

大規模言語モデル(LLM)の性能を根幹から支える「事前学習」。この言葉を耳にしたことはあっても、その複雑な仕組みやビジネスへのインパクトを具体的に説明できる方は少ないかもしれません。LLMの能力を最大限に引き出し、自社の課題解決に応用するためには、その心臓部である事前学習への深い理解が不可欠です。
この記事では、LLMの事前学習について、その重要性から具体的な5つのステップ、最新の技術トレンドまでを網羅的に解説します。エンジニアや研究者だけでなく、AI導入を推進するビジネスリーダーの方にもご理解いただけるよう、専門的な内容を分かりやすく紐解いていきます。最後までお読みいただくことで、LLM開発の勘所を掴み、自社におけるAI活用戦略をより具体的に描けるようになるでしょう。AI活用のヒントが詰まったお役立ち資料もご用意していますので、ぜひご活用ください。

法人向けAI研修
AX CAMP 無料資料
LLMにおける事前学習の重要性とは?
結論:LLMにおける事前学習は、モデルの汎用的な性能を決定づける最も重要な工程です。非常に大規模なテキストデータ(コーパス)を用いて、言語の構造や文法、一般的な知識、さらには推論能力といった基礎的な能力をモデルに教え込むプロセスを指します。この段階を経ることで、LLMは特定のタスクに限定されない、汎用的な言語理解・生成能力を獲得するのです。
人間が長年の読書や会話を通じて世界の知識や言語ルールを学んでいくように、LLMも事前学習によって膨大な情報から言語のパターンを吸収します。例えば、初期の大規模モデルであるGPT-3では、45TBものテキストデータが学習に用いられたと言われています。このような膨大なデータとの接触が、人間のような自然な対話を可能にする基盤を形成しているわけです。
ただし、事前学習には膨大な計算リソースと高品質なデータが不可欠です。使用するデータの質がモデルの性能だけでなく、公平性や倫理的な課題に繋がる潜在的なバイアス(偏見)にも直結するため、データセットの選定とクリーニングは極めて慎重に行われます。この基盤となる能力を事前学習で築き上げるからこそ、その後のファインチューニング(微調整)によって、多様な専門分野やビジネス用途に迅速に対応できるのです。

