

LLM(大規模言語モデル)によるコード生成に、開発現場の注目が集まっています。
「単純作業を自動化して、もっと創造的な業務に集中したい」多くのエンジニアが抱えるこの願いを、LLMは現実のものとしつつあります。しかし、その能力を最大限に引き出すには、ツールの選定や指示の出し方にコツが必要です。便利な一方で、使い方を誤るとセキュリティリスクや品質低下を招く可能性も否定できません。
この記事では、2026年最新のLLMコード生成ツール7選から、自社に最適なツールの選び方、そして生成精度を最大化するプロンプト技術まで、開発現場で明日から使える実践的な知識を網羅的に解説します。AIを使いこなし、開発プロセスを次のステージへと引き上げるための具体的な方法がわかります。もし、より体系的かつ実践的にこれらのスキルを習得し、組織全体の開発力を底上げしたいとお考えなら、AX CAMPの研修プログラムがお役に立てるかもしれません。

法人向けAI研修
AX CAMP 無料資料
LLMによるコード生成とは?開発現場にもたらす変革

LLMによるコード生成は、自然言語(日本語や英語など)で指示を出すだけで、AIがプログラムコードを自動で作り出す技術です。この進化により、開発者はこれまで手作業で行っていたコーディングの一部をAIに任せられるようになり、開発プロセスに大きな変革が訪れています。特定の条件下では複雑なアルゴリズムの実装やデバッグ支援もできますが、最終的な検証と修正は人間の開発者が必要です。
この技術は、特にソフトウェア開発の初期段階や、定型的なコード作成において真価を発揮します。AIが生成したコードを土台として人間が修正・改善を加えることで、開発スピードを大幅に加速させることが可能です。次のセクションでは、その具体的な仕組みに迫ります。
コード生成の基本的な仕組み
LLMは、インターネット上に存在する膨大な量のソースコードや技術文書を事前に学習しています。この学習データの中から、人間が書いた指示(プロンプト)の意図に最も合致するコードのパターンを見つけ出し、出力するのが基本的な仕組みです。
モデルの内部では、「Transformer」と呼ばれるアーキテクチャが中心的な役割を果たします。この仕組みにより、コード全体の文脈や単語(トークン)間の関連性を深く理解し、単なるキーワードの一致だけでなく、意味的に適切なコードを生成できるのです。そのため、非常に複雑で論理的な要求にも応えることが可能になっています。
従来の開発手法との根本的な違い
従来の開発が、エンジニアが一行ずつ手でコードを記述する「手作業」中心だったのに対し、LLMを活用した開発は、AIとの「対話」や「協業」に近い形へと変化します。最も大きな違いは、開発者が「何を作るか(What)」という要件定義や設計に集中し、「どのように作るか(How)」という実装の詳細をAIに委ねられる点です。
この変化は、開発のボトルネックを「書く速度」から「的確に指示する能力」へとシフトさせます。結果として、エンジニアはより上流の創造的な工程に時間を割けるようになり、ソフトウェアの品質やイノベーションの創出に貢献しやすくなるのです。

