

LLM(大規模言語モデル)とニューラルネットワークの関係性について、その仕組みや違いが分からず悩んでいませんか。AI技術の進化は著しく、ビジネス活用の可能性が広がる一方で、その核心を理解するのは容易ではありません。これらの技術の基礎を正しく把握しなければ、自社に最適なAI導入戦略を立てることは困難です。
LLMは、人間の脳の神経回路を模した「ニューラルネットワーク」という技術を基盤として機能するAIの一種です。この記事を読めば、LLMとニューラルネットワークの基本的な関係性から、最新のAIモデル動向、具体的なビジネス活用事例まで、網羅的に理解できます。技術の仕組みを知ることで、自社の課題解決に向けたAI活用の具体的なイメージが湧くはずです。
AIの導入や活用に関する具体的な進め方や、自社の状況に合わせた最適な活用法を知りたい方のために、AX CAMPでは関連資料を無料で提供しています。ぜひ貴社のAI戦略策定にお役立てください。

法人向けAI研修
AX CAMP 無料資料
LLM(大規模言語モデル)とは?ニューラルネットワークが核となるAI
LLM(Large Language Models)とは、人間の脳神経の仕組みを模した「ニューラルネットワーク」を基盤に持つ、巨大な言語処理に特化したAIを指します。膨大なテキストデータを学習することで、人間のように自然な文章を生成したり、文脈を理解して対話したりする能力を獲得します。この技術が、ChatGPTなどの対話型AIサービスの根幹を支えているのです。
LLMの基本定義と「大規模」である理由
LLMが「大規模」と呼ばれる理由は、主に2つの側面にあります。1つ目は、学習に用いるデータセットの膨大さです。インターネット上のWebサイト、書籍、論文など、人間が生成した膨大な量のテキストデータを読み込ませます。2つ目は、モデルの複雑さを示すパラメータ数の巨大さです。パラメータとは、ニューラルネットワーク内の情報の重み付けを調整する変数であり、この数が多いほど、より複雑で繊細な言語のニュアンスを学習できます。最新のモデルでは、パラメータ数が数千億から数兆に達するものもあります。
文脈を理解する革新性:従来の言語モデルとの違い
LLMの革新性は、単語の表面的な関係だけでなく、文脈を深く理解する能力にあります。従来の言語モデルは、単語の出現頻度や前後の単語との関係性など、比較的短い範囲の情報しか扱えませんでした。そのため、長文になると文脈が途切れたり、話の辻褄が合わなくなったりすることが頻繁にありました。
一方で、LLMは「Transformer」というニューラルネットワークの仕組みを用いることで、文章全体の構造や単語同士の長期的な依存関係を捉えることが可能です。これにより、人間が書いたかのような自然で論理的な文章を生成できるだけでなく、質問応答、翻訳、要約といった高度なタスクを高い精度で実行できるのです。この点が、ビジネスにおける応用範囲を飛躍的に広げました。



LLMと関連技術の違いを整理

LLMを正しく理解するためには、生成AIや機械学習、NLP(自然言語処理)といった関連技術との関係性を把握することが重要です。これらの技術は階層構造になっており、それぞれの位置付けを知ることで、LLMがAI技術全体の中でどのような役割を果たしているのかが明確になります。
生成AI・機械学習との関係性:技術階層で理解する
AI技術は、広い概念から順に「機械学習」「生成AI」「LLM」という階層で整理できます。それぞれの関係性は以下の通りです。
- 機械学習:AIの学習方法全般を指す最も広い概念。データからパターンを学習し、予測や分類を行う技術の総称です。
- 生成AI:機械学習の一分野。学習データに基づき、文章、画像、音声などの新しいコンテンツを生成するAIを指します。
- LLM:生成AIの中でも特にテキスト生成に特化したモデル。機械学習という大きな枠組みの中に位置づけられます。
つまり、LLMは生成AIの一種であり、その生成AIは機械学習という広範な技術分野に含まれるという関係性になります。この構造を理解することが、技術選定の第一歩です。
NLP(自然言語処理)におけるLLMの役割
NLP(Natural Language Processing:自然言語処理)は、人間が日常的に使う言葉(自然言語)をコンピュータに処理させるための技術分野です。従来、NLPは文章を単語に分解し、その構造を解析する「形態素解析」や「構文解析」といった手法が主流でした。
LLMの登場は、このNLPの分野に革命をもたらしました。LLMは、膨大な言語知識を背景に文脈全体を捉えることで、従来のNLP技術では難しかった微妙なニュアンスの理解や、より複雑な意図の汲み取りを可能にしたのです。現在では、LLMは多くのNLPタスクの精度を飛躍的に向上させるための強力なエンジンとして機能しています。



