

「LLMの応答品質をさらに高めたいが、具体的にどうすれば良いのか」
「RLHFという言葉は聞くが、その仕組みが複雑でよくわからない」といった課題を抱えていませんか。大規模言語モデル(LLM)の性能を飛躍させる鍵として、現在
「強化学習」のアプローチが大きな注目を集めています。単に知識を詰め込むだけでなく、人間の意図や価値観に沿った、より自然で安全な応答を生成させるために不可欠な技術です。
この記事では、LLMにおける強化学習の基本概念から、中核技術であるRLHF(人間のフィードバックからの強化学習)の3ステップ、さらにはDPOやRLAIFといった2026年最新の代替手法まで、体系的に解説します。最後まで読むことで、自社サービスに搭載するLLMの品質を次のレベルへ引き上げるための具体的な道筋が見えるようになるでしょう。AI開発の最前線で何が起きているのか、その全体像を掴むためにもぜひご一読ください。貴社のAI戦略を加速させるヒントが、ここにあります。

法人向けAI研修
AX CAMP 無料資料
LLMと強化学習の組み合わせが注目される背景

大規模言語モデル(LLM)に強化学習が応用される背景には、モデルの応答を人間の意図や価値観と一致させる「アライメント」の必要性が高まっていることがあります。従来の学習手法だけではこの課題の解決が難しく、より高度な制御技術として強化学習の活用が進んでいるのです。
LLMにおける「アライメント問題」とは
LLMにおけるアライメント問題とは、モデルの応答が人間の意図や社会的な価値観と一致しない状態を指します。 具体的には、不正確な情報(ハルシネーション)や有害なコンテンツを生成したり、ユーザーの指示とはかけ離れた回答を返してしまったりする問題です。この問題は、LLMを社会で安全かつ有効に活用する上での大きな障害となります。
アライメントが不十分なLLMは、ビジネス利用において予期せぬリスクを生み出しかねません。例えば、顧客対応チャットボットが不適切な発言をしたり、マーケティングコピーが誤解を招く表現を生成したりするケースが考えられます。こうしたリスクを抑制し、LLMを社会に実装するためには、適切なアライメントの向上が不可欠です。
従来の学習手法だけでは不十分な理由
従来のLLM開発で中心だった「教師あり学習(Supervised Learning)」だけでは、アライメント問題を完全に解決するには不十分です。教師あり学習は、あらかじめ用意された正解データを元に学習を進めますが、人間の持つ多様な価値観や文脈に応じた細かなニュアンスを、すべてデータ化することは極めて困難だからです。
例えば、「丁寧な文章」という指示一つとっても、ビジネスメールと友人へのメッセージでは求められる丁寧さが異なります。このような無数の状況に対応できる「正解」を網羅したデータセットの作成は現実的ではありません。そこで、試行錯誤を通じてより良い応答を自ら学習する「強化学習」のアプローチが必要とされているのです。


LLMにおける強化学習とは?基本概念を解説

LLMにおける強化学習とは、生成するテキストを「行動」とみなし、その品質に応じて「報酬」を与えることで、より良い文章を生成できるようにモデルを訓練する手法です。このプロセスは、AIが試行錯誤を繰り返しながら目標達成のための最善の行動を見つけ出す枠組みであり、マルコフ決定過程(MDP)という数学的モデルを用いて捉えられます。
強化学習(RL)の基本的な仕組み
強化学習(Reinforcement Learning, RL)は、主に以下の4つの要素から構成される機械学習の一手法です。
- エージェント:学習する主体(LLM本体)
- 環境:エージェントが相互作用する対象(対話の文脈など)
- 行動:エージェントが環境に対して行う操作(テキストの生成)
- 報酬:行動の結果として環境から得られる評価(人間のフィードバック)
エージェントは現在の「状態」を観測し、何らかの「行動」を選択します。その結果、環境から「報酬」と次の「状態」が与えられます。このサイクルを繰り返しながら、エージェントは将来にわたって得られる累積報酬を最大化するような行動選択の方針(方策)を学習します。この仕組みにより、明確な正解データがないタスクでも、試行錯誤を通じて最適な振る舞いを獲得できるのです。
テキスト生成をマルコフ決定過程として捉える
LLMのテキスト生成プロセスは、「マルコフ決定過程(Markov Decision Process, MDP)」としてモデル化できます。これは、強化学習の理論的な基盤となる考え方であり、具体的には以下のように対応づけられます。
- 状態:それまでに出力されたテキスト
- 行動:次に出力する単語(トークン)の選択
- 報酬:生成されたテキスト全体に対する評価
- 方策:現在のテキスト(状態)に対し、次にどの単語(行動)を選ぶかの確率分布
LLMは、単語を一つずつ選択して文章を生成します。各時点での単語選択が「行動」であり、それによって文章(状態)が変化していくのです。最終的に生成された文章全体に報酬が与えられ、モデルはその報酬を最大化するように、各状態での単語選択の確率(方策)を更新していきます。このように捉えることで、テキスト生成という複雑なタスクを強化学習の枠組みで最適化できるようになります。

