

「社内の機密情報や顧客データをAIに入力するのは不安だ」
「インターネットに接続できない環境でも、安定して使えるAIはないだろうか」——。ChatGPTをはじめとするクラウド型AIの業務活用が進む一方で、このようなセキュリティや運用面の課題を感じている企業は少なくありません。
その有力な解決策となるのが、本記事で解説する
「ローカルLLM」です。ローカルLLMとは、自社のPCやサーバーといった閉じられた環境(ローカル環境)で動作する大規模言語モデル(LLM)のこと。データを外部に送信することなく、安全にAIを活用できるため、多くの企業から注目を集めています。
この記事を読めば、ローカルLLMの基本的な仕組みから、クラウド型との違い、具体的な導入方法、そしてビジネスに最適なモデルの選び方まで、網羅的に理解できます。AI活用を次のステージへ進めるための、実践的な知識をぜひ手に入れてください。
また、AIのビジネス活用に関するより具体的なノウハウや、導入を成功させるためのステップをまとめた資料もご用意しております。ご興味のある方は、ぜひダウンロードしてご活用ください。

法人向けAI研修
AX CAMP 無料資料
ローカルLLMとは?クラウド型との違いを解説
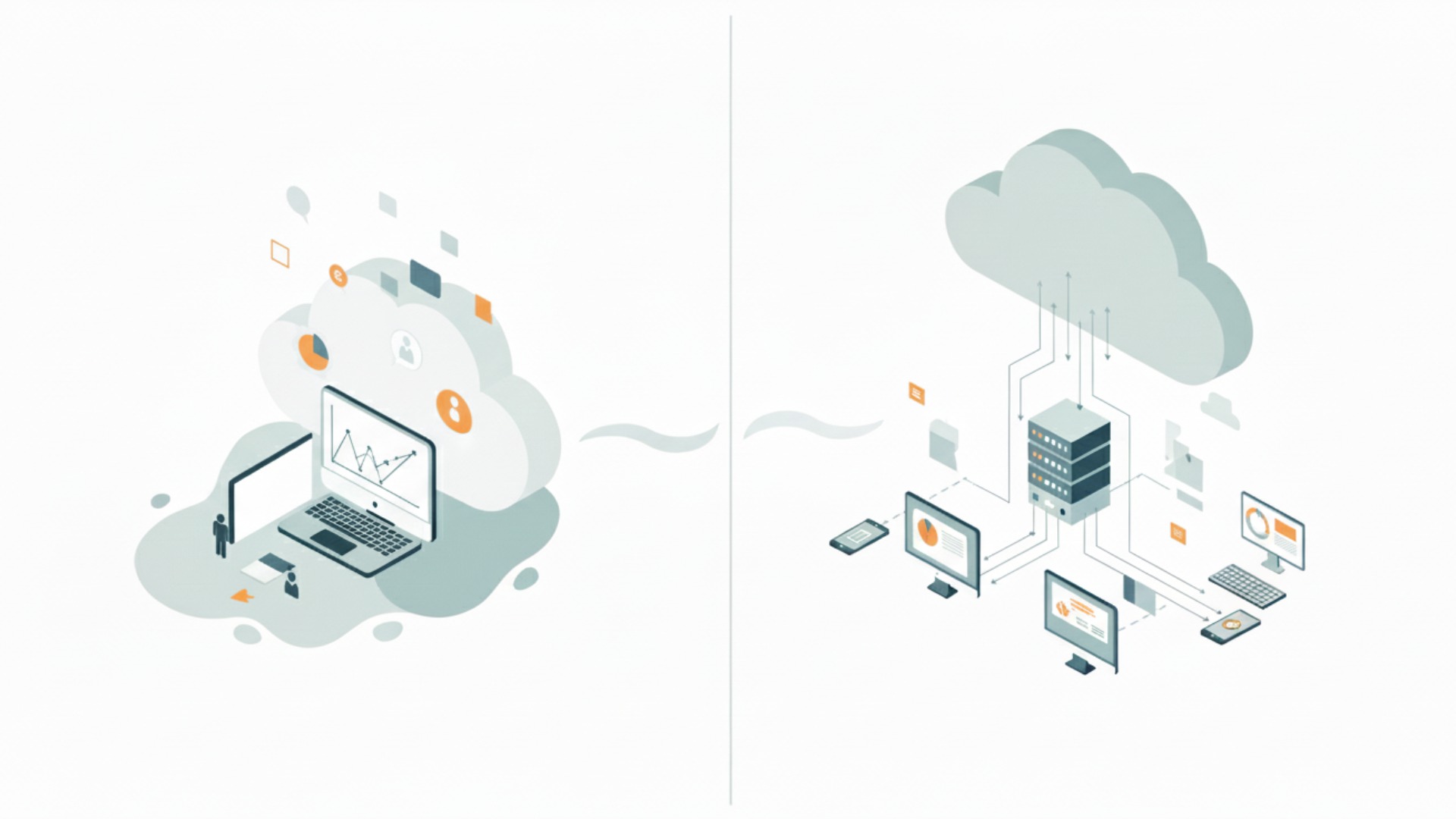
結論から言うと、ローカルLLMはユーザー自身のPCや社内サーバー上で直接動作させる大規模言語モデルを指します。インターネットを介して外部のサーバーで処理されるクラウド型LLMとは、データの置き場所と処理方法が根本から違う、と理解するのが最も分かりやすいでしょう。
この違いが、セキュリティ、カスタマイズ性、コスト構造など、多くの面での特性の差となって現れます。自社の目的や環境に合わせて最適な選択をするためには、両者の違いを正確に理解することが不可欠です。まずは、その基本的な仕組みから見ていきましょう。
ローカルLLMの基本的な仕組み
