

ローカル環境で大規模言語モデル(LLM)を動かそうとした際に、
「どのくらいのスペックのPCが必要なんだろう」
「VRAMやRAMという言葉は聞くけれど、具体的にどれだけ重要なの?」
といった疑問に直面したことはありませんか。
メモリ要件を正しく理解しないままハードウェアを選ぶと、性能不足でモデルが動かなかったり、逆にオーバースペックで無駄な投資になったりする可能性があります。
この記事では、LLMを動かす上で最も重要な「メモリ」に焦点を当て、その役割から必要な容量の計算方法、メモリ不足を解消する軽量化技術、さらには用途別のおすすめハードウェアまで、2026年最新の情報を基に網羅的に解説します。最後まで読めば、あなたの目的や予算に合った最適なLLM実行環境を、自信を持って構築できるようになるでしょう。
自社でのAI活用に関して、より実践的な知識や具体的な導入支援が必要な場合は、AI研修・伴走支援サービス「AX CAMP」の資料もぜひ参考にしてください。貴社の課題に合わせた最適なソリューションをご提案します。

法人向けAI研修
AX CAMP 無料資料
LLMにおけるメモリの重要性とは?
結論として、LLMの性能を最大限に引き出す上で、メモリはエンジンそのものと言えるほど極めて重要な役割を担います。なぜなら、モデルの思考能力や応答速度、一度に扱える情報量がメモリの容量に直接依存するためです。メモリはよく「作業机の広さ」に例えられ、この机が広ければ広いほど、より多くの参考資料(モデルのパラメータ)を広げ、複雑な作業(推論処理)を効率的に行えます。(出典:LLM のテクニック: 推論の最適化をマスターする)
具体的には、LLMがテキストを生成する際には、巨大なモデルのパラメータ(数十億〜数千億)をメモリ上に展開し、さらに入力された文章の文脈(コンテキスト)を保持し続ける必要があります。もしメモリ容量が不足すると、モデルの一部しか展開できずに動作が極端に遅くなったり、最悪の場合はエラーで処理が停止してしまったりと、LLMの能力を全く活かせません。そのため、LLMを快適に利用するには、モデルの規模や用途に見合った十分なメモリ容量を確保することが不可欠なのです。

LLMで使われる2種類のメモリ:VRAMとRAM
LLMの実行環境を考える際、混同されがちなのが「VRAM」と「RAM」という2種類のメモリです。多くの構成ではGPUに搭載されたVRAMがLLM計算の主役となり、CPUが利用するRAMが補助的な役割を果たします。しかし、この役割分担は絶対ではなく、構成によって変化することを理解するのが適切なハードウェア選びの第一歩です。
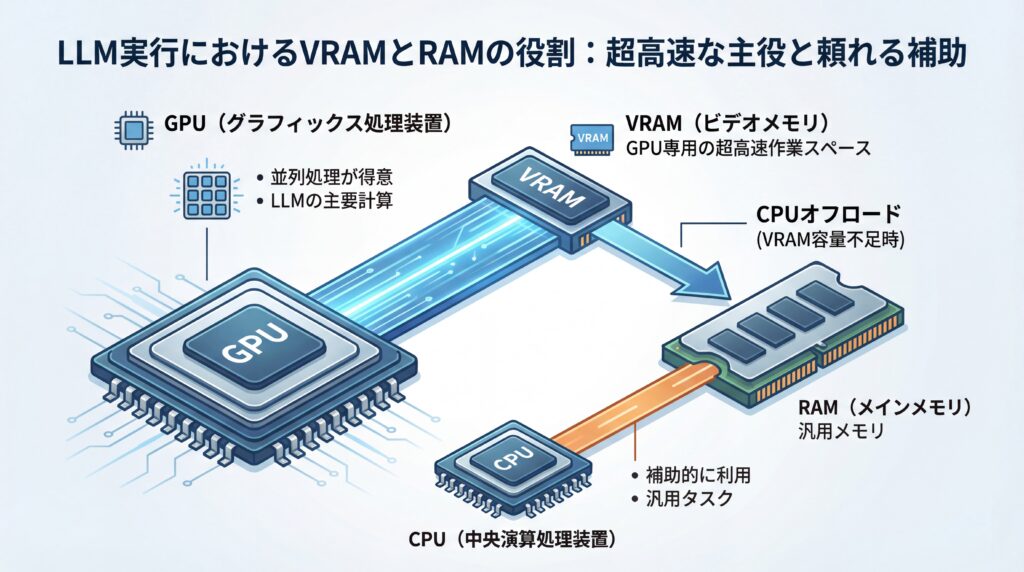
VRAM(Video RAM)は、GPU(Graphics Processing Unit)専用の高速なメモリです。GPUは単純な計算を同時に数千個単位でこなす「並列処理」が非常に得意であり、LLMの複雑な計算もこの能力を駆使して行われます。VRAMは、その高速な計算処理に必要なデータを置いておくための、いわば「GPU専用の超高速作業スペース」であり、LLMの応答速度はVRAMの容量と速度に大きく左右されます。
一方で、RAM(Random Access Memory)は、PCのメインメモリとしてCPUが利用する汎用的なメモリです。LLMの実行においては、VRAM容量だけでは足りない場合にモデルの一部をRAMに待避させる「CPUオフロード」という技術で補助的に使われることがあります。ただし、RAMはVRAMに比べてデータ転送速度が遅いため、多用すると処理速度が低下します。多くのワークロードではVRAMが主要ですが、CPUオフロードや統合メモリ設計ではRAMが直接的に重要になるという点を押さえておきましょう。