法人向けAI研修
AX CAMP 無料資料
LLMの心臓部「ニューラルネットワーク」の仕組み
LLMが人間のように言葉を操れるのは、その心臓部である「ニューラルネットワーク」の働きによるものです。この仕組みは、人間の脳が情報を処理するプロセスから着想を得ています。テキストデータを数値に変換し、単語間の関連性を学習することで、文脈に沿った適切な応答を生成します。
テキストの数値化から文脈理解までのプロセス(トークン化・Transformer)
コンピュータはテキストを直接理解できないため、まず文章を「トークン」と呼ばれる最小単位に分割し、それぞれを数値ベクトルに変換します。このプロセスをトークン化(Tokenization)と呼びます。例えば、「今日の天気は晴れです」という文章は、「今日」「の」「天気」「は」「晴れ」「です」といったトークンに分けられ、それぞれが固有の数値で表現されます。
次に重要なのが、「Transformer」というニューラルネットワークのモデルです。Transformerは、文章中の各トークンが他のどのトークンと強く関連しているかに「注意(Attention)」を向ける仕組みを持っています。これにより、「主語と動詞の関係」や「指示語が何を指しているか」といった文脈上の複雑な関係性を効率的に学習できるのです。(出典:Azure OpenAI Service を活用した大規模言語モデルの導入)
学習からテキスト生成までの全体像
LLMの動作は、大きく「学習」と「推論(テキスト生成)」の2つのフェーズに分かれます。学習フェーズでは、膨大なテキストデータから単語の次に来る単語を予測するトレーニングを繰り返します。この過程で、文法や事実、文章のスタイルといった言語に関するあらゆる知識を獲得するのです。
推論フェーズでは、ユーザーから入力されたプロンプト(指示文)に続く確率が最も高い単語を予測し、出力します。そして、その出力された単語を元に、さらに次の単語を予測するというプロセスを繰り返すことで、一連の文章を生成します。この一連の予測プロセスが、LLMによる自然なテキスト生成の基本的な仕組みです。
https://media.a-x.inc/llm-architecture https://media.a-x.inc/llm-tokensLLMの学習プロセスと進化の仕組み

LLMが高い性能を発揮するためには、多段階の学習プロセスが不可欠です。汎用的な知識を広く学ぶ「事前学習」を土台とし、特定の目的に合わせて性能を調整する「ファインチューニング」や、人間の感覚に合うように微調整する「RLHF」といったステップを経て、その精度は飛躍的に向上します。
事前学習(Pre-training)で幅広い知識を獲得
事前学習は、LLM開発の最初のステップです。この段階では、公的に利用が許可されたデータや適切なライセンスを取得した、膨大なテキストデータをAIに読み込ませます。目的は、特定のタスクを解かせることではなく、言語そのものの構造や文法、単語間の関係性、そして世の中の幅広い知識を自己学習させることです。
AIは、文章の一部を隠してそれを予測したり、次に来る単語を予測したりするタスクを何十億、何百億回と繰り返します。この地道なトレーニングを通じて、汎用的な言語能力の基礎を築き上げます。この事前学習済みモデルが、後続のチューニングプロセスの土台となります。
ファインチューニング(Fine-tuning)で特定タスクに特化
事前学習で得た汎用的な知識だけでは、特定の専門分野や企業の個別ニーズに応えることは困難です。そこで行われるのがファインチューニングです。これは、事前学習済みモデルに対して、特定のタスクに特化した小規模なデータセットを追加で学習させるプロセスを指します。
例えば、法律相談に特化したAIを開発したい場合、法律の条文や判例といった専門的なデータを追加学習させます。これにより、モデルは法律用語や特有の文脈を深く理解し、より専門的で精度の高い回答を生成できるようになります。ファインチューニングは、LLMを特定のビジネス用途に最適化するための重要な工程です。
https://media.a-x.inc/llm-learn https://media.a-x.inc/llm-pretraining
RLHF(人間のフィードバックによる強化学習)による精度向上
LLMが生成する文章を、より人間にとって自然で、かつ安全なものにするために用いられるのがRLHF(Reinforcement Learning from Human Feedback)です。この手法では、まずAIが生成した複数の回答パターンを人間(アノテーター)が評価し、「良い回答」から「悪い回答」までをランク付けします。この際、評価者のプライバシー保護や心理的安全性への配慮、評価対象データから個人情報を除去するといった倫理的な運用が極めて重要です。
次に、AIはこの人間の評価(フィードバック)を「報酬」として学習します。より高い評価を得られた回答のパターンを再現するように、AIは自身の応答戦略を自己修正していくのです。この強化学習プロセスを繰り返すことで、AIは不適切、有害、あるいは事実に基づかない回答(ハルシネーション)を避け、ユーザーの意図に沿った質の高い対話能力を身につけていきます。なお、RLHFはファインチューニングの一環として、あるいはそれとは別の工程として実施されるなど、モデルによってその位置づけは異なります。
https://media.a-x.inc/llm-reinforcement-learning
法人向けAI研修
AX CAMP 無料資料
【2026年】代表的なLLMの種類と最新モデル