ローカルLLMは、モデルのプログラム本体と、学習済みの膨大なデータ(パラメータ)をすべて手元のコンピュータにダウンロードして使用します。ユーザーが何かを質問・指示すると、その処理はPCやサーバー内部のCPUやGPUを使って完結します。そのため、正しく構築・設定すれば、ローカル環境で推論を完結させ外部へデータを送信せずに運用できます。
ただし、使用するツールのテレメトリ機能やネットワーク設定によっては意図せず外部通信が発生する場合があるため、導入前にプライバシーとネットワーク構成を必ず監査してください。インターネット接続が不要でオフライン環境でも安定して利用できる点も、クラウド型にはない大きなメリットと言えます。(出典:Offline-First – LM Studio)
クラウド型LLM(ChatGPTなど)との比較
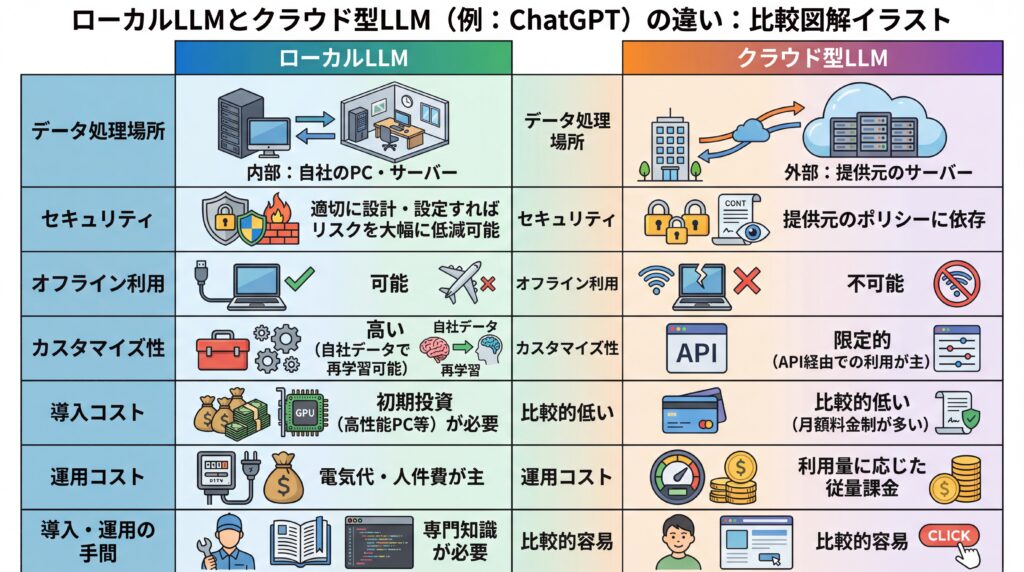
| 比較項目 | ローカルLLM | クラウド型LLM (例: ChatGPT) |
|---|---|---|
| データ処理場所 | 自社のPC・サーバー(内部) | 提供元のサーバー(外部) |
| セキュリティ | 適切に設計・設定すればリスクを大幅に低減可能(※監査と運用ルールの整備が必須) | 提供元のポリシーに依存 |
| オフライン利用 | 可能 | 不可能 |
| カスタマイズ性 | 高い(自社データで再学習可能) | 限定的(API経由での利用が主) |
| 導入コスト | 初期投資(高性能PC等)が必要 | 比較的低い(月額料金制が多い) |
| 運用コスト | 電気代・人件費が主 | 利用量に応じた従量課金 |
| 導入・運用の手間 | 専門知識が必要 | 比較的容易 |
ローカルLLMとクラウド型LLMの主な違いを上記の表にまとめました。クラウド型は手軽に最高性能のAIを利用できる一方、ローカルLLMはセキュリティとカスタマイズ性に優れている点が特徴です。
つまり、どちらか一方が絶対的に優れているわけではなく、自社の「守るべきもの」と「達成したいこと」に応じて選択肢が変わるのです。次の章では、ローカルLLMを選ぶ具体的なメリットを深掘りします。

