

「LLM(大規模言語モデル)とディープラーニング、最近よく聞くけど違いがよくわからない」
「どちらもAIの技術らしいが、どういう関係性なの?」
このような疑問をお持ちではないでしょうか。AI技術の進化に伴い、専門用語に戸惑うビジネスパーソンは少なくありません。
LLMは、ディープラーニングという広範な技術を基盤として開発された
「自然言語処理に特化したAI」です。つまり、ディープラーニングという大きな枠組みの中に、LLMが存在するイメージです。この記事を読めば、両者の基本的な仕組みから決定的な違い、そして具体的なビジネス活用事例まで、網羅的に理解できます。
AI技術の全体像を正しく把握し、自社のビジネスにどう活かせるかのヒントを得るために、ぜひ最後までご覧ください。なお、当社
「AX CAMP」では、AI活用に関する豊富なノウハウを凝縮したお役立ち資料を提供しています。ご興味のある方は、ぜひダウンロードしてご活用ください。

法人向けAI研修
AX CAMP 無料資料
ディープラーニングとは?AI・機械学習との関係性
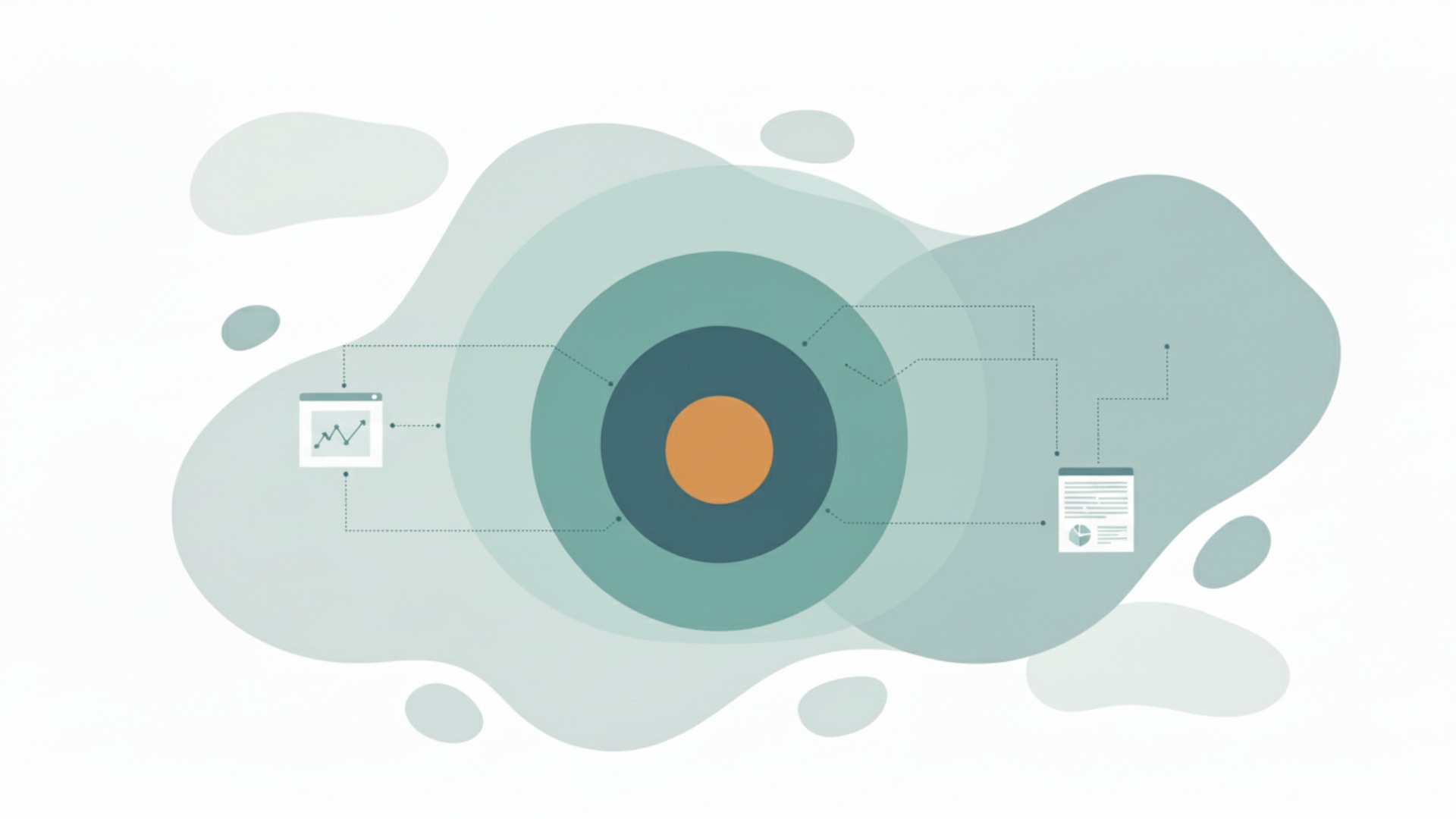
ディープラーニング(深層学習)は、AIを実現するための技術の一つです。具体的には、AIという広大な分野の中に「機械学習」があり、さらにその機械学習の一手法として「ディープラーニング」が位置づけられています。この関係性を理解することが、LLMを深く知る上での重要な第一歩となります。
機械学習がデータからパターンを学習する技術全般を指すのに対し、ディープラーニングは特に複雑で大規模なデータから、より高度な特徴を自動で抽出することを得意とします。この能力が、画像認識や音声認識といった分野で飛躍的な進歩をもたらしました。
人間の脳を模したニューラルネットワーク
ディープラーニングの根幹には「ニューラルネットワーク」という考え方があります。これは、人間の脳に存在する神経細胞(ニューロン)のネットワーク構造を、数学的なモデルで模倣したものです。
ニューラルネットワークは、情報を入力する「入力層」、情報を処理する複数の「中間層(隠れ層)」、そして最終的な結果を出す「出力層」から構成されます。ディープラーニングでは、この中間層を何層にも深く重ねる(Deep)ことで、データが持つ単純な特徴から複雑で抽象的な特徴までを段階的に学習していきます。この多層構造により、従来の機械学習では困難だった高度なパターン認識が実現できるのです。
AI・機械学習・ディープラーニングの包含関係
AI、機械学習、ディープラーニングの関係は、よく同心円で表現されます。一番大きな円が「AI(人工知能)」、その中に「機械学習」、さらにその中心に「ディープラーニング」が存在するイメージです。
- AI(人工知能):人間の知的な振る舞いを模倣する技術や概念の総称。
- 機械学習:AIを実現するための一分野。データから学習し、ルールやパターンを発見する技術。