2025年現在、LLMの開発競争は激化しており、主要なテクノロジー企業がそれぞれ特色あるモデルを発表しています。OpenAIの「GPTシリーズ」、Googleの「Geminiファミリー」、Metaの「Llamaシリーズ」、Anthropicの「Claudeファミリー」が市場をリードしており、それぞれが独自の強みを持って進化を続けています。
OpenAI社の「GPTシリーズ」
OpenAI社は、ChatGPTの頭脳として知られるGPTシリーズでLLM市場を牽引しています。GPT-5の後継モデルには大きな期待が寄せられていますが、具体的なモデル名や機能、リリース時期に関する公式発表はまだありません(2025年11月時点)。(出典:Introducing GPT-5) 今後の公式情報に基づき、その進化を注視する必要があります。
Google社の「Geminiファミリー」
Google社が開発するGeminiは、テキスト、画像、音声、動画などを統合的に扱う「マルチモーダル」性能を当初から重視して設計されているのが特徴です。長文の文脈理解能力がさらに向上し、大量のドキュメントや動画の内容を一度に読み込んで要約・分析する能力に長けています。(出典:Google AIの最新情報で、Gemini がさらに便利に) Google検索との連携も強みであり、リアルタイムの情報に基づいた回答精度で他社と差別化を図っています。
Meta社の「Llamaシリーズ」
Meta社(旧Facebook)が開発するLlamaシリーズは、オープンソースで提供されている点が最大の特徴です。これにより、世界中の開発者や研究者がモデルを自由に利用・改変でき、LLM技術の民主化を促進しています。(出典:Meta AI、Llama 3搭載でさらに進化) 企業はLlamaをベースに自社専用のAIを比較的低コストで構築できるため、特定用途に特化したモデル開発の分野で広く採用されています。透明性とカスタマイズ性の高さが、多くの企業にとって大きな魅力となっています。
Anthropic社の「Claudeファミリー」とその設計思想
Anthropic社は、AIの安全性と倫理性を重視した開発で知られています。同社の最新モデル群である「Claudeファミリー」は、「Constitutional AI」という独自の学習アプローチを採用しています。(出典:Introducing the next generation of Claude) これは、AIが従うべき原則(憲法)をあらかじめ設定し、その原則に沿って自己修正を繰り返す仕組みです。その結果、有害なコンテンツの生成を抑制し、より倫理的で信頼性の高い応答を実現しており、企業のコンプライアンスを重視する用途で高く評価されています。
https://media.a-x.inc/llm-open-source