【実践】LLMに必要なメモリ容量の計算方法

LLMを動かすためにどれくらいのVRAMが必要になるかは、いくつかの要素からおおよその数値を計算できます。最も重要な要素は、モデルの「パラメータ数」と、モデルのデータを圧縮する「量子化レベル」の2つです。これらの要素を理解すれば、目当てのモデルが自分のPCで動くかどうかを事前に見積もることが可能になります。
さらに、一度に処理する文章の長さである「コンテキスト長」もメモリ消費に影響を与えます。ここでは、これらの要素を踏まえた具体的な計算方法をステップごとに見ていきましょう。
パラメータ数と精度に基づく基本計算
最も基本的なメモリ要件は、モデルのパラメータ数と、その数値を表現する「精度」から算出できます。LLMのパラメータは、多くの場合「FP16」や「BF16」(16ビット浮動小数点数)形式で扱われ、この形式では1パラメータあたり2バイトのデータ量が必要です。ここから、モデルの重み(パラメータ)を格納するための理論上の最小VRAMを算出できます。
計算式は「重みに必要なVRAM容量(GB) ≒ パラメータ数(B) × 2」です。例えば、70億(7B)パラメータを持つモデルの場合、重みだけで 7 × 2 = 14GB のVRAMが必要になります。しかし、これはあくまでモデルの重みを格納するだけのサイズです。実際の推論時には、過去の文脈を保持する「KVキャッシュ」や推論フレームワーク自体の「実装オーバーヘッド」が加わるため、モデルサイズに加えて数GB以上の追加VRAMを見積もるのが一般的です。(出典:LLM のテクニック: 推論の最適化をマスターする)
量子化レベルを考慮した計算例
前述の計算では大規模モデルを動かすのに膨大なVRAMが必要ですが、「量子化(Quantization)」という技術を使うことで、必要なメモリ量を大幅に削減できます。量子化とは、モデルの性能への影響を最小限に抑えつつ、各パラメータが使用するデータサイズ(ビット数)を小さくする圧縮技術です。例えば、16ビットのデータを4ビットに圧縮すれば、単純計算でデータサイズは4分の1になります。(出典:LLMの量子化(Quantization)とは?仕組みや手法、メリット・デメリットを解説)
現在主流の4ビット量子化モデル(例: GGUF形式のQ4_K_M)の場合、経験則として「必要なVRAM容量(GB) ≒ パラメータ数(B) × 0.6」という計算式が目安になります。この式を使えば、7Bモデルなら 7 × 0.6 = 約4.2GB、13Bモデルなら 13 × 0.6 = 約7.8GBのVRAMで動作させられる計算になり、一般的なゲーミングPCでも中規模モデルの実行が現実的になります。(出典:LLMの量子化についてざっくり完全に理解する(GGUF, GPTQ, AWQ, ExL2))
コンテキスト長がメモリに与える影響
パラメータ数と量子化レベルに加えて、コンテキスト長もメモリ使用量に影響を与える重要な要素です。コンテキスト長とは、LLMが一度に理解・処理できる文章の長さ(トークン数)のことで、長い文章を扱うほどより多くのメモリを消費します。
これは、LLMが過去の文脈を記憶するために「KVキャッシュ」と呼ばれる情報をメモリ上に保持するためです。このKVキャッシュのサイズは、コンテキスト長に比例して大きくなります。数千トークン程度の短いコンテキストであれば影響は軽微ですが、数万〜数十万トークンの長いコンテキストを扱う場合は、追加で数GBのVRAMが必要になることがあります。近年では、vLLMに搭載された「PagedAttention」のように、KVキャッシュのメモリ断片化を解消し、メモリ効率を大幅に向上させる技術も登場しています。(出典:NVIDIA TensorRT-LLM の KV キャッシュの早期再利用により、最初のトークンまでの時間を 5 倍高速化)

