

「テキストだけでなく画像や音声もAIで扱いたい」
「複数の情報を組み合わせて、より高度な分析ができないか」——。AIのビジネス活用を考える上で、このようなニーズが高まっています。この解決策となるのが、テキスト、画像、音声といった複数の種類のデータ(モダリティ)を同時に処理できる
「マルチモーダルLLM」です。 この技術は、まるで人間が目と耳で得た情報を統合して物事を理解するように、AIの認識能力を飛躍的に向上させます。
この記事では、マルチモーダルLLMの基本的な仕組みから、ビジネスにもたらすメリット、2026年時点での最新モデル、そして具体的な活用事例までを網羅的に解説します。最後まで読めば、マルチモーダル技術の全体像を掴み、自社のビジネスにどう活かせるかのヒントを得られるでしょう。AIによる業務革新の可能性を探るため、まずはAX CAMPが提供する
「AI導入・活用事例集」を参考に、他社がどのように成果を出しているかをご確認ください。
記事:【AI導入しないことが経営リスクになる時代】先行企業が手にした圧倒的な競争優位とは?
LLMマルチモーダルとは?従来のLLMとの違いを解説

マルチモーダルLLM(大規模言語モデル)とは、テキスト、画像、音声、動画など、複数の異なる種類のデータを統合して処理できるAIモデルのことです。従来のLLMがテキスト情報のみを扱う「シングルモーダル」であったのに対し、マルチモーダルLLMは複数の情報源を関連付けて、より深く、そして人間に近い形で状況を理解できる点が最大の違いと言えます。
例えば、商品の写真を見せながら「これと同じ雰囲気の服を探して」と音声で指示する、あるいは会議の映像と音声から議事録を作成し、誰がどのような表情で発言していたかまで分析するなど、これまで実現が難しかった高度なタスクを可能にします。この能力は、ビジネスにおける顧客体験の向上や、全く新しいサービスの創出に繋がる可能性を秘めているのです。
テキストに限定されないデータ処理能力
マルチモーダルLLMの最も大きな特徴は、その多様なデータ処理能力にあります。従来のAIがテキストならテキスト、画像なら画像と、単一の種類(モーダル)のデータしか扱えなかったのに対し、マルチモーダルLLMはこれらを同時にインプットし、総合的に判断します。
具体的には、以下のようなデータを統合的に処理できます。
- テキスト(文章、コード)
- 画像(写真、イラスト、図表)
- 音声(人の会話、音楽、環境音)
- 動画(映像と音声の組み合わせ)
- センサーデータ(温度、振動、位置情報など)
これらのデータを組み合わせることで、例えば製造ラインの監視カメラ映像と稼働音、温度センサーのデータを統合し、故障の予兆をより高い精度で検知するといった応用が考えられます。これが、次世代のビジネスインテリジェンスの鍵となります。
シングルモーダルLLMとの根本的な違い
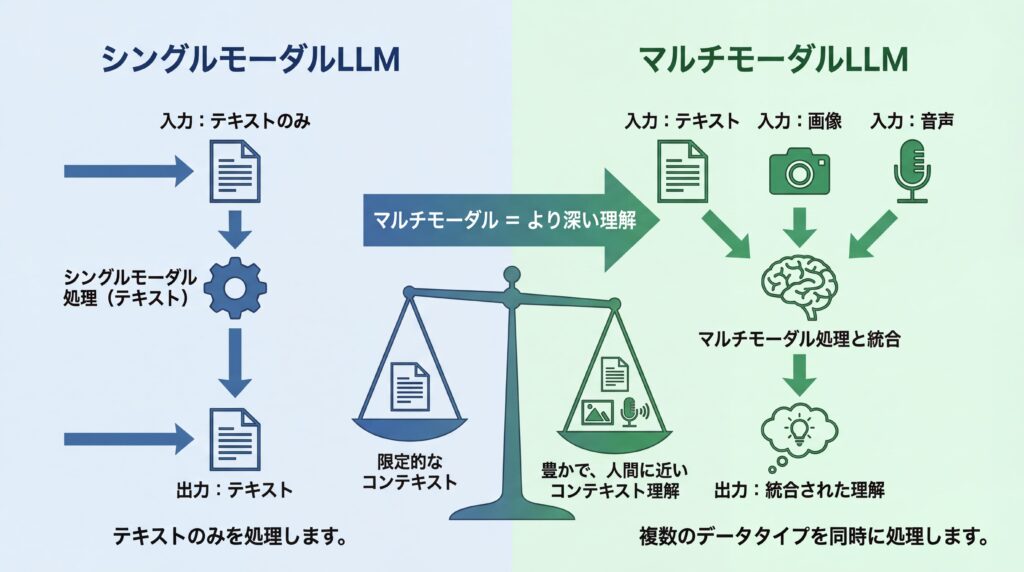
シングルモーダルLLMとマルチモーダルLLMの根本的な違いは、扱う情報の「種類」と「数」にあります。シングルモーダルLLMはテキストという単一の情報源に特化しており、文章の生成や要約、翻訳といったタスクを得意とします。一方、マルチモーダルLLMはテキストに加えて画像や音声など複数の情報源を統合して処理するため、より複雑で現実世界に近い問題に対応できるのです。
この違いは、AIの「世界理解」の仕方に大きな差を生みます。シングルモーダルLLMが「言葉の世界」を学習するのに対し、マルチモーダルLLMは視覚や聴覚といった感覚情報も合わせて学習することで、より豊かで文脈に沿った理解を実現します。この能力差が、後述するユーザー体験の向上や新たなアプリケーション開発の可能性に直結するのです。
VLM・LMMなど関連用語との関係性
マルチモーダルLLMを調べていると、「VLM」や「LMM」といった類似の用語を目にすることがあります。これらは扱うモダリティ(データの種類)の範囲やモデルの構造によって使い分けられることがありますが、基本的には同じ技術領域を指す言葉と捉えて問題ありません。
- VLM (Vision-Language Model): 特に「視覚(Vision)」と「言語(Language)」、つまり画像・動画とテキストの関係性を扱うモデルを指します。マルチモーダルLLMの中でも特に研究開発が活発な分野です。
- LMM (Large Multimodal Model): 大規模マルチモーダルモデルの略で、LLMと同様に、特に巨大なデータセットで学習させた高性能なモデルを指す際に使われます。マルチモーダルLLMとほぼ同義と考えてよいでしょう。
これらの用語は厳密な定義が確立しているわけではなく、文脈によって使い分けられることがあります。しかし、いずれも「複数の異なる種類のデータを統合的に処理する大規模なAIモデル」という共通の概念を持っています。