LLMを搭載した代表的なAIサービス

LLMという基盤技術は、私たちが日常的に利用できる様々なAIサービスに組み込まれています。中でも「ChatGPT」「Gemini」「Copilot」は、LLMの能力を体感できる代表的なサービスであり、それぞれが異なる特徴を持ち、ビジネスからプライベートまで幅広いシーンで活用されています。
対話型AIの代表格「ChatGPT」
OpenAI社が提供するChatGPTは、LLMの能力を世界に知らしめた対話型AIのパイオニアです。基盤モデルであるGPTシリーズの高度な言語能力により、人間と話しているかのような自然で滑らかな対話を実現します。文章作成、アイデア出し、プログラミングコードの生成、翻訳など、極めて広い範囲のタスクに対応可能です。(出典:Introducing GPT-5) その汎用性の高さから、個人ユーザーだけでなく、多くの企業で業務効率化ツールとして導入が進んでいます。
https://media.a-x.inc/llm-chatgptGoogleのマルチモーダルAI「Gemini」
Geminiは、Googleが開発したLLMを搭載したAIサービスです。最大の特徴は、テキストだけでなく画像や音声も同時に理解できる「マルチモーダル性能」にあります。(出典:Google AIの最新情報で、Gemini がさらに便利に) 例えば、スマートフォンのカメラで写した風景について質問したり、手書きのメモを読み取らせてテキスト化したりといった使い方が可能です。Google検索との連携により、常に最新の情報に基づいた回答が得られる点も大きな強みです。

Microsoftの統合AIアシスタント「Copilot」
Microsoftが提供するCopilotは、同社の様々な製品やサービスに統合されたAIアシスタントです。Windows OSやMicrosoft 365(Word, Excel, PowerPointなど)、WebブラウザのEdgeに組み込まれており、ユーザーが作業している文脈に応じて適切なサポートを提供します。例えば、Excelで「売上データをグラフ化して」と指示したり、Wordで長文ドキュメントの要約を作成させたりと、日常的な業務にシームレスにAIの能力を組み込める点が魅力です。(出典:Azure OpenAI Service を活用した大規模言語モデルの導入) 基盤モデルは、製品やバージョンによって異なりますが、OpenAIのGPTシリーズなどが採用されている場合があります。

法人向けAI研修
AX CAMP 無料資料
ビジネスにおけるLLMの活用事例

LLMは、今やビジネスの現場において不可欠なツールとなりつつあります。特に「業務効率化」と「クリエイティブ支援」の領域でその効果は顕著であり、多くの企業がLLMを活用して生産性の向上や新たな価値創造を実現しています。 ここでは、具体的な活用シーンと、AX CAMP受講企業様の成功事例を紹介します。
1. 業務効率化:問い合わせ自動化と社内ナレッジ検索
LLMは、定型的な業務や情報検索にかかる時間を大幅に削減します。例えば、顧客からのよくある質問に自動で回答するチャットボットを構築したり、社内に散在する膨大なドキュメント(マニュアル、議事録、稟議書など)の中から必要な情報を瞬時に探し出す社内ナレッジ検索システムを開発したりすることが可能です。
これにより、従業員はより付加価値の高い業務に集中できるようになります。実際に、AX CAMP受講企業様の事例では、コールセンターの確認業務が月16時間からほぼ0時間になったという成果も報告されています。このような成功は、適切なツール選定と導入計画の賜物と言えるでしょう。
エムスタイルジャパン様の事例
美容健康食品の製造販売を手掛けるエムスタイルジャパン様では、コールセンターの履歴確認や手作業での広告レポート作成に多くの時間を費やしていました。AX CAMPの研修を通じて業務自動化を推進した結果、コールセンターの履歴確認業務(月16時間)や手作業の広告レポート作成業務などを自動化し、全社で月100時間以上の業務削減に成功しています。(出典:月100時間以上の”ムダ業務”をカット!エムスタイルジャパン社が築いた「AIは当たり前文化」の軌跡)
2. クリエイティブ支援:マーケティングとソフトウェア開発
LLMは、アイデア出しやコンテンツ制作といったクリエイティブな業務においても強力なアシスタントとなります。マーケティング担当者は、広告のキャッチコピーやブログ記事、SNS投稿の原案をLLMに生成させ、制作時間を大幅に短縮できます。ソフトウェア開発の現場では、プログラミングコードの自動生成やデバッグ(エラー修正)にLLMが活用され、開発サイクルの高速化に貢献しています。
Foxx様の事例
広告運用業務を手掛けるFoxx様は、既存事業の成長に限界を感じていました。AX CAMPでAI活用スキルを習得し、業務効率化によって生まれた時間を活用することで、既存事業の運用に加えて新規事業の立ち上げを実現しました。AIを単なる効率化ツールとしてだけでなく、新たなビジネスチャンスを生み出すための戦略的ツールとして活用した好例です。(出典:AX CAMP受講企業の成果事例)
WISDOM合同会社様の事例
SNS広告やショート動画制作を行うWISDOM合同会社様は、事業拡大に伴う人材採用コストと業務負荷の増大が課題でした。AX CAMPでAIによる業務自動化を推進した結果、採用2名分の業務負荷をAI活用で代替し、業務自動化を達成しました。これにより、コストを抑えながら事業を成長させる体制を構築しています。(出典:AX CAMP受講企業の成果事例)
https://media.a-x.inc/llm-use-cases