LLMコード生成の主要な活用シーン
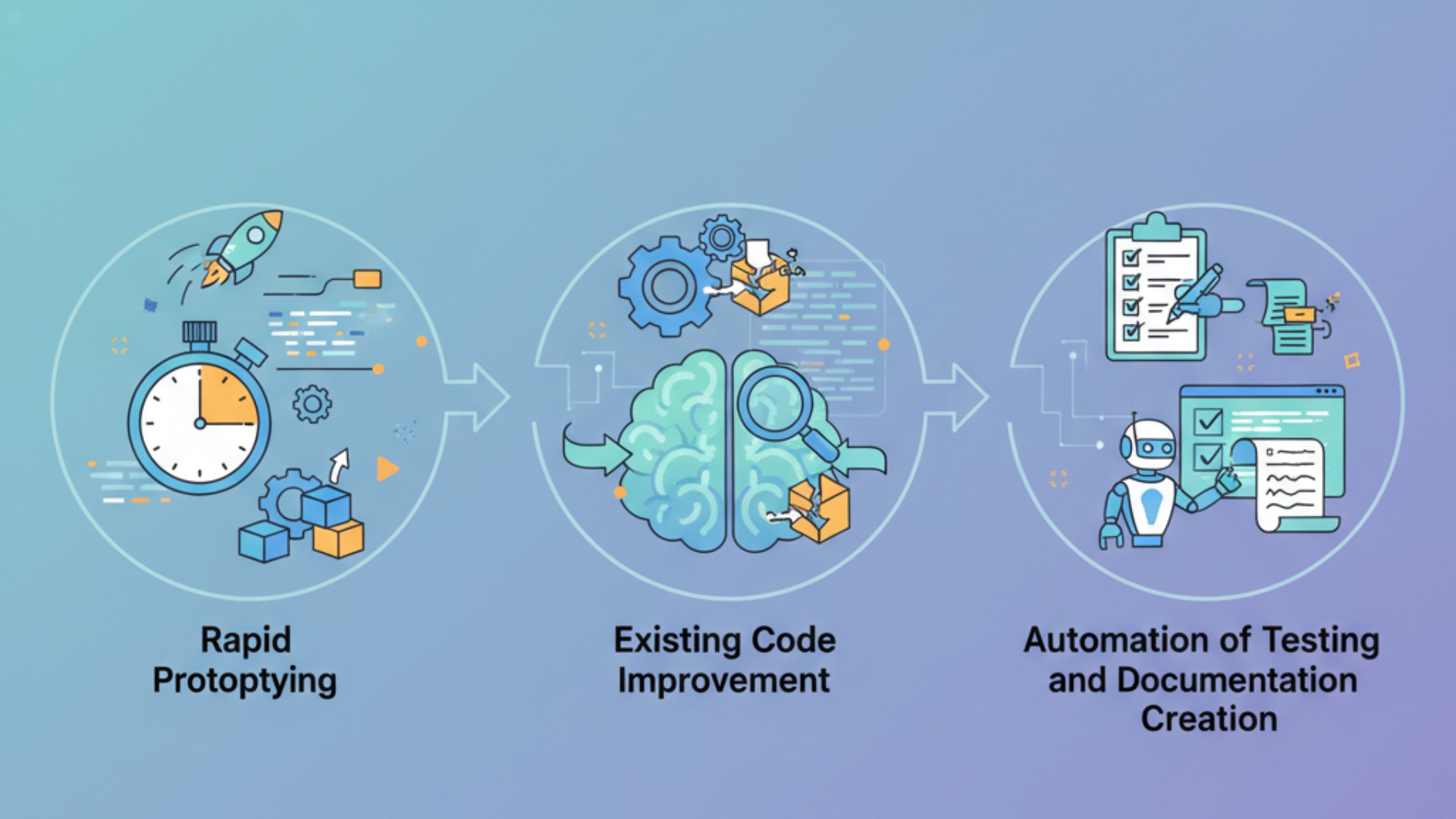
LLMによるコード生成は、開発ライフサイクルの様々な場面で活用できます。特に、プロトタイピングの高速化、既存コードの改善、そしてテストやドキュメント作成の自動化といった領域で大きな効果を発揮します。これらを活用することで、開発チームは生産性を大幅に向上させることが可能です。
具体的なシーンを理解することで、自社の開発プロセスにどのように組み込めるかのヒントが得られるでしょう。ここでは、代表的な3つの活用シーンを詳しく見ていきます。
新規コードの高速プロトタイピング
新しい機能やアプリケーションのアイデアを検証する際、LLMは非常に強力なツールとなります。プロジェクトの規模や指示の精度によっては、従来であれば数日かかっていたプロトタイプの作成が、数時間で完了するケースもあります。
例えば、「ユーザーログイン機能を持つ簡単なWebアプリケーションを、PythonのFlaskフレームワークで作成して」といった指示を出すだけで、基本的な骨格となるコード一式を生成できます。これにより、企画やアイデアの実現可能性を素早く判断し、迅速な意思決定につなげることが可能です。
既存コードのリファクタリングと品質向上
LLMは、既に存在するコードの品質を向上させる「リファクタリング」にも活用できます。読みにくいコードをよりクリーンな構造に書き換えたり、非効率な処理をよりパフォーマンスの高いロジックに改善したりする提案をAIから受けることが可能です。
さらに、コードに含まれる潜在的なバグや脆弱性を指摘させることもできます。これにより、人間の目だけでは見逃しがちな問題を早期に発見し、ソフトウェア全体の品質と保守性を高めることに繋がります。
実際に、AX CAMPの研修を導入したエムスタイルジャパン様では、手作業で行っていた業務の自動化スクリプト開発などにAIを活用。全社で月100時間以上の業務削減を実現し、エンジニアがより付加価値の高い業務に集中できる環境を構築しました。(出典:AI活用ワークショップ)
テストコードやドキュメントの自動生成
開発プロセスにおいて時間のかかる作業の一つが、テストコードとドキュメントの作成です。LLMはこれらの作業を大幅に自動化できます。作成した関数やクラスの仕様をLLMに与えることで、その動作を検証するためのテストコードを自動で生成させることが可能です。
同様に、コードの内容を解析させ、その機能や使い方を説明するドキュメント(READMEファイルやAPI仕様書など)の草案を作成させることもできます。これらの定型的ながらも重要な作業を自動化することで、開発者はコアなロジックの実装にさらに集中できるようになります。