- ディープラーニング:機械学習の一手法。多層のニューラルネットワークを用いて、より複雑な問題を解決する技術。
つまり、ディープラーニングはAIを実現するための最先端のアプローチの一つであり、多くのAIサービスがこの技術を基盤としています。この関係性を理解しておけば、次々と登場する新しいAI技術の位置づけも把握しやすくなるでしょう。


LLM(大規模言語モデル)とは?ディープラーニングを基盤とした技術

LLM(Large Language Model: 大規模言語モデル)は、その名の通り、ディープラーニングの技術を応用して構築された、自然言語処理に特化したAIモデルです。 インターネット上の膨大なテキストデータをはじめとする多様な情報を学習することで、人間のように自然な文章を生成したり、文脈を理解したりする能力を獲得しています。
ChatGPTに代表される対話型AIサービスの根幹をなすのが、このLLMです。ディープラーニングという汎用的な技術基盤の上に、言語という特定の領域に特化させて高度な能力を発揮させているのがLLMである、と理解すると分かりやすいでしょう。
大量の多様なデータで学習した言語モデル
LLMの能力の源泉は、学習に用いる圧倒的な量のデータにあります。従来はテキストが中心でしたが、近年は画像、音声、コードなどを含むマルチモーダルなデータを組み合わせて学習する例が増えています。
この多様なデータ学習を通じて、LLMは単に単語を並べるだけでなく、人間が書いたかのような自然で論理的な文章を生成する能力を身につけます。質問応答、文章要約、翻訳、アイデア出しなど、幅広い言語関連タスクをこなせるのは、この膨大な知識が背景にあるためです。
Transformerモデルが技術的なブレークスルーに
LLMの発展において技術的な転換点となったのが、2017年にGoogleの研究者が発表した「Transformer」というディープラーニングモデルです。 現在の主要なLLM(例えばOpenAIのGPTシリーズなど)は、このTransformerをベースに構築されています。(出典:Attention Is All You Need)
Transformerの最大の特徴は、「Attention(アテンション)機構」と呼ばれる仕組みにあります。 これは、文章中のどの単語とどの単語が関連深いのかを判断し、重要な部分に「注目」しながら文脈を捉える技術です。この仕組みにより、従来モデルが苦手としていた長い文章の文脈理解能力が飛躍的に向上し、現在の高精度なLLMの実現につながりました。
https://media.a-x.inc/llm-architecture
法人向けAI研修
AX CAMP 無料資料
LLMとディープラーニングの仕組みをわかりやすく解説
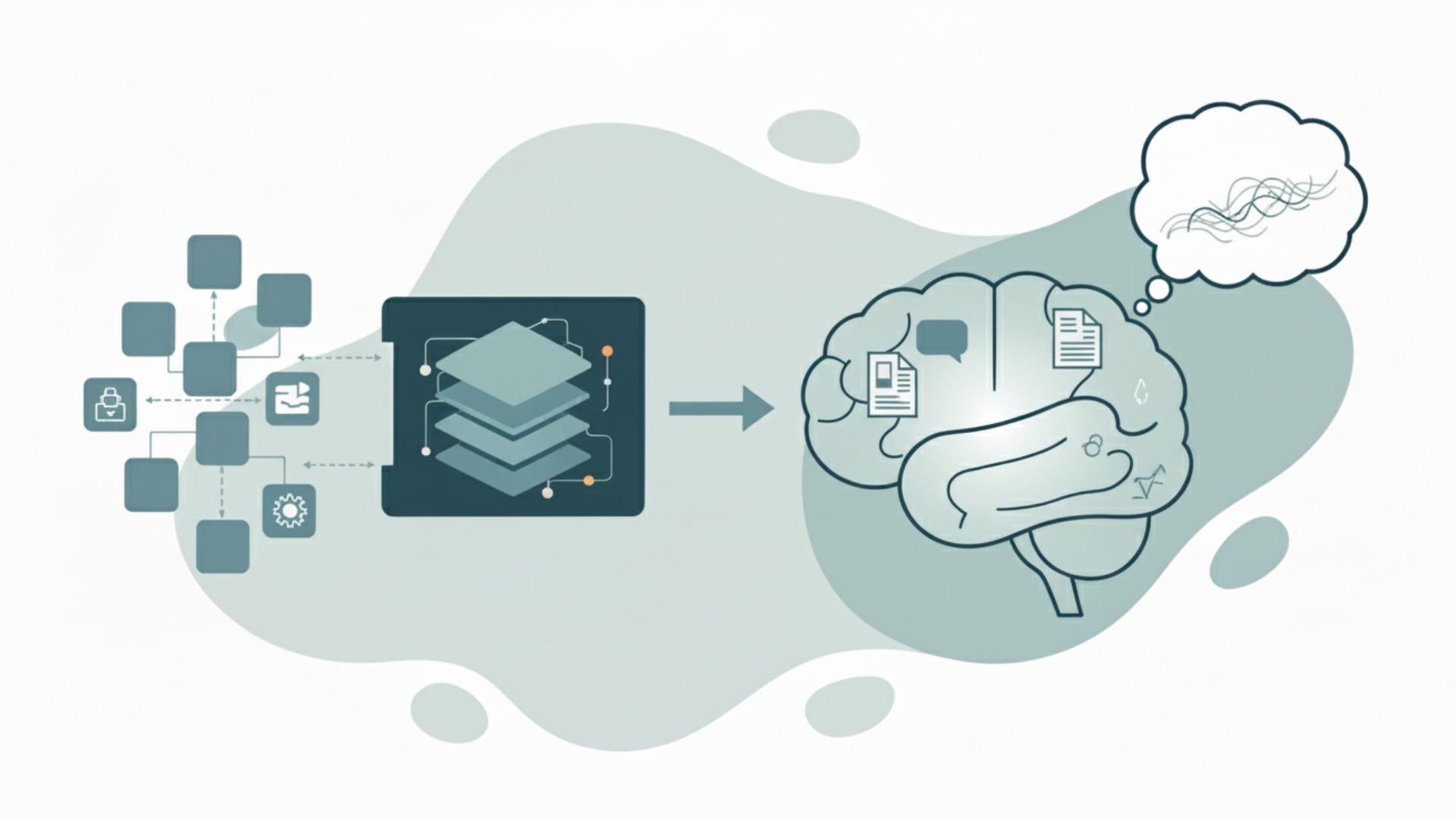