企業がLLMを導入・活用する際の戦略

企業がLLMを効果的に活用するためには、技術的な側面と組織的な側面の両方から戦略を立てる必要があります。単にツールを導入するだけでなく、自社の目的に合わせて精度を高める工夫や、安全に利用するためのルール作りが成功の鍵を握ります。
基盤モデルの活用とプロンプトによる精度向上
多くの企業にとって、LLMを一から開発するのは現実的ではありません。そのため、OpenAIやGoogleなどが提供する既存の「基盤モデル」をAPI経由で利用するのが一般的なアプローチです。この際、LLMの性能を最大限に引き出すために重要となるのが「プロンプトエンジニアリング」です。(出典:Azure OpenAI Service を活用した大規模言語モデルの導入)
プロンプトとは、LLMに対する指示や質問のことです。具体的で、文脈が明確なプロンプトを与えることで、AIの回答精度は飛躍的に向上します。「〇〇の役割になりきって」「以下の形式で出力して」といったように、役割、文脈、出力形式を細かく指定することが、ビジネスレベルの品質を得るための基本戦略となります。

情報漏洩を防ぐセキュリティとプライバシー対策
LLMのビジネス利用において最も重要な課題の一つがセキュリティです。消費者向けの公開サービスに企業の機密情報や個人情報を入力すると、データが意図せず学習に利用される可能性があります。しかし、法人向けのエンタープライズ契約では、このリスクに対応する選択肢が提供されています。
例えば、Microsoft Azure OpenAI Serviceのような法人向けサービスでは、入力データがモデルの再学習に利用されないことが契約上のデータ処理協定(DPA)で保証されています。(出典:Azure OpenAI Service を活用した大規模言語モデルの導入) 企業がLLMを導入する際は、以下の点を確認し、安全な利用体制を構築することが不可欠です。
- データ利用ポリシー:入力データがモデルの学習に利用されないか
- ログ保持方針:データの保存期間と管理方法
- 社内ガイドライン:機密情報や個人情報の入力を禁止するルールの策定と周知
- 技術的措置:入力フィルタリングや専用環境の利用検討
これらの対策を講じることで、情報漏洩リスクを管理し、LLMの恩恵を安全に享受できます。
https://media.a-x.inc/llm-security