メモリ不足を解消する代表的なLLM軽量化技術
手持ちのハードウェアのVRAMが限られている場合でも、いくつかの軽量化技術を駆使することで、より大きなLLMを動かせます。代表的な技術が、すでに触れた「量子化」と、VRAMをRAMで補う「CPUオフロード」です。これらの技術は、Ollamaなどのローカル実行ツールで広くサポートされており、特にGGUF形式のモデルではメモリマッピングの最適化により効率的に動作させることが可能です。
これらの技術は、メモリ使用量を削減する強力な手段ですが、それぞれにメリットとデメリットが存在します。トレードオフを理解し、自身の目的や環境に合わせて適切に使い分けることが重要です。
量子化(Quantization):精度と速度のトレードオフ
量子化は、LLMのメモリ使用量を削減するための最も効果的な技術の一つです。モデルのパラメータを表現する数値の精度を、例えば16ビットから8ビットや4ビットに下げることで、モデルファイルのサイズと実行に必要なVRAMを劇的に小さくします。例えば4ビット量子化を適用すれば、理論上はモデルの重みが4分の1のサイズになり、必要なVRAMも大幅に削減できます。
この技術の最大のメリットは、メモリ消費量を大幅に削減できる点にあります。一方で、数値を低い精度で近似するため、モデルの応答精度がわずかに低下するというトレードオフも存在します。とはいえ、近年の量子化技術の進歩は目覚ましく、例えばGGUF形式で広く採用されている4ビット量子化(Q4)などは、実用上ほとんど問題にならないレベルの精度を維持しつつ、VRAM使用量を効率化できるため、多くの場面で活用されています。(出典:LLMの量子化についてざっくり完全に理解する(GGUF, GPTQ, AWQ, ExL2))
CPUオフロード:VRAM不足をRAMで補う技術
CPUオフロードは、GPUのVRAMだけでは収まりきらないLLMのモデルデータを、PCのメインメモリ(RAM)に一部分散して配置する技術です。これにより、VRAM容量を超える大規模なモデルでも、PC全体のメモリを合算して実行できるようになります。例えば、24GBのVRAMを持つGPUと64GBのRAMを搭載したPCがあれば、両方を活用してより大きなモデルを動かせます。
この技術の利点は、物理的なVRAMの制約を超えて大規模モデルを動作させられる点にあります。しかし、CPUとRAM間のデータ転送速度は、GPUとVRAM間に比べて格段に遅いという大きなデメリットがあります。そのため、RAMにオフロードするデータ量が多いほど、LLMの応答速度は顕著に低下します。速度が求められるタスクには不向きですが、時間をかけても大規模モデルを試したい場合に有効な選択肢となります。
メモリ不足を解決する「量子化」とは?GGUFとAWQを使いこなす
一口に「量子化」と言っても、その手法やフォーマットは多岐にわたります。ここでは、特に広く利用されている代表的な2つのフォーマット、GGUFとAWQについて、その特徴と使いこなし方を解説します。これらを理解することで、ご自身の環境に最適なモデルを選び、LLMのメモリ不足問題を効果的に解決できます。
- GGUF (GPT-Generated Unified Format): CPUとGPUの両方で効率的に動作するよう設計されたフォーマットです。最大の特徴は、CPUだけでもLLMを動かせる手軽さにあります。GPUを搭載していないPCや、VRAM容量が極端に少ない環境でも、モデルの一部または全部をメインメモリに展開して実行できます。llama.cppなどのフレームワークで広くサポートされており、ローカル環境で手軽にLLMを試したい場合に最適な選択肢です。
- AWQ (Activation-aware Weight Quantization): GPU上での高速な推論に特化した量子化技術です。モデルの重みを量子化する際に、特に重要な部分の精度を維持する工夫が施されています。これにより、量子化による精度低下を最小限に抑えながら、GPUでの推論速度を大幅に向上させることが可能です。十分なVRAMを持つGPU環境で、リアルタイム性が求められるアプリケーションを開発する場合に真価を発揮します。
このように、手軽さ重視ならGGUF、GPUでの速度と精度を両立させたいならAWQと、目的やハードウェア環境に応じて適切な量子化フォーマットを使い分けることが、賢いLLM活用の鍵となります。
主要ローカルLLM実行ツールとメモリ管理術