LLMに強化学習を適用する主要メリット
LLMに強化学習を適用する最大のメリットは、人間の複雑な好みや価値観をモデルに反映させ、より高品質で安全な応答を生成できる点にあります。これにより、単なる正誤だけでなく「より自然か」「より丁寧か」といった主観的な基準に沿ったチューニングが可能になり、ユーザーの意図を汲み取った応答精度が向上します。
具体的なメリットは以下の通りです。
- 応答品質の向上
- 安全性と倫理性の確保
- ハルシネーションの抑制
- 対話能力の継続的改善
強化学習を通じて、モデルは人間のフィードバックから学習し、より人間らしく自然な対話を実現します。例えば、曖昧な指示に対しても意図を正確に理解し、文脈に沿った適切な応答を返す能力が向上するため、カスタマーサポートなど実用的な場面での効果が期待できます。
さらに、不適切または有害なコンテンツの生成を抑制するように学習させることで、モデルの安全性と倫理性を大幅に高めることができます。また、事実に基づかない情報を生成するハルシネーションも、人間のフィードバックに基づき事実との整合性を高めるよう報酬を設計することで、抑制する効果が期待できます。ただし、この報酬設計は非常に繊細であり、不適切な設計はかえって性能を不安定にさせるリスクも伴う点には注意が必要です。