ローカルLLMを導入する3つのメリット
ローカルLLMを導入する最大の動機は、データ保護レベルの向上、柔軟な運用、そして独自のデータによる深いカスタマイズ性にあります。これらのメリットは、特に機密情報を扱う企業や、独自のAI活用で競争優位性を築きたい企業にとって大きな魅力となるでしょう。
高度なセキュリティとデータプライバシーの確保
ローカルLLMがもたらす最大のメリットは、適切に環境を構築・運用することで、データが外部に送信されるリスクを大幅に低減できる点です。顧客情報、財務データ、技術情報といった機密性の高い情報を扱う際、クラウドサービス利用時に懸念される情報漏洩のリスクを自社の管理下でコントロールできます。(出典:ローカルLLMとは? ChatGPTとの違いやメリット・デメリット、代表的なモデルを解説 – @IT)
これは、外部のセキュリティポリシーに依存せず、自社の基準で能動的にデータを守れることを意味します。金融、医療、法務など、特に厳しいデータ管理が求められる業界において、このメリットはAI導入の前提条件とも言えるでしょう。(出典:Offline-First – LM Studio)

運用面の柔軟性(オフライン利用・コスト管理)
インターネット接続が不要なため、オフライン環境でも問題なくAIを利用できます。例えば、通信が不安定な工場や建設現場、あるいはセキュリティ上外部ネットワークから隔離された研究開発部門などでも、LLMの能力を最大限に活用可能です。(出典:Offline-First – LM Studio)
さらに、一度環境を構築すれば、API利用料のような従量課金が発生しないため、コスト管理がしやすく予算計画が立てやすい点もメリットです。利用頻度を気にすることなく大量のテキスト生成やデータ分析を実行できるため、長期的に見ると総コストを抑制できる可能性があります。
独自のデータセットによる高度なカスタマイズ性
ローカルLLMは、社内に蓄積された独自のデータを使ってモデルを再学習(ファインチューニング)させることが可能です。これにより、業界特有の専門用語や社内独自の言い回しを理解し、業務内容に特化した高精度な応答を生成する「自社専用AI」を構築できます。
例えば、過去の問い合わせ履歴を学習させて高精度な社内向けチャットボットを開発したり、社内ナレッジを学習させて検索精度を向上させたりと、活用方法は無限大です。汎用的なクラウド型LLMでは難しい、業務に深く根差したAI活用が実現します。