LLMをローカル環境で動かすには、専門的な知識が必要だと感じるかもしれません。しかし、現在では「Ollama」や「LM Studio」といった便利な実行ツールが登場しており、複雑な設定やメモリ管理を意識することなく、誰でも手軽にLLMを試せるようになっています。これらのツールは、モデルのダウンロードから実行、各種設定までを簡単に行えるように設計されています。
これらのツールを使いこなすことで、本記事で解説した量子化やCPUオフロードといったメモリ管理技術も、簡単な操作で適用できます。自分の環境に最適な設定を見つける上で、非常に強力な助けとなるでしょう。
Ollama:シンプルなコマンドラインツール
Ollamaは、コマンドライン(ターミナル)上で操作する、非常にシンプルで軽量なLLM実行ツールです。最大の特長は、たった一つのコマンドで好きなモデルをダウンロードし、すぐにチャットを開始できる手軽さにあります。例えば、`ollama run llama3`と入力するだけで、Meta社の最新モデル「Llama 3」が自動でダウンロードされ、対話可能な状態になります。(出典:Meta Llama 3 is now available on Ollama)
メモリ管理に関しても、Ollamaは多くの処理を自動で行ってくれるため、ユーザーが細かく意識する必要はほとんどありません。とりあえず手軽にローカルLLMを体験してみたい、という初心者の方や、シンプルな環境を好む開発者に特におすすめのツールです。
LM Studio:GUIで直感的に操作
LM Studioは、グラフィカルなユーザーインターフェース(GUI)を備えた、非常に高機能で直感的なLLM実行ツールです。モデルの検索・ダウンロード画面では、Hugging Faceなどで公開されている無数のモデルを検索し、量子化のレベル(例: Q4_K_M, Q5_K_Mなど)を選んでダウンロードできます。モデルをロードする前に、推定VRAM使用量が表示されるため、自分のPCで動かせるかを事前に判断しやすいのが大きな利点です。
さらに、モデル設定画面では、GPUに何層分のモデルをオフロードするかをスライダーで簡単に調整できるなど、メモリ管理を視覚的に行えます。チャット画面も使いやすく、複数のモデルを切り替えながら試すことも容易です。初心者から上級者まで、幅広いユーザーにとって非常に使いやすいツールと言えるでしょう。