LLM強化学習の中核技術「RLHF」の仕組み
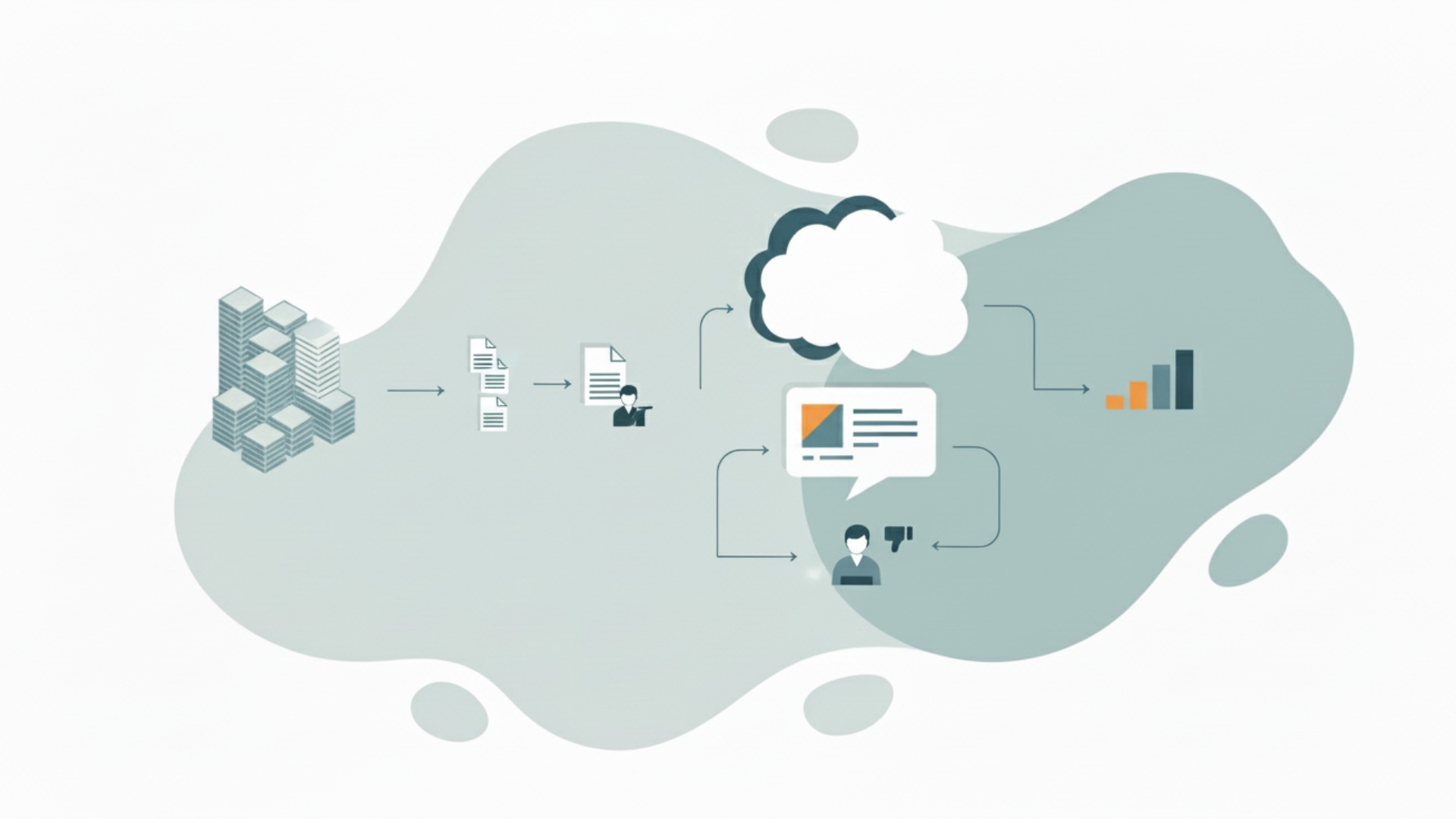
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを活用してLLMを強化学習させる、代表的な3段階のプロセスです。この手法の目的は、人間の主観的な好みや価値観をモデルに学習させ、より自然で有用な応答を生成できるように最適化することにあります。ChatGPTなどの高性能な対話AIも、このRLHFを用いることでユーザーフレンドリーな応答能力を獲得しました。
ステップ1:教師ありファインチューニング(SFT)
最初のステップは、高品質な手動データを用いてベースとなるLLMを微調整(ファインチューニング)することです。この段階は教師ありファインチューニング(Supervised Fine-Tuning, SFT)と呼ばれます。
ここでは、人間が作成した質の高い「指示(プロンプト)」と「模範的な応答」のペアからなるデータセットを用意します。モデルはこのデータセットを学習することで、特定のタスク(対話、要約など)の基本的な形式や応答スタイルを習得します。このSFTモデルが、後続の強化学習プロセスの出発点となるのです。
ステップ2:報酬モデル(RM)の学習
次に、人間の好みを学習する「報酬モデル(Reward Model, RM)」を構築します。このステップでは、まずSFTモデルに同じプロンプトを複数回入力し、いくつかの異なる応答を生成させます。
続いて、人間(アノテーター)がそれらの応答を比較し、「最も良いもの」から「最も悪いもの」までランキング付けします。この「プロンプト」と「人間のランキング付き応答データ」を教師データとして、報酬モデルを学習させます。学習後の報酬モデルは、任意の応答を入力すると、人間がどれくらい好むかを予測するスコア(報酬)を出力できるようになります。
ステップ3:PPOによる方策の最適化
最終ステップでは、報酬モデルを使ってLLM本体(方策モデル)を強化学習で最適化します。ここで広く使われるアルゴリズムがPPO(Proximal Policy Optimization)です。
具体的な流れは以下の通りです。まず、SFTモデルに任意のプロンプトを入力し、応答を生成させます。生成された応答をステップ2で作成した報酬モデルに入力し、報酬スコアを計算します。この報酬スコアを最大化するように、PPOアルゴリズムがLLMのパラメータを更新します。 この際、元のモデルから性能が大きく逸脱しないよう調整する仕組み(KLペナルティなど)も組み込まれており、学習の安定化に重要な役割を果たします。(出典:Training language models to follow instructions with human feedback) このプロセスを繰り返すことで、LLMは徐々に人間が好むような、より高品質な応答を生成する能力(方策)を獲得していきます。