【2026年最新】コード生成に強いLLMツール7選

2025年現在、コード生成の分野では各社から強力なLLMツールが提供されており、その競争は激化しています。それぞれのツールは対応言語、IDE(統合開発環境)との連携、そして得意とするタスクが異なります。自社の開発環境やプロジェクトの特性に合わせて最適なツールを選ぶことが、生産性向上の鍵となります。
ここでは、現在市場で高く評価されている7つの主要なコード生成LLMツールをピックアップし、それぞれの特徴を解説します。商用モデルからオープンソースまで、幅広い選択肢を見ていきましょう。
1. GPT-5
OpenAIがリリースしたGPT-5は、コーディング能力が大幅に強化されています。特に、UI生成やリポジトリ全体を横断したデバッグ能力に優れており、より実践的な開発シーンでの活用が期待されています。GitHub Copilotなどの主要なAIコーディングアシスタントの頭脳としても採用されており、業界標準の地位を確立しています。(出典:Introducing GPT-5)
APIを通じて、開発者は出力の冗長性や思考の深さをコントロールできるパラメータを利用でき、より柔軟なツール連携や自動化ワークフローの構築が可能です。
2. Anthropic Claude 4 Pro
Anthropic社のClaude 4 Proは、特に長文のコンテキスト理解能力と論理的推論に定評があります。大規模なコードベースや複雑なドキュメントを読み込ませ、その内容に基づいたコード生成やリファクタリングを得意とします。(出典:Models overview)
安全性を重視した設計も特徴で、脆弱性を含んだコードの生成を抑制するガードレール機能が他のモデルより強力に働く傾向があります。企業のコンプライアンス要件が厳しいプロジェクトや、セキュリティを特に重視する開発に適しています。
3. Google Gemini 2.5 Ultra
Googleが開発したGemini 2.5 Ultraは、マルチモーダル(テキスト、画像、音声などを統合的に扱える)能力が大きな特徴です。UML図や画面のスケッチといった視覚情報からコードの骨格を生成するなど、新しい開発スタイルを可能にします。(出典:Gemini API)
最大で100万トークンという広大なコンテキストウィンドウを持ち、非常に大規模なプロジェクト全体の文脈を理解した上でのコード生成が可能です。ただし、利用可能なトークン数はモデルのバージョンや提供形態によって異なるため、公式ドキュメントでの確認が必要です。
4. DeepSeek Coder V3
DeepSeek Coderは、コーディングに特化したオープンソースモデルとして高い評価を得ています。特に、数学的な問題解決能力やアルゴリズムの実装に強く、一部の主要なコーディングベンチマークにおいて、多くの商用モデルに匹敵する高い評価を得ています。(出典:DeepSeek API Updates)
オープンソースであるため、自社のサーバー上で運用(セルフホスティング)でき、セキュリティやプライバシーの要件が厳しい企業でも安心して利用できます。コストを抑えつつ、高性能なコーディング支援環境を構築したい場合に最適な選択肢の一つです。
5. Meta Llama 4 Code
Meta社が提供するLlama 4 Codeは、オープンウェイトモデルとして開発者コミュニティに公開されており、カスタマイズの自由度が高い点が魅力です。特に巨大なコンテキストウィンドウを持つモデルは、リポジトリ全体の分析や要約といったタスクで優れた性能を発揮します。(出典:Llama Models)
純粋なコード生成能力においても高い性能を発揮しますが、その真価は既存コードの深い理解が求められる場面や、特定のドメイン知識をファインチューニングで追加したい場合にあります。
6. GitHub Copilot Enterprise
GitHub Copilotは、多くの開発者にとって最も身近なAIペアプログラマーと言えるでしょう。IDEとのシームレスな統合が最大の特徴で、コーディング中にリアルタイムで文脈に応じたコード補完や関数生成の提案を行います。
Enterprise版では、組織内のプライベートリポジトリのコードを学習対象に含めることができ、組織独自のコーディング規約やアーキテクチャに準拠した、より精度の高い提案が可能になります。チーム全体の生産性向上とコード品質の標準化に大きく貢献します。(出典:Creating a custom model for GitHub Copilot)
7. Amazon CodeWhisperer Professional
Amazon CodeWhispererは、特にAWS(Amazon Web Services)を利用した開発に強みを持つツールです。AWSの各種サービス(S3, Lambda, DynamoDBなど)のAPIを正確に利用したコードを生成する能力に長けています。
生成したコードが特定のオープンソースライセンスに類似している場合に出典を提示し、意図しないライセンス違反のリスクを低減する機能も備えています。AWS中心の開発環境を持つ企業にとって、開発効率とコンプライアンス遵守を両立させるための強力な選択肢となります。(出典:Amazon CodeWhisperer)
https://media.a-x.inc/llm-tools自社に最適なLLMコード生成ツールの選び方