LLMとディープラーニングは密接に関連していますが、その処理の仕組みには明確な違いがあります。ディープラーニングが画像や音声など多様なデータから特徴を自動で学ぶ汎用的な仕組みであるのに対し、LLMはその仕組みを言語データに特化させ、文脈に応じた最適な単語を予測するタスクを極めることで自然な文章生成を実現しています。
ここでは、それぞれの代表的な処理プロセスを例に、仕組みの違いをより具体的に見ていきましょう。
画像認識を例にしたディープラーニングの学習プロセス
ディープラーニングが力を発揮する代表的な分野が画像認識です。例えば、AIに「猫」の画像を認識させる場合、その学習プロセスは以下のようになります。
まず、AIは画像のピクセルという点の集合体から、エッジ(輪郭)や色の塊といった単純な特徴を捉えます。次に、それらの単純な特徴を組み合わせて、耳や目、ひげといった、より複雑なパーツを認識します。そして最終的に、それらのパーツの組み合わせパターンから「これは猫である」と判断するのです。
このとき、どの特徴に着目すべきかを人間が教えるのではなく、AIが大量の猫の画像データから自動的に学習する点がディープラーニングの最大の特徴です。この階層的な特徴抽出の仕組みが、製造業における製品の異常検知など、様々な分野で応用されています。
LLMが自然な文章を生成する仕組み
一方、LLMが文章を生成する仕組みは、単に「次に来る単語を予測する」だけではありません。まず、大規模なデータで文脈に応じた次のトークン(単語や文字の一部)を予測する能力を事前学習で獲得します。
その上で、指示チューニングやRLHF(人間のフィードバックによる強化学習)といった微調整の工程を経て、より実用的で一貫した出力を生成するよう最適化されます。 このプロセスにより、単なる単語の羅列ではない、文脈に沿った自然で論理的な文章を作り出すことができるのです。
つまり、ディープラーニングがデータの特徴を階層的に捉えるのに対し、LLMは事前学習と微調整を通じて、文脈に依存した複雑なトークン生成能力を発揮していると言えます。
https://media.a-x.inc/llm-neural-network
LLMとディープラーニングの決定的な違いを3つの観点で比較
ここまで解説してきたように、LLMはディープラーニングという技術を基盤としていますが、両者には明確な違いがあります。その違いを「目的と用途」「学習データ」「モデルの構造」という3つの観点で比較することで、それぞれの特性をより深く理解することができます。
以下の比較表は、両者の違いを端的にまとめたものです。
| 観点 | ディープラーニング | LLM(大規模言語モデル) |
|---|---|---|
| 目的と用途 | 画像認識、音声認識、異常検知など、汎用的なパターン認識や特徴抽出 | 文章生成、要約、翻訳、対話など、自然言語処理に特化したタスク |
| 学習データ | 画像、音声、数値データなど、多種多様な構造化・非構造化データ | テキストを中心に、画像や音声などを含むマルチモーダルなデータ |