RLHFを支える人間からのフィードバック収集方法

RLHFの成功は、質の高い人間のフィードバックを効率的に収集する仕組みに依存します。最も一般的な方法は、複数のAI生成応答を人間が比較し、ランキング付けする形式です。この手法により、絶対的な評価が難しい「自然さ」や「面白さ」といった主観的な基準でも、相対的な優劣としてデータ化できます。
フィードバック収集の具体的なプロセスは、以下の通りです。
- 多様なプロンプトの準備
- モデルによる複数応答の生成
- 人間によるランキング付け
- 選好データセットの構築
まず、多様なプロンプトをLLMに入力して複数の応答候補を生成させます。次に、アノテーターと呼ばれる評価者が、ガイドラインに基づきこれらの応答を比較し、「AよりBが良い」といった形で順位付けを行います。この選好データが、報酬モデルを学習させるための貴重な教師データとなるのです。
フィードバックの質と一貫性を担保するためには、明確な評価ガイドラインの策定と、評価者への十分なトレーニングが不可欠です。また、評価者の主観による偏りを減らすため、複数の評価者によるレビューや、多様なバックグラウンドを持つ人材の登用も重要となります。収集されたデータは、LLMの性能を人間の価値観に沿って方向付けるための羅針盤となります。
https://media.a-x.inc/llm-evaluation【2026年最新】RLHFを超える新たな強化学習手法

2025年現在、RLHFの複雑さやコストといった課題を克服するため、新たな手法が次々と登場しています。中でもDPO(Direct Preference Optimization)とRLAIF(Reinforcement Learning from AI Feedback)は、より効率的にLLMを人間の好みに近づけるアプローチとして大きな注目を集めています。
DPO(Direct Preference Optimization)
DPO(Direct Preference Optimization)は、RLHFのプロセスを大幅に簡略化する新しいファインチューニング手法です。RLHFが「報酬モデルの学習」と「強化学習」という2段階のプロセスを必要とするのに対し、DPOは人間の選好データから直接LLMを最適化します。(出典:Direct Preference Optimization: Your Language Model is Secretly a Reward Model)
この手法の最大の特長は、報酬モデルを明示的に学習する必要がない点です。 これにより、学習プロセスがシンプルになり、調整も容易になります。結果として、RLHFで課題となりがちだった学習の不安定さを解消しやすく、有力な代替手法として多くのモデルで採用が進んでいます。 ただし、全てのタスクでRLHFを上回るわけではなく、用途に応じた使い分けが依然として重要です。
RLAIF(Reinforcement Learning from AI Feedback)
RLAIF(Reinforcement Learning from AI Feedback)は、フィードバックを生成する人間を、別の高性能なAIモデルに置き換えるアプローチです。RLHFにおける人間によるフィードバック収集は、時間とコストがかかるボトルネックでした。RLAIFは、このプロセスを自動化することで、スケーラビリティを大幅に向上させることを目的としています。(出典:Constitutional AI: Harmlessness from AI Feedback)
具体的には、まず「憲法」と呼ばれる一連の原則(例:「無害な応答を心がける」)をAIに与えます。 そして、LLMが生成した複数の応答に対し、この憲法に基づいてAIがランク付けを行います。このAIによるフィードバックデータを用いて、RLHFと同様のプロセスで学習を進めます。 この手法により、人間への依存を減らし、より大規模かつ高速なアライメント調整が可能になると期待されています。

LLMの強化学習で利用される主要ライブラリ

LLMの強化学習を実装する際は、専門的なライブラリを活用するのが一般的です。これらのライブラリは、RLHFやDPOなどの複雑なプロセスを効率的に実行するための機能を提供します。代表的なものに、Hugging Faceが開発するTRL(Transformer Reinforcement Learning)があり、多くの開発者に利用されています。
主要なライブラリとその特徴は以下の通りです。
- TRL (Transformer Reinforcement Learning):Hugging Faceのエコシステムと緊密に連携しており、現在最も広く利用されている代表的なライブラリの一つです。
- RL4LMs:言語モデルの強化学習アルゴリズムに特化した研究用途のライブラリです。
- Acme:GoogleのDeepMindが開発した、大規模な分散学習に対応できる汎用的な強化学習フレームワークです。
- Ray RLlib:スケーラビリティを重視した分散機械学習ライブラリであり、複雑な強化学習タスクを効率的に実行できます。
特にTRLは、SFT、報酬モデルの学習、PPOによる最適化といったRLHFの各ステップをサポートするクラスが用意されています。DPOの実装にも対応しており、Transformerベースのモデルを手軽に強化学習でファインチューニングしたい場合に有力な選択肢となります。(出典:DPOTrainer – Hugging Face TRL)
https://media.a-x.inc/llm-open-sourceLLMへの強化学習導入における課題と今後の展望