事前学習を支えるLLMの基本構造
現代のLLMの性能を支えているのは、「Transformer(トランスフォーマー)」と呼ばれるニューラルネットワークモデルです。2017年にGoogleの研究者たちが発表した論文『Attention Is All You Need』で登場して以来、自然言語処理の分野に革命をもたらしました。Transformerモデルの登場以前は、RNN(再帰型ニューラルネットワーク)などが主流でした。RNNは文を順番に処理するため、長い文章の文脈を捉えにくいという課題がありましたが、Transformerはこの課題を見事に解決したのです。
Transformerモデルの仕組みと役割
Transformerモデルは、主に入力テキストを処理する「エンコーダー」と、出力テキストを生成する「デコーダー」の2つの部分から構成されます。このモデルの最大の特徴は、文章を単語などのトークンに分割し、それらを順番に処理するのではなく、並列で一括処理できる点にあります。これにより、GPUなどのハードウェア性能を最大限に活用し、従来モデルよりも高速な学習を実現しました。(出典:Transformerとは? 仕組みやメリットを初心者向けにわかりやすく解説)
そして、この並列処理と高精度な文脈理解を両立させているのが、次に説明する「Attention機構」です。
Attention機構がもたらしたブレークスルー
Attention機構(アテンション機構)は、その名の通り、文章中のどの単語に「注意(Attention)」を向けるべきかを学習する仕組みです。文章内のすべての単語間の関連性の強さを数値化し、文脈を理解する上で特に重要な単語やフレーズを動的に特定します。
例えば、「川の土手(bank)に座る」と「銀行(bank)にお金を預ける」という2つの文があった場合、人間は文脈から “bank” の意味を区別できます。Attention機構は、これと同様の働きをAIに持たせるものです。「川」や「土手」という単語との関連性が強いと判断すれば前者の意味を、「お金」や「預ける」との関連性が強ければ後者の意味を重視するようになります。
このブレークスルーにより、LLMは単語の表面的な意味だけでなく、文脈に応じた複雑なニュアンスまでを捉えられるようになり、翻訳や要約、対話などのタスクで飛躍的な精度向上を達成したのです。まさにTransformerモデルの心臓部と言える技術です。
https://media.a-x.inc/llm-architecture
LLM事前学習の具体的なプロセス【5ステップで解説】
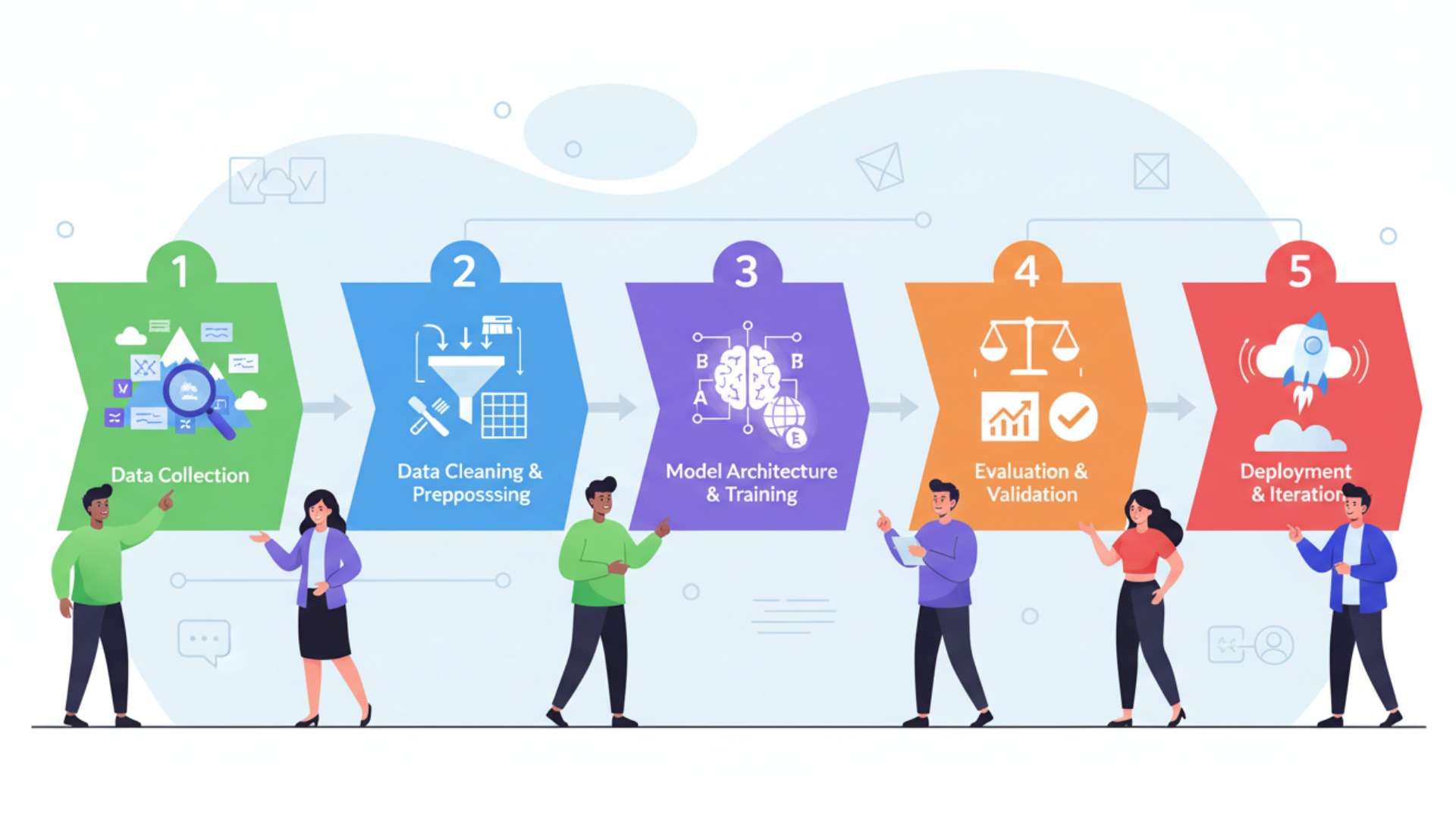
LLMの事前学習は、無計画に行われるわけではなく、体系化されたプロセスに沿って進められます。その工程は、大きくデータ収集からモデル評価までの5つのステップに分けることができます。この一連の流れを理解することで、LLMがどのようにして高い言語能力を獲得するのか、その全体像を掴むことができます。
ステップ1-2:データ収集から前処理まで
最初のステップは、学習の元となる膨大なテキストデータを収集することから始まります。Webサイト、書籍、論文、ソースコードなど、インターネット上に存在する多種多様なテキストが収集対象となります。このデータの量と多様性が、モデルの汎用性を決定づける重要な要素です。(出典:NII、最大1720億パラメータの日本語LLMを開発・公開)
次に、収集した生データを学習に適した形に整える「前処理」を行います。これには、HTMLタグなどの不要な情報の除去(クリーニング)、そして文章を単語やサブワードといった「トークン」に分割するトークン化などが含まれます。特に個人情報や機密情報の取り扱いには細心の注意が払われ、不可逆的なハッシュ化やk-匿名性といった手法を用いて厳密にマスキングされます。データ品質がモデルの性能に直結するため、この前処理は極めて重要な工程です。
ステップ3-5:モデル選定から評価まで
データが準備できたら、次はモデルのアーキテクチャ選定です。近年は特定のタスクに特化したモデルよりも、多様なタスクをこなせる汎用的な大規模モデルが主流となっています。その上で、目的に応じてTransformerベースの最適なアーキテクチャやサイズを選定します。(出典:生成AI(ジェネレーティブAI)とは?仕組み、種類、代表的なサービス、活用事例を解説)
そして、いよいよ学習の実行です。準備したデータとモデルを使い、目的関数(学習の目標)を設定して、膨大な数のGPUやTPUが搭載された計算クラスターで学習を開始します。この工程には、数週間から数ヶ月単位の時間と莫大な計算コストがかかります。(出典:大規模言語モデル (LLM) とは)
最後のステップが、学習済みモデルの評価です。パープレキシティ(Perplexity)といった指標を用いて、モデルがどれだけ自然な文章を生成できるかを定量的に評価します。また、様々な下流タスク(翻訳、要約、質疑応答など)を解かせて、その汎用的な性能を確認し、事前学習プロセスは完了となります。(出典:大規模言語モデルの評価指標に関する研究動向)
https://media.a-x.inc/llm-train
LLMの事前学習における主要な目的関数

