキルを身につけることが、大きな成果に繋がります。

LLMスクレイピングの注意点と法的リスク

LLMスクレイピングは非常に強力な技術ですが、その利用にはいくつかの注意点と法的なリスクが伴います。技術的な側面だけでなく、倫理的な配慮と法律の遵守を常に念頭に置く必要があります。これらを怠ると、トラブルに発展する可能性もあるため、十分に理解しておきましょう。
特に、Webサイト運営者への配慮、著作権、そして個人情報の取り扱いは、スクレイピングを行う上で必ず押さえておくべき重要なポイントです。
Webサイトへの配慮と利用規約の遵守
スクレイピングは、対象のWebサーバーにアクセスして情報を取得する行為です。短時間に大量のリクエストを送信すると、サーバーに過剰な負荷をかけてしまい、サイトの表示が遅くなったり、最悪の場合はサーバーダウンを引き起こしたりする可能性があります。これは「サービス妨害(DoS)」と見なされることもあるため、絶対に避けなければなりません。
対策として、プログラムに適切な待機時間(`sleep`処理など)を設け、人間がブラウジングするのと同程度のペースでアクセスすることがマナーです。また、多くのサイトでは`robots.txt`というファイルで、クローラーのアクセスを許可する範囲を指定しています。 スクレイピングを行う前には、必ずこのファイルを確認し、ルールを遵守しましょう。サイトの利用規約でスクレイピング自体が禁止されている場合は、原則として実施すべきではありません。
著作権・個人情報保護法などの法的リスク
Webサイト上のコンテンツ(文章、画像、動画など)は、基本的に著作権で保護されています。収集したデータを扱う際は、著作権法を遵守する必要があります。 特に以下の点に注意が必要です。
- 引用の要件:情報解析などの目的で一部を利用する場合でも、出典の明記、主従関係の明確化など、日本の著作権法が定める引用の要件を満たす必要があります。
- 営利目的の利用と再配布:収集したデータを営利目的で再配布したり、商用データベースとして販売したりする行為は、権利者からの許諾がなければ著作権侵害となる可能性が非常に高いです。
- 侵害のリスク:著作権を侵害した場合、差止請求や損害賠償請求の対象となるほか、場合によっては刑事罰が科される可能性もあります。
また、収集した情報に氏名、住所、メールアドレスなどの個人情報が含まれている場合は、個人情報保護法の規制対象となります。本人の同意なく第三者に提供したり、目的外で利用したりすることは固く禁じられています。データ収集の段階で、個人情報が含まれていないか、含まれている場合はどのように取り扱うかを慎重に検討する必要があります。
AXの支援事例によれば、株式会社グラシズ様はAI活用により、これまで3営業日かかっていたLP制作のライティングを2時間に短縮し、1本10万円の外注費を0円に削減しました。(出典:1本10万円のLPライティング外注費がゼロに!グラシズ社が「AIへの教育」に力を入れる理由とは?) このように、適切なガバナンスのもとで活用すれば、LLMは安全かつ強力な業務効率化ツールとなります。(参考:生成AIの未来とビジネスへの影響)

LLMやスクレイピングのスキルを実践的に学ぶならAX CAMP

LLMスクレイピングのような先進的な技術を自社の業務に活かし、競争力を高めていくためには、ツールの使い方を覚えるだけでなく、その背景にある技術や適切な活用戦略を体系的に学ぶことが不可欠です。しかし、「何から学べばいいかわからない」「自社の課題にどう応用できるのかイメージが湧かない」といった悩みを抱える企業は少なくありません。
もし貴社がAI活用を本格的に推進したいとお考えなら、法人向けAI研修サービス「AX CAMP」がその最短ルートを提案します。AX CAMPは、単なる知識の提供に留まらず、貴社の実務に直結する実践的なスキル習得を目的としたカリキュラムが特長です。
経験豊富なプロの講師が、LLMの基礎からプロンプトエンジニアリング、そしてスクレイピングのような具体的な業務自動化の技術まで、ハンズオン形式で丁寧に指導します。受講後には、自社の課題を自らAIで解決できる「AI推進人材」が育ち、全社的な生産性向上を実現できるでしょう。自社に合わせたAI活用の具体的なイメージを掴みたい方は、ぜひ一度、無料相談にお申し込みください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMスクレイピングでデータ収集を次世代レベルに進化させよう
本記事では、LLMスクレイピングの仕組みからメリット、具体的なツール、実践ステップ、そして法的な注意点までを網羅的に解説しました。最後に、重要なポイントを振り返ります。
- LLMスクレイピングとは:LLMの言語理解能力で、Webページの意味を解釈してデータを抽出する技術。
- 主なメリット:サイト構造の変更に強く、開発・メンテナンス工数を大幅に削減できる。
- 成功の鍵:目的に合ったツールを選定し、具体的で明確なプロンプトを設計すること。
- 注意点:サイトへの負荷に配慮し、利用規約や著作権、個人情報保護法を必ず遵守する。
LLMスクレイピングは、これまで多くの時間と労力を要していたデータ収集業務を劇的に効率化し、より高度なデータ分析への道を開く可能性を秘めています。この記事で紹介した手法やツールを活用し、貴社のデータドリブンな意思決定を加速させてみてはいかがでしょうか。
もし、「社内に専門家がおらず、自社だけでの導入は難しい」「より体系的に学び、確実に成果を出したい」とお考えであれば、AX CAMPが強力にサポートします。専門家の伴走支援のもと、記事で紹介したような施策を確実に実行し、データ収集業務の自動化を実現します。AI導入による業務効率化に関心のある方は、ぜひ下記の資料請求または無料相談をご検討ください。

法人向けAI研修
AX CAMP 無料資料