LLMへの強化学習導入は性能向上に大きく貢献する一方、いくつかの課題も抱えています。最大の課題は、高品質なフィードバックデータを収集するための膨大なコストです。特にRLHFでは、人間による評価に多大な時間と費用がかかり、これが開発のボトルネックとなるケースが多く見られます。
その他の主な課題としては、以下が挙げられます。
- 報酬設計の難しさ
- 学習プロセスの不安定性
- 評価の客観性担保
- アライメント税(Alignment Tax)
人間の意図を正確に反映する報酬モデルの設計は非常に繊細な作業です。また、PPOなどの強化学習アルゴリズムは調整が難しく、学習が不安定になりやすい性質があります。 さらに、アライメントを強化しすぎると、モデルが本来持っていた知識や性能が劣化してしまう「アライメント税」と呼ばれる現象も報告されています。
今後の展望としては、これらの課題を解決する新しい技術への期待が高まっています。RLAIFのようにAIによるフィードバック生成を自動化する研究や、DPOのようによりシンプルで安定した学習手法の開発が活発に進められています。 より客観的で頑健な評価軸を確立する試みが、今後の重要なテーマとなるでしょう。

LLMの強化学習を実践的に学ぶならAX CAMP

LLMの強化学習に関する理論や最新手法を理解した上で、次に重要となるのは「いかにして自社のビジネス課題に適用し、成果に繋げるか」という実践的な視点です。RLHFやDPOといった技術は、単に知っているだけでは価値を生みません。具体的な業務プロセスに組み込み、チューニングを重ねて初めて、その真価を発揮します。
しかし、社内にAIの専門家がいない、何から手をつければ良いかわからない、といった課題を抱える企業様は少なくありません。そこで私たちAX CAMPでは、AI人材育成から業務への実装までをワンストップで支援する法人向け研修サービスを提供しています。机上の空論で終わらない、実務直結のカリキュラムが最大の特長です。
AX CAMPでは、貴社の具体的な課題をヒアリングした上で、最適なLLMの活用法やファインチューニング戦略を共に考えます。例えば、SNSマーケティングの投稿文生成を自動化したい、コールセンターの応対品質を向上させたい、といったニーズに対し、専門知識を持つプロの講師が伴走しながら、システムの企画から内製化までをサポートします。
実際にAX CAMPを導入された企業様からは、具体的な成果報告が数多く寄せられています。例えば、WISDOM合同会社様は、本研修を通じて開発したAIの活用により「採用担当者2名分の業務負荷に相当する工数を削減できた」という大きな成果を上げています。(出典:採用予定2名分の業務をAIが代替!WISDOM社、毎日2時間の調整業務を自動化 – note) このように、AI活用による業務効率化の成功事例が生まれています。LLMの強化学習を自社の競争力に変えたいとお考えなら、まずは無料の資料請求から、具体的な支援内容をご確認ください。※記載の事例は個社様のものであり、成果を保証するものではありません。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMの強化学習を理解し性能を飛躍させよう
本記事では、大規模言語モデル(LLM)の性能を向上させるための強化学習について、その背景から中核技術であるRLHF、そしてDPOやRLAIFといった最新手法までを網羅的に解説しました。LLMが人間の意図や価値観に沿った高品質な応答を生成するためには、強化学習によるアライメント調整が不可欠です。
この記事の重要なポイントを以下にまとめます。
- アライメント問題:LLMが人間の意図とずれた応答をする問題であり、強化学習が解決の鍵となる。
- RLHF:人間のフィードバックを用いて「報酬モデル」を学習し、LLMを最適化する中核技術。
- 最新手法:RLHFの課題を克服するため、よりシンプルなDPOや、AIがフィードバックを行うRLAIFが登場している。
- 実践の課題:高品質なデータ収集コストや学習の不安定性など、導入には専門的な知識とノウハウが必要。
これらの技術を正しく理解し活用することで、LLMは単なる文章生成ツールから、ビジネス課題を解決する強力なパートナーへと進化します。しかし、理論の理解と実践の間には大きな壁が存在するのも事実です。
もし、貴社が「LLMを自社業務に導入したいが、何から始めるべきかわからない」「専門家のアドバイスを受けながら、着実に成果を出したい」とお考えであれば、AX CAMPの法人向けAI研修・伴走支援サービスが力になります。専門家による実践的なサポートを通じて、本記事で紹介したような高度なAI技術を貴社の競争力へと転換させませんか。まずは無料相談にて、貴社の課題をお聞かせください。

法人向けAI研修
AX CAMP 無料資料