用途別!LLM向けハードウェア選びのポイント【2026年版】

LLMをローカルで実行するためのハードウェアを選ぶ際は、自分が「どのサイズのモデルを、どの程度の量子化で動かしたいか」を基準に、必要なVRAM容量を確保できるGPUを選ぶことが最も重要です。2026年1月現在、コンシューマー向けGPUの性能は飛躍的に向上しており、多くの選択肢が存在します。 ここでは、代表的なモデルサイズごとに、おすすめのスペック構成を紹介します。
入門スペックから、より大規模なモデルを扱うための推奨スペックまで、具体的なGPUモデル名を挙げながら解説しますので、ハードウェア選びの参考にしてください。
7B〜13Bモデルを動かす入門・中級スペック
7B(70億)から13B(130億)パラメータクラスのモデルは、コーディング支援や文章作成など、個人の生産性を高める多くのタスクで十分な性能を発揮します。これらのモデルを4-bit量子化で快適に動かす場合、VRAM要件はモデル規模や設定に依存しますが、8GBから16GBのVRAMを搭載したGPUが推奨されます。実機での検証を推奨しますが、一般的な目安として参考にしてください。
例えば、7Bモデルを4-bit量子化で運用する場合の目安は約4〜8GB、13Bモデルでは約8〜12GBです。具体的なGPUとしては、NVIDIA社の「GeForce RTX 4060 (8GB)」や「GeForce RTX 4060 Ti (16GBモデル)」などがコストパフォーマンスに優れる選択肢です。これらのGPUを搭載したゲーミングPCであれば、比較的手頃な価格で快適なローカルLLM環境を構築できます。
70Bクラスの大規模モデルを扱う上級スペック
70B(700億)パラメータを超えるような大規模モデルは、より高度な推論能力を持ち、研究開発や専門業務への活用が期待されます。これらのモデルをローカルで動作させるには、24GB以上のVRAMを持つハイエンドGPUが推奨されますが、条件次第ではそれ以下でも不可能ではありません。
代表的なGPUは、コンシューマー向け最強クラスの「GeForce RTX 4090 (24GB)」です。これ1枚で、量子化された70Bモデルを比較的快適に動かせます。さらに高度な研究や開発で、より大きなモデルや複数のモデルを同時に扱う場合は、「NVIDIA RTX 6000 Ada世代 (48GB)」のようなプロフェッショナル向けGPUや、複数のGPUをNVLinkで接続する構成が視野に入ります。
【実録】モデルサイズ別・VRAM別 ローカルLLM動作レポート

では、実際にPCのVRAM(ビデオメモリ)ごとに、どのくらいのモデルサイズのローカルLLMが動作するのでしょうか。ここでは代表的なGPUを例に、実際の動作感をまとめたレポートをお届けします。モデルの「量子化」レベルによって必要なVRAMは変わりますが、一般的な設定での目安としてご覧ください。
- VRAM 8GB (GeForce RTX 4060など): 7B(70億)パラメータクラスのモデルが主なターゲットです。
Mistral-7Bなどを4bit量子化すれば、チャット用途では比較的快適に動作します。ただし、長い文章の生成や複雑な指示では速度低下が見られます。 - VRAM 12GB (GeForce RTX 4070など): 13Bクラスのモデルや、より高品質に量子化された7B/8Bモデルが視野に入ります。
Llama-3-8B-Instructを高設定で動かしたり、設定次第ではMixtral-8x7Bのような高性能モデルを試すことも可能です。 - VRAM 24GB (GeForce RTX 4090など): 70Bクラスの大規模モデルのローカル動作が現実的になります。
Llama-3-70B-Instructを4bit量子化した場合、プロンプトの処理に少し時間はかかりますが、一度動き出せば実用的な速度でテキストを生成できます。
このように、ローカルLLMの動作体験は、モデルサイズとVRAM容量のバランスに大きく左右されます。VRAMが不足していても、量子化技術を工夫すれば小〜中規模モデルは十分に活用可能です。しかし、非圧縮の巨大モデルを動かしたり、複数のモデルを同時に試したりするには、物理的なメモリの壁が立ちはだかります。では、この物理的な制約を超えて、より柔軟にLLMを利用するにはどうすればよいのでしょうか。
ローカル実行とクラウド利用のメモリ要件比較