| モデルの構造 | CNN(画像)、RNN(時系列データ)など、タスクに応じて様々な構造を使い分ける | Transformerアーキテクチャが主流 |
目的と用途(汎用的な特徴抽出 vs 自然言語処理特化)
最も大きな違いは、その目的と用途にあります。ディープラーニングは、画像から特定の物体を見つけ出したり、音声データから話者を識別したりと、様々なデータに潜むパターンや特徴を抽出するための汎用的な技術です。自動車の自動運転や医療画像の診断支援など、幅広い分野で活用されています。
一方でLLMは、その応用範囲を自然言語処理(NLP)に特化させています。人間との対話、長文の要約、外国語の翻訳、クリエイティブな文章の作成など、言葉に関わるあらゆるタスクを高い精度で実行することを目的に設計されています。
学習データ(多様なデータ vs テキスト・マルチモーダルデータ)
学習に用いるデータの種類も異なります。ディープラーニングは、その用途に応じて画像、音声、センサーデータ、株価のような数値データまで、非常に多様な種類のデータを扱います。
対するLLMは、学習データのほとんどがテキストデータです。インターネット全体に匹敵するほどの膨大なテキストを学習することで、言語の複雑なニュアンスや文脈を深く理解する能力を獲得しています。(出典:NICT)
モデルの構造(CNN, RNNなど vs Transformerベース)
技術的な心臓部であるモデルの構造にも違いが見られます。ディープラーニングでは、タスクの性質に合わせて最適なモデルが選択されます。例えば、画像認識ではCNN(畳み込みニューラルネットワーク)、音声認識や時系列データの予測ではRNN(再帰型ニューラルネットワーク)といったモデルが伝統的に使われてきました。
これに対し、現在の高性能なLLMは、そのほとんどがTransformerモデルをベースにしています。 長い文章の文脈を効率的に処理できるTransformerの登場が、LLMの性能を飛躍的に向上させるブレークスルーとなりました。


【2026年最新】LLMとディープラーニングのビジネス活用事例

ディープラーニングとLLMは、その特性の違いから、ビジネスの現場でも異なる形で活用が進んでいます。ディープラーニングは主に専門領域での精度向上や自動化に、LLMは幅広い業務の効率化や新たな顧客体験の創出に貢献しています。具体的な事例を見ていきましょう。
【ディープラーニング活用】製造業における製品の異常検知
製造業の品質管理は、ディープラーニングの活用が特に進んでいる分野の一つです。工場の生産ラインを流れる製品の画像をAIがリアルタイムで解析し、熟練検査員の判断を補助することで高精度な検知を実現します。
これは、AIが大量の正常な製品画像を学習し、それとは異なるパターンを持つものを「異常」として検出する仕組みです。人による目視検査と組み合わせることで、検査の精度と速度を大幅に向上させ、品質の安定化と生産性向上に大きく貢献しています。