マルチモーダルLLMがもたらす主要なメリット

マルチモーダルLLMの導入は、ビジネスに3つの大きなメリットをもたらします。それは、①人間に近い高度な状況理解、②ユーザー体験(UX)の大幅な向上、そして③新たなアプリケーション開発の可能性です。これらは、従来のテキストベースのAIでは到達できなかった領域であり、企業の競争力を大きく左右する要素となり得ます。
これらのメリットは、単なる業務効率化に留まりません。顧客とのコミュニケーションをより円滑にしたり、これまで専門家の暗黙知に頼っていた作業を自動化したりと、事業の根幹に関わる変革を促す力を持っています。それぞれのメリットについて、具体的に見ていきましょう。
より人間に近い高度な状況理解
マルチモーダルLLMは、複数の情報源を統合することで、文脈やニュアンスを含んだ、より人間に近いレベルでの状況理解を実現します。例えば、カスタマーサポートにおいて顧客が送ってきた製品の写真と、その説明文(テキスト)、そして問い合わせの音声データを組み合わせることで、顧客がどのような状況で、どんな感情を抱いているのかをより正確に把握できます。
従来のAIでは、テキストから読み取れる事実情報しか判断できませんでした。しかし、マルチモーダルLLMは画像から製品の破損具合を、声のトーンから顧客の焦りや不満を読み取ることができます。この深いコンテキスト理解能力が、より的確で共感性の高い対応を可能にし、顧客満足度の向上に直結するのです。なお、顧客データなど個人情報を扱う際は、収集目的の明示や同意取得など、自社のプライバシーポリシーに則った適切な対応が不可欠です。
ユーザー体験(UX)の大幅な向上
マルチモーダルLLMは、ユーザーとの対話方法を劇的に変え、これまでにない直感的でスムーズなユーザー体験(UX)を提供します。私たちが普段、人とコミュニケーションを取る際に、言葉だけでなく表情やジェスチャーも使うように、AIとの対話もより自然な形に進化するのです。
例えば、スマートフォンの地図アプリで、目的地の写真を見せながら「ここに行きたい」と話しかけるだけでルート案内が始まる、といった操作が可能になります。テキストを入力したり、複雑なメニューをタップしたりする必要がありません。このように、ユーザーが最も自然だと感じる方法でAIと対話できるようになることは、あらゆるサービスにおいて顧客エンゲージメントを高める上で非常に強力な武器となります。
新たなアプリケーション開発の可能性
テキスト、画像、音声などを自在に組み合わせられるマルチモーダルLLMの能力は、これまで技術的に困難だった、あるいは想像もつかなかった新しいアプリケーションやサービスの創出を可能にします。
具体的な応用例としては、以下のようなものが考えられます。
- 教育分野: 生徒の解答用紙(画像)と、解説を求める音声(音声)をAIが理解し、パーソナライズされた解説動画をその場で生成する。
- 医療分野: レントゲン写真(画像)と医師の診断メモ(テキスト)を統合的に分析し、診断の補助となる情報を提示する可能性があります。ただし、最終的な診断は必ず人間の医師による判断が必要です。