LLMがテキストデータから言語を学習する際の「目標設定」にあたるのが目的関数です。事前学習で用いられる目的関数は、主に「自己回帰モデル」と「マスク化言語モデル」の2種類に大別されます。これらは学習方法が異なり、それぞれ得意なタスクも異なります。
自己回帰モデル(Causal Language Modeling)
自己回帰モデルは、「次に来る単語を予測する」というタスクを繰り返し解くことで言語を学習します。例えば、「今日の天気は」という文が与えられたら、「晴れ」や「曇り」といった続きの単語を予測するように学習を進めていきます。このプロセスを膨大なデータで繰り返すことで、文法や単語の繋がり、文脈の流れを習得するのです。
この方式の代表例が、OpenAIのGPTシリーズです。文章を左から右へと生成していくため、対話システムや文章生成といったタスクで非常に高い性能を発揮するのが特徴です。(出典:GPTの仕組み)
マスク化言語モデル(Masked Language Modeling)
一方、マスク化言語モデル(MLM)は、文章中の一部の単語を意図的に隠し(マスクし)、その隠された単語が何であったかを予測するタスクを解きます。例えば、「私は[MASK]でご飯を食べる」という文の[MASK]部分を、前後の文脈(「私」「ご飯を食べる」)から「レストラン」と予測するように学習します。
この手法の利点は、単語の予測にあたって文の前後両方の文脈を同時に考慮できる点です。そのため、文全体の意味を深く理解する能力に長けており、文章の分類や感情分析、固有表現抽出といったタスクで優れた性能を示します。代表的なモデルとしては、Googleが開発したBERTが挙げられます。(出典:生成AI(ジェネレーティブAI)とは?仕組み、種類、代表的なサービス、活用事例を解説)

【2026年時点】LLM事前学習のトレンドと課題
LLMの事前学習に関する研究は日々進化しており、現在のトレンドは「効率化」と「継続性」という2つのキーワードに集約されます。モデルの性能向上はもちろんのこと、いかに効率良く、そして最新の情報を反映させ続けるかが重要なテーマとなっています。
効率化とデータ品質の向上
LLMの性能はモデルのパラメータ数やデータ量に比例して向上するとされてきましたが、それに伴う計算コストの増大が大きな課題でした。そのため、近年ではモデルの性能を維持したまま計算効率を高める研究が活発です。具体的には、専門分野ごとに小さな専門家モデルを連携させる「MoE(Mixture of Experts)」のようなアーキテクチャや、モデルの軽量化技術(蒸留、量子化)などが注目されています。
また、単にデータの「量」を増やすだけでなく、「質」を徹底的に追求する動きも加速しています。ノイズの少ない高品質なデータセットを構築する「データセントリックAI」という考え方が主流になりつつあり、学習効率とモデル性能の両方を向上させる鍵として重要視されています。
継続的な事前学習(Continual Pre-training)という新潮流
一度事前学習を終えたモデルは、その時点までの知識しか持っていません。しかし、世の中の情報は日々更新されます。この課題を解決するのが「継続的な事前学習(Continual Pre-training)」という新しいアプローチです。
これは、既存の学習済みモデルに対して、新しい知識や特定の専門分野のデータを追加で学習させる手法です。ゼロから巨大なモデルを再学習させるのに比べてはるかに低コストでモデルの知識を最新の状態に保てるため、非常に効率的です。例えば、最新の法律や医療情報を学習させることで、モデルを特定のドメインに特化させることができます。
ただし、新しい知識を学ぶ際に古い知識を忘れてしまう「破滅的忘却」という課題も存在し、これをいかに克服するかが今後の研究の焦点となっています。