【LLM活用】幅広い業務の自動化と効率化
LLMは、カスタマーサポートからマーケティング、採用まで幅広い領域で大きな成果を上げています。例えば、Web広告運用代行のInmark様では、AX CAMPで学んだAI活用により広告チェック業務を自動化。これまで担当者が毎日1時間以上かけていた手動確認作業の工数をほぼゼロに削減しました。(出典:AIの活用事例を紹介!成功例から学ぶ導入のポイントや注意点)
また、SNS広告などを手掛けるWISDOM合同会社様の事例では、AI導入によって一部業務の工数を削減し、業務の再配置に繋がりました。さらに、美容健康食品を扱うエムスタイルジャパン様では、コールセンターの履歴確認業務などを自動化し、全社で月100時間以上の業務削減を実現しています。(出典:AI-RAGとは?RAGとの違いや活用事例、導入のポイントを解説)
https://media.a-x.inc/llm-use-cases
LLM技術の最新トレンドと今後の展望【2026年】

LLM技術は現在も急速に進化を続けており、ビジネスへのインパクトは今後さらに拡大していくと予測されています。2025年現在の最新トレンドとして特に注目すべきは、「マルチモーダル化」と「AIエージェント」の2つの方向性です。
これらの進化は、AIがより人間に近い形で情報を処理し、自律的にタスクをこなす未来を示唆しています。
マルチモーダル化の加速(テキスト+画像・音声)
これまでのLLMは主にテキストデータを扱ってきましたが、最新のモデルはテキストに加えて画像、音声、動画といった複数の種類の情報(モダリティ)を同時に理解し、処理できるようになっています。 これをマルチモーダルAIと呼びます。(出典:プログラミングでChatGPTの限界を超える 第5回 マルチモーダルAIの概要と画像と言語のマルチモーダルAIの仕組み)
例えば、製品の画像を見せながら「このデザインの改善点を教えて」と質問したり、会議の音声データから議事録とタスクリストを同時に生成したりすることが可能になります。このマルチモーダル対応の強化により、ビジネスにおける応用の幅を大きく広げることが期待されています。
AIエージェントによる自律的なタスク実行
もう一つの大きなトレンドが、AIエージェントの進化です。これは、ユーザーが大まかな指示を与えるだけで、AIが自ら計画を立て、必要なツール(Web検索、アプリ操作など)を使いこなし、タスクを自律的に実行するというものです。
例えば、「来週の大阪出張を手配して」と指示すれば、AIエージェントが交通機関の予約、ホテルの確保、カレンダーへの登録までを自動で行ってくれるイメージです。2025年現在、この分野の研究開発は活発化しており、将来的にはAIが人間のアシスタントとして、より複雑で多段階にわたる業務を代行するようになると考えられています。