- 自動運転: 車載カメラの映像、LiDARのセンサーデータ、GPS情報をリアルタイムで統合し、周囲の交通状況を極めて高い精度で認識・予測する。
このように、複数の情報を組み合わせることで初めて価値が生まれる領域において、マルチモーダルLLMは革新的なソリューションを生み出す起爆剤となるでしょう。
マルチモーダルLLMの基本的な仕組み
マルチモーダルLLMは、異なる種類のデータ(モダリティ)を、それぞれ専門の「エンコーダー」で数値情報に変換し、それらを統合してLLMが処理するという仕組みで動いています。人間で例えるなら、目から入った光の情報を脳が処理し、耳から入った音の情報を脳が処理し、それらを頭の中で統合して「何が起きているか」を理解するプロセスに似ています。
この「エンコード(符号化)」と「統合」のプロセスが、マルチモーダルLLMの核となる技術です。最終的に、LLMによって統合・処理された情報は、「デコーダー」によって人間が理解できるテキストや画像、音声といった形式で出力されます。この一連の流れによって、多様なデータの入出力が可能になるのです。
複数のモダリティを統合するエンコーダー技術
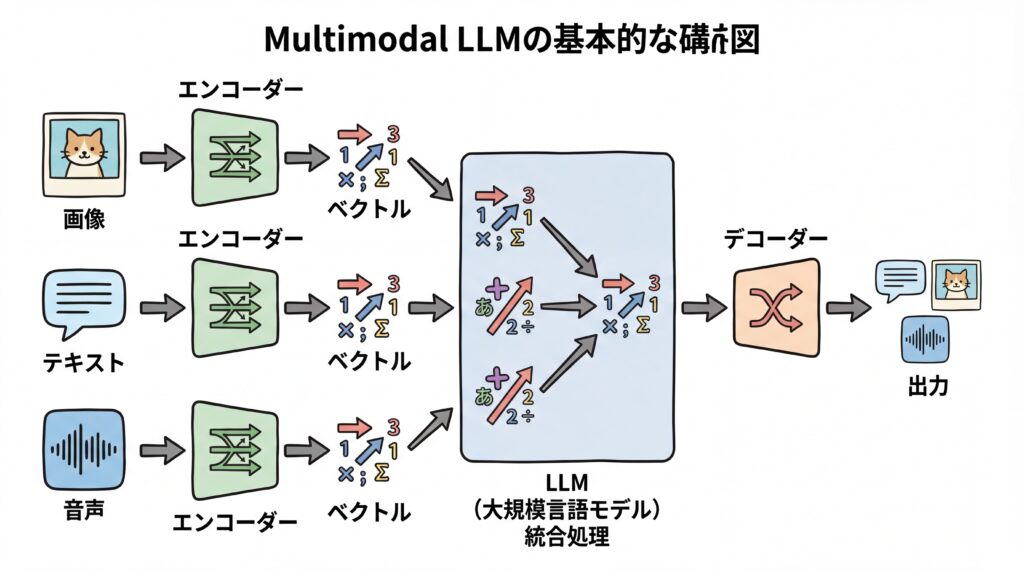
マルチモーダルLLMが多様なデータを扱うための最初のステップは、各モダリティをAIが理解できる共通の形式、具体的には「ベクトル」と呼ばれる数値の羅列に変換することです。この変換を行うのが「エンコーダー」と呼ばれる部分です。
- 画像エンコーダー: 画像のピクセル情報を分析し、何が写っているか、どのような配置かといった視覚的な特徴をベクトルに変換します。
- 音声エンコーダー: 音声の波形データを分析し、話されている言葉の内容や、話者の感情、背景の音といった聴覚的な特徴をベクトルに変換します。
- テキストエンコーダー: 単語や文章を分析し、その意味的な内容をベクトルに変換します。
このようにして、種類が全く異なるデータを「共通の言語(ベクトル)」に翻訳することで、LLMはそれらを横断的に比較・統合し、関連性を理解できるようになります。
事前学習とファインチューニングのプロセス
マルチモーダルLLMの高性能を支えているのは、膨大なデータを用いた2段階の学習プロセスです。
第一段階は「事前学習(Pre-Training)」です。ここでは、インターネット上に存在する膨大な画像とそれに付随するテキスト、動画と字幕といった、モダリティがペアになったデータセットをAIに学習させます。例えば、「猫が日向ぼっこをしている写真」とその説明文「A cat basking in the sun」を大量に学習することで、AIは画像の中の猫と「猫」という単語を結びつけて理解するようになります。この事前学習によって、AIは世界の様々な事象に関する広範な知識を獲得します。
第二段階は「ファインチューニング(Fine-Tuning)」です。事前学習で得た汎用的な知識を基に、特定のタスク(例:医療画像の診断支援、特定の製品に関する質疑応答など)に特化したデータセットで追加学習を行います。これにより、汎用的なモデルを特定の目的に合わせて最適化し、専門的なタスクで高い精度を発揮できるようになるのです。