法人向けAI研修
AX CAMP 無料資料
知っておくべきローカルLLMの2つのデメリット
多くのメリットがある一方で、ローカルLLMの導入には高性能なハードウェアへの初期投資と、環境構築・運用を担う専門知識という2つの大きなハードルが存在します。これらのデメリットを理解し、対策を講じることが導入成功の鍵となります。
高性能なハードウェアへの初期投資
LLMを快適に動作させるには、高性能なGPU(Graphics Processing Unit)を搭載したPCやサーバーが不可欠です。特に、モデルの性能を左右する「パラメータ数」が大きくなるほど、より多くのVRAM(ビデオメモリ)容量が必要になります。
一般的なオフィス用PCではスペックが不足することが多く、モデルによっては数十万円から数百万円の初期投資が必要になる場合があります。このハードウェアコストが、特に中小企業にとって導入の際の大きな障壁となる可能性があり、投資対効果の慎重な見極めが求められます。

専門知識と継続的な自己管理の必要性
ローカルLLMの導入と運用には、ITインフラやAIに関する専門知識が求められます。どのモデルを選定し、どのようにPC環境を構築するか、また導入後に発生するトラブルにどう対処するかなど、自社で判断・解決しなければならない場面が多くあります。
また、新しいモデルが次々と登場するため、継続的に情報を収集し、システムをアップデートしていく手間も発生します。クラウド型サービスのように手軽に始められるわけではなく、運用管理のための人的リソースや属人化のリスクも考慮しておく必要があります。

ローカルLLMの具体的な活用シーンと業界事例

ローカルLLMは、その高いセキュリティ性とカスタマイズ性を活かし、社内の機密情報を扱う業務や、特殊な専門知識が求められる分野で特に強力なツールとなります。具体的な活用シーンと、それを裏付ける企業の導入事例を見ていきましょう。
社内データ(文書・コード)のセキュアな活用
多くの企業では、社内規定、マニュアル、過去の議事録、顧客とのやり取りなど、膨大な量のテキストデータが蓄積されています。ローカルLLMを使えば、これらの機密情報を外部に出すことなく安全に活用できます。
具体的な活用例としては、以下のようなものが挙げられます。
- 社内規定問い合わせAIチャットボット
- 過去の類似案件の検索・要約
- ソフトウェアのソースコードレビュー支援
- 契約書や申請書類の自動チェック
これらの業務をAIで自動化・効率化することで、従業員はより付加価値の高い業務に集中できるようになります。
医療・金融業界におけるデータ分析と活用事例
個人情報や機密情報の塊である医療・金融業界は、ローカルLLMの活用が特に期待される分野です。例えば、医療分野では電子カルテの情報を学習させ、医師の診断を補助するAIを開発したり、金融分野では市場データや企業情報を分析し、投資判断を支援するレポートを自動生成したりといった活用が進んでいます。ただし、金融商品の投資助言に該当する利用は関連法令の対象となる場合があり、最終的な投資判断は専門家の監督下で行うなど、適切なコンプライアンス体制の構築が不可欠です。
実際にAX CAMPの研修を導入した企業でも、AI活用による劇的な業務効率化が実現しています。
Route66様の事例
マーケティング支援を手掛けるRoute66様では、コンテンツ制作における原稿執筆が大きな時間的負担となっていました。AX CAMPの研修を通じてAIライティングのノウハウを習得した結果、従来24時間かかっていた原稿執筆の初稿作成が、わずか10秒で完了(※)し、圧倒的な生産性向上を実現しました。(※AIによる初稿生成に要した時間)(出典:AX CAMP導入事例)
WISDOM合同会社様の事例
SNS広告やショート動画制作を行うWISDOM合同会社様は、事業拡大に伴う人材採用コストと業務負荷の増大に悩んでいました。AX CAMPでAI活用スキルを習得し、業務自動化を推進した結果、事業拡大に必要な業務の一部をAIで代替することに成功。これにより、採用予定だった2名分の業務負荷に相当する作業をAIが担い、コストの最適化と既存メンバーの業務効率化を同時に達成しました。(出典:生成AIによるマニュアル作成業務の効率化事例)
エムスタイルジャパン様の事例
美容健康食品の製造販売を行うエムスタイルジャパン様では、コールセンターの履歴確認や手作業での広告レポート作成に多くの時間を費やしていました。AX CAMPの研修でGAS(Google Apps Script)とAIを組み合わせた業務自動化を学んだ結果、これらの定型業務を自動化し、全社で大幅な業務時間の削減に成功しています。(出典:AX CAMP導入事例)
https://media.a-x.inc/ai-use-case
法人向けAI研修
AX CAMP 無料資料
【2026年最新】目的別おすすめローカルLLMモデル5選