https://media.a-x.inc/llm-multimodal
LLM・ディープラーニングのビジネス活用ならAX CAMP

LLMやディープラーニングの可能性を理解しても、「自社のどの業務に、どうやって導入すれば成果が出るのか」を見極めるのは容易ではありません。技術の選定ミスや不十分な活用計画は、投資対効果を得られないばかりか、プロジェクトの頓挫につながるリスクもあります。
もし、あなたがAI導入の具体的な進め方や、成果に直結するユースケースの選定にお悩みなら、ぜひ一度AX CAMPにご相談ください。当社は単なる研修提供に留まらず、これまで600社以上の企業様に対して、AI活用の戦略立案から具体的な業務改善、内製化までをトータルで支援してきました。
AX CAMPの法人向けAI研修では、貴社の具体的な課題や業務内容をヒアリングした上で、最適なAI技術の選定と、実務に即した研修カリキュラムをオーダーメイドでご提案します。「AIで何ができるか」を知るだけでなく、「AIで成果を出す」ための最短ルートを、経験豊富なコンサルタントが伴走しながらサポートします。何から手をつければ良いか分からない、という段階でも全く問題ありません。まずは無料相談にて、貴社の現状やお考えをお聞かせください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMとディープラーニングの違いを総括し、ビジネス活用を成功させよう
本記事では、LLMとディープラーニングの違いについて、その関係性から仕組み、ビジネス活用事例、最新動向までを網羅的に解説しました。
最後に、重要なポイントを改めて整理します。
- 関係性:LLMはディープラーニングという広範な技術を基盤とした、言語処理特化型のAI。
- 仕組み:ディープラーニングはデータの特徴を階層的に学習し、LLMは事前学習と微調整を通じて文脈に応じた最適な単語を予測・生成する。
- 違い:目的(汎用vs言語特化)、学習データ(多様vsテキスト・マルチモーダル)、モデル構造(多様vsTransformer)が異なる。
- 活用:ディープラーニングは異常検知など専門領域、LLMは問い合わせ対応など広範な業務効率化で成果を上げている。
- 将来性:マルチモーダル化とAIエージェント化が今後の大きなトレンド。
これらの技術は、もはや一部の専門家だけのものではありません。正しく理解し、自社の課題と結びつけることで、あらゆる企業がその恩恵を受けることができます。
しかし、AI導入を成功させるには、技術知識だけでなく、業務プロセスの理解や戦略的な視点が不可欠です。もし自社だけでAI活用を進めることに不安を感じる場合は、専門家の支援を受けることが成功への近道となります。AX CAMPでは、貴社のAI活用を成功に導くための実践的な研修と伴走支援を提供しています。ご興味のある方は、ぜひお気軽にお問い合わせください。

法人向けAI研修
AX CAMP 無料資料