【2026年版】主要マルチモーダルLLMとそれぞれの特徴

2025年現在、マルチモーダルLLMの開発競争は激化しており、主要IT企業から高性能なモデルが次々と発表されています。(出典:マルチモーダルLLMとは?仕組みやできること、代表的なモデルを解説)中でも、OpenAI社の「GPT-5.1」シリーズ、Google社の「Gemini 3 Pro」、Anthropic社の「Claude 4」シリーズは、業界をリードする代表的なモデルと言えるでしょう。これらのモデルは、それぞれに特徴があり、得意とするタスクや性能が異なります。
ビジネスでマルチモーダルLLMの活用を検討する際は、これらの主要モデルの特性を理解し、自社の目的や用途に最も適したものを選ぶことが重要です。APIを通じて利用できるクローズドなモデルだけでなく、特定の用途に合わせてカスタマイズが可能なオープンソースのモデルも登場しており、選択肢はますます多様化しています。
以下に、2025年11月時点での主要なマルチモーダルLLMモデルの公式発表などに基づく特徴をまとめます。
| モデル名 | 開発元 | 主な特徴 |
|---|---|---|
| GPT-5.1 シリーズ | OpenAI | 「Instant」と「Thinking」の2モデル構成。 テキスト、画像、音声、動画の入力を統合処理し、人間のような自然な速度で音声対話が可能とされています。 感情を込めた音声生成やリアルタイム翻訳にも優れると言われています。 |
| Gemini 3 Pro | 設計当初からマルチモーダルを前提としており、高度な推論能力とマルチモーダル理解が特徴です。 膨大な情報を一度に処理・分析できる能力を持つとされています。 | |
| Claude 4 シリーズ (Opus/Sonnet) | Anthropic | 特にコーディング能力や長時間の自律的なタスク実行能力に優れるとされています。 グラフや図の読解といった視覚的な推論タスクでも高い性能を発揮すると言われています。 |
| Llama 4 | Meta | オープンソースとして公開されており、研究者や開発者が自由にカスタマイズ可能です。 ネイティブでマルチモーダルに対応し、特定の用途に特化したモデル開発の基盤として広く利用されています。 |
【分野別】マルチモーダルLLMの具体的な活用事例
マルチモーダルLLMは、その高度な情報処理能力を活かして、すでに様々なビジネス分野で活用が始まっています。製造業における品質管理から、マーケティングにおけるコンテンツ制作、さらには専門的な知識が求められる医療分野まで、その応用範囲は多岐にわたります。ここでは、具体的な企業の取り組みを交えながら、分野別の活用事例を紹介します。
これらの事例は、マルチモーダルLLMが単なるコスト削減や効率化のツールに留まらず、新たな付加価値を創造し、ビジネスモデルそのものを変革するポテンシャルを秘めていることを示しています。自社の事業領域と照らし合わせながら、どのような活用が可能か考えてみましょう。
Route66様の事例
マーケティング支援を手掛けるRoute66様は、コンテンツ制作における時間短縮と効率化という課題を抱えていました。AX CAMPの実践型研修を通じてAIライティングツールを導入した結果、特定条件下において、従来24時間かかっていた記事作成プロセスの一部(下書き生成など)が、約10秒で完了したという事例があります。これはAIが持つテキスト生成能力を業務に適用した好例です。将来的には、記事内容に合った画像を自動生成するなど、さらなる応用が期待されます。(出典:AI導入事例集から見る、組織を変えるAX CAMPの実践的学び)
WISDOM合同会社様の事例
SNS広告やショート動画制作を行うWISDOM合同会社様では、事業拡大に伴う人材採用コストと業務負荷の増大が課題でした。AX CAMPの研修でAI活用スキルを習得し、業務自動化を推進。その結果、採用予定だった2名分の作業工数に相当する業務をAIで代替することに成功したと報告されています。動画素材(映像)と広告コピー(テキスト)、ターゲット層のデータ(数値)をAIが統合的に分析し、最適な広告クリエイティブを提案・生成するといった活用により、採用コストを抑えながら事業成長を実現しています。(出典:採用予定2名分の業務をAIが代替!WISDOM社、毎日2時間の調整業務を自動化)
エムスタイルジャパン様の事例
美容健康食品の製造販売を行うエムスタイルジャパン様は、コールセンターでの顧客対応履歴の確認や、手作業による広告レポート作成に多くの時間を費やしていました。AX CAMPの研修をきっかけに、GAS(Google Apps Script)とAIを連携させた業務自動化システムを構築。同社の事例(弊社実施のPoC、期間3ヶ月)では、対象業務の確認作業時間が月約16時間から大幅に削減される結果となりました。音声データとテキストデータをAIが連携して処理することで、全社で月100時間以上の業務削減に相当するとの試算も出ています。(出典:AI導入のよくある失敗とは?7つの原因と成功へのステップを解説)