LLMを利用する方法は、自前のPCで動かす「ローカル実行」だけではありません。クラウドサービス上の高性能なサーバーを時間単位でレンタルする「クラウド利用」も有力な選択肢です。メモリ要件の観点から見ると、ローカルは初期投資と物理的上限が課題になる一方、クラウドは柔軟にリソースを確保できるという大きな違いがあります。
どちらの方法が優れているかは一概には言えず、セキュリティ要件、コスト、利用したいモデルの規模など、目的によって最適な選択は異なります。ここでは、それぞれのメリット・デメリットを比較し、どのような場合にどちらが適しているかを解説します。
| 比較項目 | ローカル実行 | クラウド利用 |
|---|---|---|
| 初期コスト | 高い(高性能PCの購入費) | 低い(アカウント作成のみ) |
| ランニングコスト | 低い(電気代のみ) | 高い(時間単位での従量課金) |
| メモリの柔軟性 | 低い(物理的な上限あり) | 非常に高い(必要な分だけ確保可能) |
| セキュリティ | 非常に高い(データが外部に出ない) | サービス事業者に依存 |
| 手軽さ | やや手間(環境構築が必要) | 非常に手軽(すぐに利用開始可能) |
ローカル実行の最大のメリットは、一度環境を構築してしまえば、ランニングコストを気にせず自由に使える点と、機密情報などを外部に出すことなく処理できる高いセキュリティです。一方で、クラウド利用は、初期投資ゼロで最新・最強のGPU環境を必要な時間だけ利用できる手軽さと、メモリ容量を気にせずあらゆる大規模モデルを試せる柔軟性が魅力です。まずはクラウドで様々なモデルを試し、本格的に活用したいモデルが決まったらローカル環境を構築する、という進め方も賢い選択と言えるでしょう。
【2026年版】LLMメモリ技術のトレンドと将来性

LLMとそれを支えるハードウェア技術は、今も驚異的なスピードで進化を続けています。メモリ技術に関しても、より効率的に、より大容量のデータを扱うための新しいアプローチが次々と登場しています。今後の大きなトレンドとして、ハードウェアレベルでのメモリ統合と、推論の仕組みを工夫することによる効率化という2つの方向性が注目されています。後者の例として、vLLMの「PagedAttention」は、メモリ上のKVキャッシュを効率的に管理して断片化を防ぎ、スループットを2〜4倍に向上させる画期的な技術として期待されています。
vLLMのような推論を高速化するフレームワークや、GGUF形式での量子化など、LLMを効率的に動かす技術は日々進化しています。 これにより、少ないメモリ消費で高性能なLLMを動かすことが現実的になってきました。ここでは、その基盤となる代表的なトレンドを2つ紹介します。
統合メモリアーキテクチャの普及
「統合メモリアーキテクチャ」は、今後のトレンドを象徴する技術の一つです。これは、従来は別々のチップに搭載されていたCPU、GPU、そしてメモリを一つのパッケージに統合する設計で、CPUとGPUが同一のメモリ空間を共有します。これにより、VRAMとRAMの間のデータコピーに伴うオーバーヘッドを削減できるのが特長です。(出典:Appleシリコンのユニファイドメモリとは?Macのメモリは8GBで足りる?増設はできる?)
このアーキテクチャ最大の利点は、PCに搭載されている大容量のメインメモリを、GPUが直接的かつ効率的に利用できる点です。例えば、大容量の統合メモリを搭載したPCであれば、その広大なメモリ空間をフルに活用して、VRAMの物理的な容量に縛られずに巨大なLLMを動作させられます。今後、様々なプラットフォームで同様のアーキテクチャが普及していくことが期待されます。
MoEモデルにおけるメモリ効率化
モデルの構造そのものを工夫してメモリ効率を高めるアプローチも進んでいます。その代表が「MoE(Mixture of Experts)」と呼ばれるアーキテクチャです。これは、巨大な一つのモデルではなく、それぞれが特定の知識や能力を持つ「専門家(Expert)」の小規模なモデルを多数組み合わせるという考え方です。
MoEモデルでは、入力された質問に応じて、関連する専門家モデルだけが起動して処理を行います。全てのパラメータを常にメモリにロードしておく必要がないため、モデル全体の総パラメータ数が数千億に達するような巨大なモデルでも、推論時のメモリ使用量を大幅に抑えることができます。この技術により、将来的にはサーバークラスの性能を持つモデルを、コンシューマー向けのハードウェアで動かせるようになるかもしれません。