ローカルLLMのモデル選定では、性能の高さ、ライセンス(商用利用の可否)、そして実行に必要なPCスペックの3つの観点から、自社の目的に合ったものを選ぶことが重要です。ここでは、2025年10月時点で特に注目されている、目的別の代表的なオープンソースモデルを5つ紹介します。
1. Gemma 3:多用途で高性能な汎用モデル
Googleが開発した「Gemma 3」は、同社の高性能モデル「Gemini」の技術を基に構築された、軽量かつ高性能なオープンモデルファミリーです。(出典:Gemma 3: A new generation of open models)テキストと画像の入力に対応するマルチモーダル性能を持ち、要約や質疑応答、簡単なコーディングまでこなすため、まず試したいオールラウンダーと言えるでしょう。
2. Mistralシリーズ:多言語対応と効率性に優れたモデル
フランスのスタートアップMistral AIが開発したモデル群は、高い推論能力と多言語対応に定評があります。モデルが結論に至るまでの思考プロセスを可視化する機能が特徴で、回答の信頼性が求められる業務に適しています。利用前には、必ず該当モデルの公式ライセンスを確認してください。モデルごとにライセンスが異なる点には注意が必要です。
3. CyberAgentLM3:日本語処理に特化した高精度モデル
サイバーエージェントが開発した「CyberAgentLM3」は、日本語の処理に特化して学習された高性能なモデルです。(出典:サイバーエージェント、日本語LLMの新たな研究開発成果 最大1750億パラメータのLLMを公開)日本の文化や商習慣に関する知識が豊富で、自然な日本語を生成する能力に長けているため、日本語の精度を最優先する業務で特に力を発揮します。
4. Llama 3.1:Meta社が開発した最新オープンソースモデル
Meta社(旧Facebook)が開発を主導するLlamaシリーズの最新版が「Llama 3.1」です。(出典:meta-llama/llama-models – GitHub)専門家の知識を組み合わせる「MoE(Mixture-of-Experts)」というアーキテクチャを採用し、比較的少ない計算量で高い性能を発揮します。最新技術をいち早く試したい場合に最適な選択肢の一つです。
5. Phi-3:低スペックPCでも動作可能な軽量モデル
Microsoftが開発した「Phi-3」は、「小さいのに賢い」をコンセプトにした軽量モデル(SLM: Small Language Model)ファミリーです。(出典:Phi-4 Technical Report – Microsoft Research)パラメータ数を抑えながらも、高品質なデータセットで学習させることで、大きなモデルに匹敵する能力を実現しています。手元のPCで手軽に始めたい場合に最適です。