マルチモーダルLLMの導入・活用における課題と今後の展望

マルチモーダルLLMは計り知れない可能性を秘めている一方で、その導入と活用にはいくつかの課題も存在します。モデルの複雑化に伴う計算コストの増大や、異なるモーダル間の意味的な関連付けの精度などが主なハードルです。これらの課題を克服しつつ、将来的にはAIが自律的に判断・行動する「自律型エージェント」へと発展していくことが期待されています。
ビジネス活用の観点からは、これらの技術的な課題を理解し、現時点で何ができて何が難しいのかを見極めることが重要です。また、技術の進化は非常に速いため、常に最新の動向を追いながら、社会実装の可能性を探っていく必要があります。
モデルの複雑化と計算コストの増大
マルチモーダルLLMは、テキスト、画像、音声といった複数のデータを同時に処理するため、シングルモーダルのモデルに比べて構造が非常に複雑になります。この複雑さは、モデルの学習や推論(AIが実際に処理を行うこと)に膨大な計算リソース(高性能なGPUなど)を要求します。
自社でモデルを構築・運用する場合には大規模な設備投資が必要になるほか、APIサービスを利用する場合でも、処理するデータの種類や量に応じて利用料金が高額になる可能性があります。そのため、導入にあたっては、得られるメリットとコストのバランスを慎重に評価する「費用対効果」の視点が不可欠です。
各モーダル間の意味的な関連付けの精度
マルチモーダルLLMの核は、異なる種類のデータを意味的に正しく関連付ける能力ですが、この精度にはまだ課題が残っています。例えば、「赤いリンゴの絵」に対して「これは赤い果物です」と正しく応答できても、より複雑で抽象的な概念の関連付けは時として失敗することがあります。
特に、AIが事実に基づかない情報を生成してしまう「ハルシネーション(幻覚)」は、マルチモーダルにおいても起こり得ます。画像の内容を誤って解釈したり、音声のニュアンスを取り違えたりするリスクがあるため、特に正確性が求められる業務(医療診断や金融取引など)に適用する際は、人間の専門家による最終確認が不可欠です。