LLMのビジネス活用を学ぶならAX CAMP

ここまで、LLMをローカルで動かすためのメモリ要件や、vLLMのような最新技術まで解説してきました。 しかし、こうした日進月歩の技術知識をただ理解するだけでなく、自社の課題解決に結びつけるには別の難しさがあります。技術の導入が目的化してしまい、実際の業務改善に繋がらないというケースは少なくありません。
もし、あなたがLLMや生成AIのビジネス活用を本気で推進したいと考えているなら、実践型AI研修・伴走支援サービス「AX CAMP」がその最短ルートを提示します。AX CAMPでは、単なるツールの使い方を学ぶだけでなく、貴社の具体的な業務内容や課題に寄り添った、実務直結のカリキュラムを提供します。専門家による伴走支援を通じて、自社に最適なLLM環境の選定から、業務へのAI導入、プロンプトエンジニアリング、さらにはAIを活用した新規事業の創出まで、一気通貫でサポートできます。
実際に、AX CAMPを導入した企業様の中には、採用予定2名分の業務をAIで代替したWISDOM社様や、SNS運用における月間1,000万インプレッションの達成を自動化した企業様など、劇的な業務効率化や事業成長を実現した事例が数多く生まれています。(出典:AIと仕事の未来|なくなる仕事・生まれる仕事と必須スキルを解説)自社でLLMをどう活用すれば良いか、その具体的な道筋と成功の確度を高めたい方は、ぜひ一度、無料の資料請求やオンライン相談をご検討ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLM メモリ要件を理解し、最適な環境を構築しよう
本記事では、ローカル環境でLLMを動かすために不可欠なメモリ要件について、多角的に解説しました。最適なLLM実行環境を構築するためには、まずこれらの基礎知識をしっかりと押さえることが重要です。
- LLMの性能はメモリ、特にVRAMの容量に大きく依存する
- 必要VRAMは「パラメータ数」「量子化レベル」「コンテキスト長」で決まる
- 量子化やCPUオフロードでメモリ不足を補うことができる
- OllamaやLM Studioなどのツールで手軽に実行できる
- ハードウェアは動かしたいモデルの規模と設定に合わせて選定する
これらの技術知識を武器に、ぜひローカルLLMの世界に挑戦してみてください。一方で、Meta社のLlama 4シリーズやMistral AI社のモデルなど、多様な選択肢の中から「どの業務に、どのLLMを、どのように適用すれば最大の効果が得られるか」という問いに答えるのは、決して簡単ではありません。 (出典:AIで業務効率化!成功事例と活用アイデア)
もし、AI技術を活用した本質的な業務改革や、競合優位性の確立を目指しているのであれば、ぜひAX CAMPの活用をご検討ください。貴社の状況に合わせた最適なAI導入プランの策定から、社員のスキルアップ、そして継続的な活用支援まで、専門家チームが強力にバックアップします。まずは無料相談で、貴社の課題や可能性についてお聞かせください。

法人向けAI研修
AX CAMP 無料資料