法人向けAI研修
AX CAMP 無料資料
LLMとニューラルネットワークが直面する課題
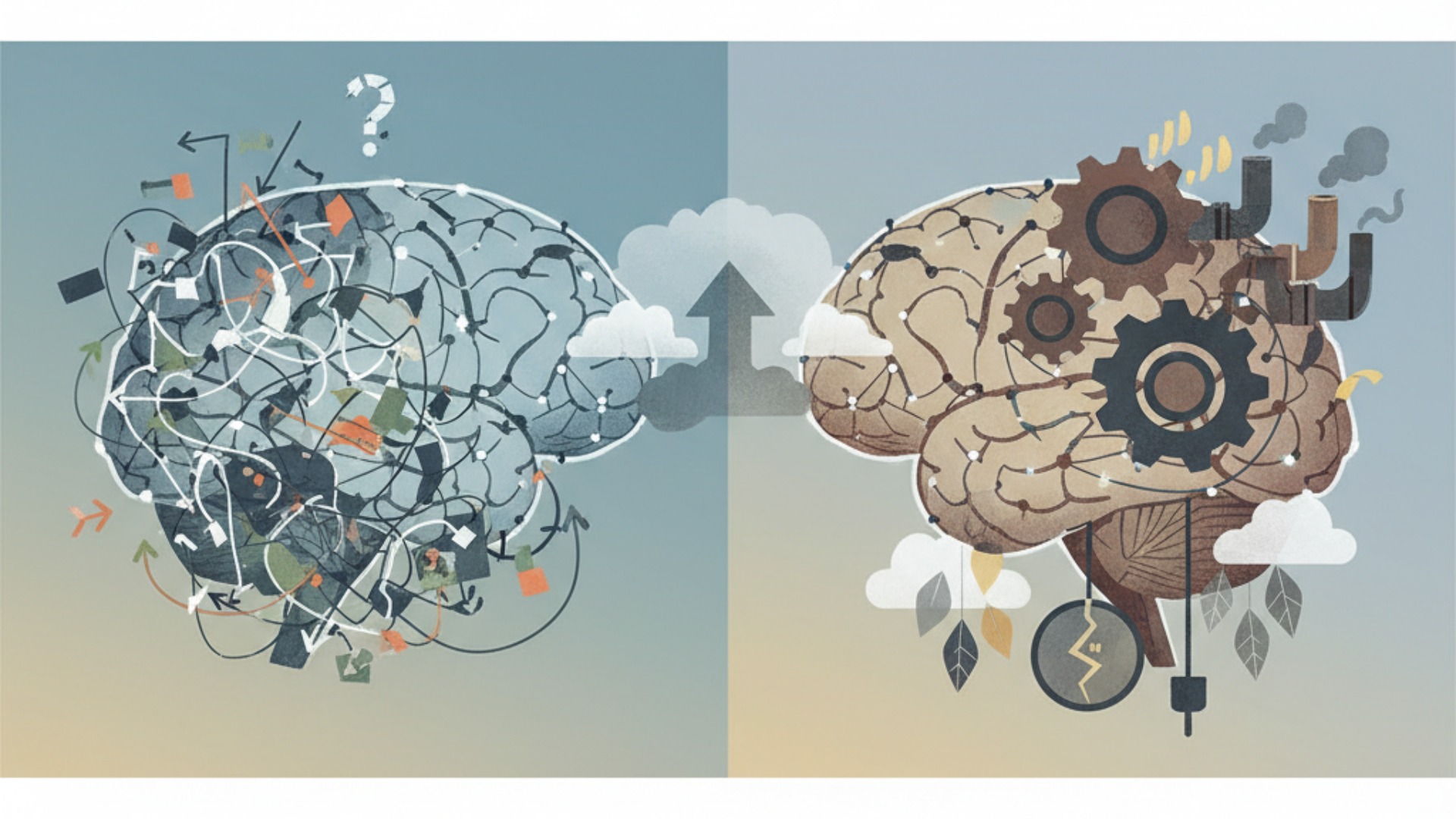
LLMとニューラルネットワークは驚異的な進化を遂げていますが、まだ多くの課題を抱えています。生成される情報の正確性や公平性に関する「精度の課題」と、開発・運用にかかる莫大なコストや環境への影響という「持続可能性の課題」は、今後の技術発展において乗り越えるべき大きな壁です。
精度の課題:ハルシネーションと学習データのバイアス
LLMが抱える最も深刻な課題の一つが「ハルシネーション(Hallucination)」です。これは、AIが事実に基づかない情報を、あたかも真実であるかのように生成してしまう現象を指します。LLMは学習データに基づいて次に来る単語の確率を予測しているだけで、情報の真偽を判断しているわけではないため、このような「もっともらしい嘘」を生み出してしまうのです。
また、学習データに含まれる偏り(バイアス)も大きな問題です。インターネット上のテキストには、特定の性別、人種、文化に関するステレオタイプや偏見が含まれている可能性があります。AIがこうしたデータを学習すると、差別的・偏見に満ちた回答を生成してしまうリスクがあり、公平性の担保が重要な課題となっています。



持続可能性の課題:計算コストと環境負荷
LLMの開発と運用には、膨大な計算リソースが必要です。大規模なニューラルネットワークを学習させるためには、高性能なGPUを数千台規模で数週間から数ヶ月間稼働させ続ける必要があり、莫大な電力消費とそれに伴うCO2排出が問題視されています。(出典:巨大AIの「電力問題」は解決できるか)
この計算コストと環境負荷は、LLM技術が広く普及していく上での大きな制約となります。そのため、より少ない計算量で高い性能を発揮する、エネルギー効率の良いモデルアーキテクチャや学習手法の開発が、持続可能なAIの実現に向けて急務となっています。モデルの軽量化や推論の高速化など、効率化技術の研究が世界中で進められています。