自律型エージェントへの発展と社会実装
マルチモーダルLLMの技術は、将来的に「自律型エージェント」の実現に向けた中核技術になると考えられています。自律型エージェントとは、周囲の環境をカメラやマイクを通じて自ら認識し、与えられた目標(例:「この部屋を片付けて」)を達成するために、必要な作業を自律的に計画・実行するAIです。
現状ではまだ研究開発段階の側面も大きいですが、特定の業務を自動化するエージェントの実用化はすでに始まっています。家庭用のロボットから工場の自動化、自動運転車まで、幅広い分野での活躍が期待されています。マルチモーダルLLMによって「目」と「耳」と「知能」が統合されることで、AIはデジタル空間だけでなく、物理的な現実世界で人間をサポートするパートナーへと進化していくでしょう。

マルチモーダルLLM関連の最新技術・サービス動向【2026年】

2025年現在、マルチモーダルLLMの技術は、基盤モデルの性能向上だけでなく、特定の用途に特化したサービスや、より簡単に開発・導入できるプラットフォームの登場という形で急速に社会実装が進んでいます。(出典:【動画生成AI】Sora2とVeo3を徹底比較!仕事で使うならどっち?)特に、高品質な動画を生成するAIや、リアルタイムでの音声翻訳デバイスなど、消費者に身近な形でのサービス展開が目立っています。
これらの動向は、マルチモーダル技術がもはや研究段階のものではなく、実用的なビジネスツールとして成熟しつつあることを示しています。企業の担当者は、自社のビジネスに直接応用できるサービスが登場していないか、常にアンテナを張っておくことが重要です。
注目すべき最新動向としては、以下のようなものが挙げられます。
- 動画生成AIの進化: OpenAIの「Sora 2 2」やGoogleの「Veo 3」など、テキストの指示から非常にリアルで長尺の動画を生成するAIが登場しています。これにより、広告制作や映画制作のプロセスが劇的に変化する可能性があります。
- リアルタイム翻訳デバイス: 音声認識と音声合成、そして言語翻訳を組み合わせたウェアラブルデバイスが実用化されつつあります。海外旅行や国際会議でのコミュニケーションの壁を取り払う技術として注目されています。
- インタラクティブな設計支援: 建築や製品デザインの分野で、設計図(画像)と仕様書(テキスト)、そしてデザイナーの音声指示をAIが統合的に理解し、設計変更のシミュレーションをリアルタイムで行うようなツールが登場しています。
- オープンソースモデルの成熟: Meta社の「Llama 4」のように、高性能なオープンソースのマルチモーダルLLMが公開されることで、スタートアップや個人の開発者が、これまで大企業しか作れなかったような新しいアプリケーションを開発する動きが活発化しています。
これらの技術やサービスは、今後ますます多様化し、低コストで利用できるようになることが予想されます。自社の課題解決に繋がる技術をいち早く見つけ、活用していくことが、これからの時代に求められるでしょう。
マルチモーダルLLMを選ぶ際の比較ポイント

自社のビジネスにマルチモーダルLLMを導入する際には、数あるモデルの中から最適なものを選ぶ必要があります。その際、「対応モダリティの種類」「APIの提供有無と開発のしやすさ」「特定の業界やタスクへの特化度」という3つのポイントを比較検討することが成功のカギとなります。
単に性能が高いという理由だけでモデルを選ぶのではなく、自社の目的を明確にし、その目的を達成するために最も適した機能、開発環境、そして専門性を持つモデルはどれか、という視点で選定することが重要です。これらのポイントを一つずつ確認していきましょう。
対応しているモダリティの種類
まず最初に確認すべきは、そのモデルが自社の業務で扱う必要のあるデータの種類(モダリティ)に対応しているかという点です。例えば、コールセンターの応対品質を分析したいのであれば、音声とテキストの両方を扱えるモデルが必要です。製造ラインの異常検知であれば、カメラ映像とセンサーデータに対応したモデルが求められます。
主要なモデルはテキストと画像に対応していることが多いですが、動画や音声、特定のセンサーデータなどへの対応はモデルによって異なります。導入後に「必要なデータが扱えなかった」という事態を避けるためにも、要件定義の段階で必要なモダリティを洗い出し、各モデルの対応状況を必ず確認しましょう。
APIの提供有無と開発のしやすさ
既存の社内システムやアプリケーションにマルチモーダルLLMの機能を組み込みたい場合、API(Application Programming Interface)が提供されているかは極めて重要なポイントです。APIがあれば、自社の開発者が比較的容易にAI機能をシステムに連携させることができます。
APIを選ぶ際には、その提供形態に加えて、以下の点も確認しましょう。
- ドキュメントの充実度: 開発者向けの解説資料やサンプルコードが豊富に用意されているか。
- コミュニティの活発さ: 不明点があった際に、他の開発者に質問したり情報を交換したりできる場があるか。
- 料金体系: APIの利用料金が、自社の想定する利用規模や頻度に見合っているか。
開発のしやすさは、導入スピードと開発コストに直結するため、技術担当者の意見も聞きながら慎重に選定する必要があります。