事前学習済みモデルのビジネス活用事例
事前学習によって汎用的な言語能力を獲得したLLMは、特定の業務に合わせてファインチューニング(微調整)を施すことで、様々なビジネスシーンで活用されています。実際に、AX CAMPの研修や伴走支援を導入いただいた企業様では、業務効率化やコスト削減といった具体的な成果が生まれています。
グラシズ様の事例
リスティング広告運用を手掛けるグラシズ様では、AIツールの活用に組織的な課題を抱えていました。AX CAMPの研修を通じてLP(ランディングページ)制作の内製化に取り組み、これまで外部に依頼していたLP外注費10万円を0円に削減することに成功しました。(出典:【2024年版】LLMのビジネス活用事例10選!業務効率化の具体例を解説)
WISDOM社様の事例
SNS広告やショート動画制作を行うWISDOM社様では、AX CAMPの研修プログラムを導入し、業務の自動化を推進しました。その結果、これまで採用予定だった2名分の業務をAIが代替し、毎日発生していた2時間もの調整業務を完全に自動化することに成功しています。(出典:採用予定2名分の業務をAIが代替!WISDOM社、毎日2時間の調整業務を自動化|ぶんた@株式会社AX CEO)
企業名非公開様の事例
特定の担当者のスキルに業務成果が大きく依存し、属人化してしまっているという課題がありました。AX CAMPの伴走型支援プログラムを導入し、現場でAIを活用する文化を醸成。結果として、業務の標準化と効率化を実現し、属人化のリスクを解消しました。(出典:【2024年版】LLMのビジネス活用事例10選!業務効率化の具体例を解説)
https://media.a-x.inc/llm-use-cases
実践的なLLM活用スキルを学ぶならAX CAMP

LLMの事前学習をはじめとする技術的な仕組みを理解することは、AIの可能性を正しく評価し、ビジネス活用の方向性を定める上で非常に重要です。しかし、理論を学ぶだけでは、現場の具体的な業務課題を解決し、成果に繋げることは難しいのが実情です。本当に必要なのは、その知識を実務に落とし込む「実践力」です。
もし、貴社が「LLMを自社の業務にどう活かせばいいか分からない」「AI導入プロジェクトを推進できる人材がいない」といった課題をお持ちであれば、ぜひ一度、弊社の「AX CAMP」をご検討ください。AX CAMPは、単なる知識提供型の研修ではありません。実務直結のカリキュラムと専門家による伴走支援を通じて、AIを“使える”人材を育成する実践的なプログラムです。
AX CAMPでは、LLMの基礎から応用、さらにはプロンプトエンジニアリングや自社データとの連携方法まで、貴社の課題に合わせてカスタマイズした内容で学ぶことができます。研修で学んだことをすぐに実際の業務で試し、改善していくサイクルを回すことで、現場で着実に成果を出せるスキルが身につきます。自社でのAI活用を本気で成功させたいとお考えなら、ぜひ私たちにご相談ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMの事前学習を理解し、AI開発の高度化を目指そう
本記事では、LLMの性能の根幹をなす「事前学習」について、その重要性から基本構造、具体的なプロセス、そして最新トレンドまでを解説しました。LLMがいかにして高度な言語能力を獲得しているのか、その仕組みをご理解いただけたのではないでしょうか。
この記事の要点を以下にまとめます。
- 事前学習は、LLMに汎用的な言語能力を与えるための最も重要な工程である。
- その技術的基盤には、Attention機構を搭載したTransformerモデルが存在する。
- 学習プロセスはデータ収集から前処理、学習、評価まで体系化されている。
- 最新トレンドは計算効率の向上と、知識を更新し続ける継続的な事前学習にある。
これらの理論的知識を実際のビジネス成果に繋げるためには、専門的な知見と実践的なノウハウが不可欠です。LLMのポテンシャルを最大限に引き出し、競合優位性を確立するためには、自社の課題に即した戦略的なアプローチが求められます。
AX CAMPでは、本記事で解説したようなLLMの技術的背景を踏まえ、貴社のビジネスに特化したAI活用戦略の策定から人材育成までをワンストップで支援します。専門家の伴走サポートにより、AI導入プロジェクトを確実に成功へと導きます。AI活用に関する具体的なご相談や、研修プログラムの詳細については、お気軽にお問い合わせください。

法人向けAI研修
AX CAMP 無料資料