LLMの今後の展望と技術的進化

LLMとニューラルネットワークの技術は、今もなお急速な進化の途上にあります。今後は、テキストだけでなく様々な情報を統合的に扱う「マルチモーダル化」がさらに加速し、より効率的にAIを動作させるための新しい技術が登場することで、その応用範囲はビジネスから日常生活まで、あらゆる場面へと拡大していくでしょう。
マルチモーダル化の加速と応用範囲の拡大
今後のLLMの進化における最も重要なトレンドは「マルチモーダル化」です。現在のLLMは主にテキスト情報を扱いますが、将来的には画像、音声、動画、さらにはセンサーデータといった多様な形式の情報(モダリティ)を統合的に理解し、処理できるようになります。
例えば、設計図の画像を読み込ませて改善点をテキストで提案させたり、会議の音声と議事録を同時に入力して要約とタスクリストを生成させたりといった活用が考えられます。これにより、LLMの応用範囲は製造業、医療、エンターテイメントなど、これまで以上に幅広い分野へと拡大していくことが確実です。
https://media.a-x.inc/llm-multimodal新データフォーマットなど効率化技術の登場
LLMが直面する計算コストや環境負荷といった課題に対応するため、モデルの動作を効率化する技術開発も活発に進められています。これには、モデルの規模を圧縮して軽量化する「蒸留」や「量子化」といった技術が含まれます。
また、AIがより効率的にデータを処理できるような、新しいデータフォーマットの研究も進んでいます。これらの技術革新により、将来的にはスマートフォンなどのデバイス上で高性能なLLMが直接動作する「エッジAI」が普及し、より応答性が高く、プライバシーにも配慮したAIアプリケーションが実現する可能性があります。効率化技術の進展は、LLMの社会実装をさらに加速させる鍵となるでしょう。

LLMやAI活用を実践的に学ぶならAX CAMP

LLMやニューラルネットワークの理論を理解しても、それを自社のビジネス課題解決に結びつけるのは簡単ではありません。「何から手をつければいいのか分からない」「自社に最適な活用方法が見つからない」といった悩みを抱える企業は少なくないでしょう。知識を実践的なスキルへと昇華させるためには、体系的な学習と専門家によるサポートが不可欠です。理論学習と実践のギャップを埋めることが、AI導入成功の最短ルートとなります。
AX CAMPは、法人向けに特化した実践型のAI研修・伴走支援サービスです。単なる座学に留まらず、貴社の実際の業務課題をテーマにしたワークショップを通じて、明日から使える具体的なAI活用スキルを習得できるカリキュラムを提供しています。経験豊富なコンサルタントが、企画立案からプロトタイプ開発、社内展開までを一貫してサポートするため、AI導入のプロジェクトを確実に前進させることが可能です。
生成AIの基礎から、業務に特化したプロンプトエンジニアリング、自社データと連携させたAIシステムの構築まで、貴社のレベルと目的に合わせて最適なプランをご提案します。AIを使いこなし、ビジネスの成果に繋げたいとお考えなら、まずは無料相談で課題をお聞かせください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMとニューラルネットワークはAIの未来を拓く中核技術
本記事では、LLMとニューラルネットワークの関係性、その仕組み、最新動向、そしてビジネスにおける活用事例までを網羅的に解説しました。両者の関係を正しく理解し、最新の技術トレンドを把握することは、これからのAI時代を勝ち抜く上で不可欠です。
この記事の要点を以下にまとめます。
- LLMはニューラルネットワークを基盤とするAIである
- 文脈理解能力の高さが従来技術との大きな違い
- ビジネスでは業務効率化や創造性支援に大きく貢献する
- ハルシネーションやコストなどの克服すべき課題も存在する
- 今後はマルチモーダル化と効率化が進化の鍵を握る
LLMという強力なツールを使いこなし、企業の競争力を高めるためには、技術を正しく理解し、実践を通じて活用スキルを磨くことが重要です。しかし、社内だけでAI活用を推進するには多くのハードルが存在します。
AX CAMPでは、本記事で紹介したようなAI技術の実践的な活用法を、貴社の課題に合わせて具体的に学ぶことができます。専門家の伴走支援を受けながら、AI導入の第一歩を確実に踏み出し、業務時間を大幅に削減する仕組みを構築しませんか。ご興味のある方は、ぜひ下記の資料請求または無料相談をご利用ください。

法人向けAI研修
AX CAMP 無料資料