特定の業界やタスクへの特化度
汎用的な大規模モデルも非常に高性能ですが、特定の業界やタスクにおいては、その分野の専門知識を追加で学習させた特化型モデルの方が高い精度を発揮する場合があります。
例えば、以下のような特化型モデルが考えられます。
- 医療特化モデル: 医療画像(レントゲン、CTなど)の解析や、医学論文の読解に特化してファインチューニングされたモデル。
- 金融特化モデル: 決算短信や市場レポートの分析、金融関連の専門用語の理解に優れたモデル。
- 法律特化モデル: 判例や法令の検索、契約書のレビューといったタスクに最適化されたモデル。
自社のビジネスが専門性の高い領域である場合、汎用モデルを自社でファインチューニングするか、あるいはすでに提供されている業界特化モデルを利用するかを検討することが、投資対効果を高める上で有効な選択肢となります。
マルチモーダルLLMのビジネス活用を学ぶならAX CAMP

マルチモーダルLLMの可能性は理解できても、「具体的に自社のどの業務に適用できるのかわからない」「導入を推進できる人材が社内にいない」といった課題を抱える企業は少なくありません。技術の進化が速い分野だからこそ、体系的な知識と実践的なスキルを効率的に学ぶことが成功への近道です。
株式会社AXが提供する「AX CAMP」は、まさにそうした企業のニーズに応えるための実践型AI研修サービスです。単なる座学で終わるのではなく、貴社の実際の業務課題をテーマに、手を動かしながらAI活用の企画から実装までを体験できます。これにより、研修終了後には自走できるAI推進人材が育ちます。
AX CAMPでは、マルチモーダルLLMを含む最新のAI技術動向を常にカリキュラムに反映しています。経験豊富な専門家が、技術的な側面だけでなく、ビジネスインパクトを最大化するための活用戦略立案まで伴走サポート。「AIを導入したものの、成果に繋がっていない」というよくある失敗を避け、確実な業務変革を実現します。自社に最適なAI活用法を見つけ、競合に先んじた一手を打ちたいとお考えなら、まずは無料の資料請求でAX CAMPの具体的なプログラム内容をご確認ください。(出典:AIリテラシーとは?DX時代に必須の基礎知識と高め方を解説)

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMマルチモーダルを理解しビジネスの可能性を広げよう
本記事では、マルチモーダルLLMの基本概念から仕組み、最新モデル、そして具体的なビジネス活用事例までを解説しました。改めて、重要なポイントを振り返ります。
- マルチモーダルLLMとは: テキスト、画像、音声など複数のデータを統合処理するAI。
- 主なメリット: 人間に近い高度な状況理解、UX向上、新サービス創出が可能。
- 基本的な仕組み: 各データをエンコーダーで共通形式に変換し、LLMが統合処理する。
- 最新動向: GPT-5.1やGemini 3 Proなどが開発をリードし、特定用途のサービスも増加。
- 選定のポイント: 対応モダリティ、APIの有無、業界への特化度を見極めることが重要。
マルチモーダルLLMは、もはや未来の技術ではなく、ビジネスの現場で具体的な成果を生み出すための実用的なツールです。この技術を理解し、いかに早く自社のビジネスに取り入れられるかが、今後の企業の成長を大きく左右するでしょう。
しかし、最先端技術を自社だけでキャッチアップし、ビジネスに落とし込むのは容易ではありません。AX CAMPでは、専門家の伴走支援のもと、記事で紹介したような業務効率化(例:特定条件下で記事作成の一部工程を24時間から約10秒に短縮)や、AIによる業務代替(例:採用2名分の工数に相当する業務を自動化)といった成果を、貴社で実現するための具体的なノウハウを提供します。AI導入の第一歩を確実に踏み出すために、まずは無料相談で専門家に課題を話してみませんか。

法人向けAI研修
AX CAMP 無料資料