ローカルLLMを動かすための環境構築と必要スペック

ローカルLLMを導入する上で最も重要なのが、適切なPCスペックの確保です。特に、モデルのパラメータサイズによって、必要となるGPUのVRAM(ビデオメモリ)容量が大きく変動します。ここでは、モデルサイズ別に必要なスペックの目安と、OSごとの環境構築のポイントを解説します。
モデルサイズ別に必要なPCスペック(CPU/GPU/VRAM)
LLMの性能はパラメータサイズ(単位:B、Billion=10億)に大きく依存しますが、サイズが大きくなるほど必要なVRAM容量も増大します。以下に、量子化(モデルを軽量化する技術)を適用した場合の一般的な目安を示します。
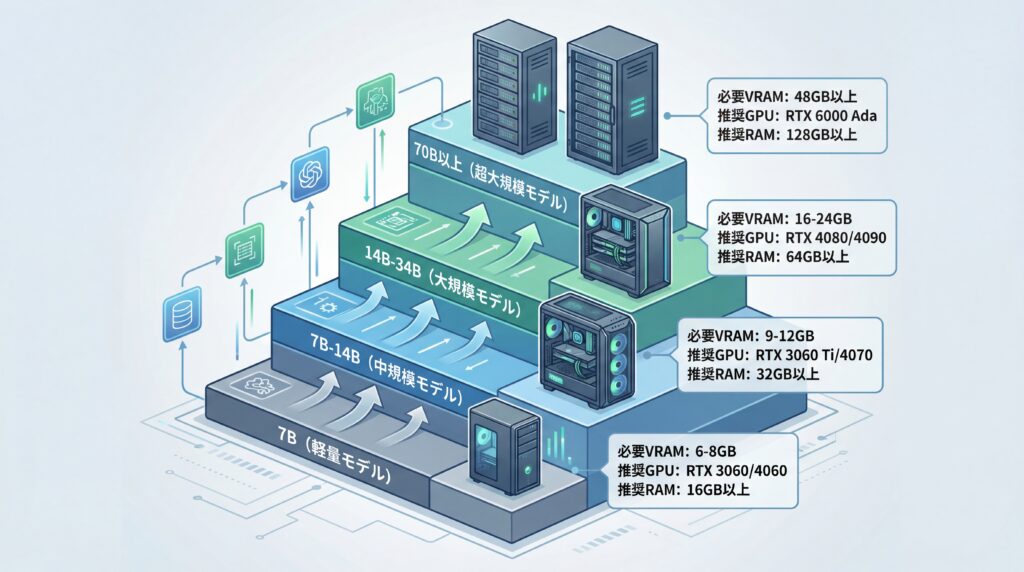
| モデルサイズ | 必要VRAM容量(目安) | 推奨GPU(例) | 推奨RAM |
|---|---|---|---|
| ~7B(軽量) | 6GB ~ 8GB | NVIDIA GeForce RTX 3060 / 4060 | 16GB以上 |
| 7B ~ 14B(中規模) | 9GB ~ 12GB | NVIDIA GeForce RTX 3060 Ti / 4070 | 32GB以上 |
| 14B ~ 34B(大規模) | 16GB ~ 24GB | NVIDIA GeForce RTX 4080 / 4090 | 64GB以上 |
| 70B以上(超大規模) | 48GB以上(複数GPU推奨) | NVIDIA RTX 6000 Ada世代 | 128GB以上 |
VRAMの要求量はモデルの精度や量子化の度合いに大きく依存します。例えば、量子化技術を使えば、より少ないVRAMでモデルを動作させることが可能です。(出典:Model Memory Calculator – Hugging Face)一方、業務で現実的な応答時間を得るためにはGPUが強く推奨されます。小型で量子化されたモデルはCPUのみでも動作しますが、応答速度は限定的です。
Windows, Mac, Linux別の環境構築のポイント
OSごとに環境構築の方法は若干異なりますが、近年はOllamaのようなツールが登場したことで、どのOSでも比較的簡単に導入できるようになりました。
- Windows: 以前は環境構築が複雑でしたが、WSL2(Windows Subsystem for Linux 2)の登場や、Ollama、LM StudioといったツールのWindows対応により、手軽に実行できるようになりました。
- Mac: Appleシリコン(Mシリーズチップ)搭載のMacは、CPUとGPUが統合されたユニファイドメモリにより、メモリを効率的に使えるためスペック表記以上の性能を発揮しやすい利点があります。Ollamaなどのツールもネイティブ対応しており、導入は比較的容易です。
- Linux: 開発者向けのツールが最も充実しており、環境構築の自由度が高いOSです。NVIDIA製GPUのドライバ設定など、ある程度の知識は必要ですが、最も柔軟な運用が可能です。
法人向けAI研修
AX CAMP 無料資料
初心者でも簡単!ローカルLLMの導入方法3ステップ

専門的な知識が必要なイメージのあるローカルLLMですが、「Ollama」や「LM Studio」といった便利なツールを使えば、基本的な導入は驚くほど簡単です。ただし、これを業務で本格的に利用する際には、セキュリティ設定の監査、利用ルールの策定、そして各モデルのライセンス確認といったガバナンス体制の構築が不可欠となります。
ステップ1:実行ツールの選定(Ollama, LM Studioなど)
まず、ローカルLLMを簡単に管理・実行するためのツールを選びます。代表的なツールは以下の2つです。
- Ollama: コマンドラインでの操作が基本。シンプルで動作が軽く、サーバーとして利用するのにも適しています。(出典:Ollama GitHub)
- LM Studio: グラフィカルな画面で直感的に操作できます。モデルの検索やダウンロード、チャットの実行がすべて画面上で行えるため、初心者でも迷わず使えます。(出典:LM Studio Documentation)
今回は、シンプルで応用範囲の広いOllamaを例に進めます。公式サイトからお使いのOSに合ったインストーラーをダウンロードし、画面の指示に従ってインストールを完了させてください。
ステップ2:モデルのダウンロードと設定
Ollamaのインストールが完了したら、ターミナル(WindowsではコマンドプロンプトやPowerShell)を開き、使いたいモデルをダウンロードします。例えば、Meta社のLlama 3.1(8Bモデル)を動かしたい場合は、以下のコマンドを一行入力して実行するだけです。
ollama run llama3.1:8b
このコマンドを実行すると、Ollamaが自動的にモデルのダウンロードを開始します。そのため、初回実行時にはインターネット接続が必要となる点にご注意ください。モデルのサイズによっては数分から数十分かかる場合があります。ダウンロードが完了すると、自動的に対話モードが始まります。
ステップ3:対話インターフェースでの実行と動作確認
ダウンロードが完了し、プロンプト(>>>)が表示されたら、もうローカルLLMと対話できる状態です。ChatGPTと同じように、自由に質問や指示を入力してみてください。PCのスペックにもよりますが、数秒ほどでAIからの応答が生成されます。
対話を終了したい場合は、「/bye」と入力するか、Ctrl+Dキーを押します。一度ダウンロードしたモデルはPC内に保存されるため、次回以降は同じコマンドを実行すれば、すぐにチャットを開始できます。

LLMのビジネス活用を本格的に学ぶならAX CAMP

ローカルLLMの導入方法は理解できたものの、「自社のどの業務に、どのモデルを適用すれば成果が出るのか」「独自のデータをどうやって学習させれば、本当に使えるAIになるのか」といった、より実践的な課題に直面している方も多いのではないでしょうか。
ツールの使い方を学ぶだけでは、ビジネスの成果には直結しません。重要なのは、AIの特性を深く理解し、自社の課題解決に結びつける「企画力」と「実装力」です。
私たちAX CAMPが提供する法人向けAI研修では、単なる知識のインプットに留まらず、貴社の実際の業務課題をテーマにした実践的なワークショップを通じて、AI活用のプロフェッショナル人材を育成します。
経験豊富なコンサルタントが、モデルの選定から業務への組み込み、費用対効果の算出まで、プロジェクトの立ち上げから実行までを徹底的に伴走サポート。「AIを導入したけれど、使いこなせていない」というよくある失敗を回避し、確実な成果創出へと導きます。
セキュリティポリシーが厳しい企業様向けに、ローカル環境でのAI活用に特化した研修プログラムのご提供も可能です。AI導入の第一歩でつまずかないために、まずは無料相談会で貴社の課題をお聞かせください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMのローカル導入で、安全かつ効率的なAI活用を実現しよう
本記事では、ローカルLLMの基本からメリット・デメリット、おすすめのモデル、そして具体的な導入手順までを網羅的に解説しました。最後に、重要なポイントを振り返ります。
- ローカルLLMの核心:適切に構成・運用すれば、データを外部に出すリスクを大幅に低減できる。
- 主なメリット:データ保護、オフライン利用、高度なカスタマイズ性。
- 主なデメリット:高性能PCへの初期投資と、運用に関する専門知識が必要。
- 導入方法:Ollama等のツールを使えば、初心者でも3ステップで簡単に導入可能。
- 成功の鍵:自社の目的(セキュリティ重視か、性能重視か、日本語能力か)に合ったモデルを選ぶこと。
ローカルLLMは、クラウド型AIのセキュリティ懸念を払拭し、企業のデータ資産を最大限に活用するための強力な選択肢です。導入にはハードルもありますが、それを乗り越えることで、他社には真似できない独自の競争力を生み出すことができます。
AX CAMPでは、この記事で紹介したようなローカルLLMの導入はもちろん、貴社の状況に合わせた最適なAI活用戦略の立案から人材育成までをワンストップで支援します。「何から手をつければ良いかわからない」「自社だけで進めるのは不安だ」と感じている方は、ぜひ一度、私たちの無料相談会をご活用ください。専門家が貴社のAI活用を成功へと導きます。

法人向けAI研修
AX CAMP 無料資料