多種多様なLLMコード生成ツールの中から自社に最適なものを選ぶには、いくつかの重要な判断基準があります。特に「対応言語とフレームワーク」と「IDE連携と開発ワークフローへの統合性」は、開発チームの生産性に直接影響するため、慎重な検討が必要です。
これらの基準を元に自社の状況を評価することで、導入後のミスマッチを防ぎ、ツールの価値を最大限に引き出すことができます。それぞれのポイントを詳しく見ていきましょう。
対応言語とフレームワークの範囲
まず確認すべきは、自社がメインで使用しているプログラミング言語やフレームワークを、ツールがどの程度サポートしているかです。PythonやJavaScriptといった主要言語はほとんどのツールが対応していますが、より専門的な言語(Rust, Go, Swiftなど)や、特定のフレームワーク(Ruby on Rails, Django, .NETなど)への対応レベルには差があります。
ツールの公式サイトやドキュメントで対応範囲を確認するだけでなく、可能であればトライアルなどを利用して、実際のプロジェクトで使われるような複雑なコードがどの程度の精度で生成されるかを試すことが重要です。ツールの学習データに、自社が使う技術スタックが豊富に含まれているかどうかが、生成品質を左右します。
IDE連携と開発ワークフローへの統合性
ツールの使いやすさは、IDE(統合開発環境)との連携レベルに大きく依存します。多くの開発者が日常的に使用するVS CodeやJetBrains系のIDE(IntelliJ, PyCharmなど)に、拡張機能としてシームレスに統合できるかは非常に重要な選定基準です。
理想的なのは、コーディングを妨げることなく、必要な時にだけ自然な形でコード補完や提案が表示されるツールです。また、バージョン管理システム(Git)やCI/CDパイプラインといった既存の開発ワークフローに組み込めるかどうかも考慮すべき点です。ツール導入によって、既存のフローが複雑化したり、開発者の負担が増えたりするようでは本末転倒です。
コード生成の精度を最大化するプロンプトエンジニアリング術

LLMコード生成の精度は、AIに与える指示、すなわち「プロンプト」の質に大きく左右されます。優れたプロンプトエンジニアリングは、AIの能力を最大限に引き出し、意図通りで高品質なコードを得るための鍵となります。曖昧な指示ではなく、構造化された明確な指示を与えることが重要です。
ここでは、コード生成の精度を劇的に向上させるための、実践的な3つのプロンプトエンジニアリング術を紹介します。これらのテクニックを習得することで、AIとの対話をより効率的かつ効果的に進めることができます。
リファレンスを読み込ませてハルシネーションを防ぐ
LLMが事実に基づかない、もっともらしい嘘の情報を生成してしまう「ハルシネーション」は、コード生成においても問題となります。これを防ぐ有効な対策の一つが、プロンプトに正確なリファレンス(参考情報)を含めることです。
例えば、特定のライブラリの公式ドキュメントや、社内のコーディング規約などをプロンプトに含めて、「この情報に基づいてコードを生成してください」と指示します。これにより、LLMは与えられた情報源の範囲内で思考するようになり、不正確な情報や古いAPIの使用を避けられます。ただし、リファレンスに機密情報や個人情報を含める際は、匿名化処理を施すなど、情報漏洩リスクに十分注意する必要があります。
要件を構造化して伝える「思考プロセス」プロンプト
複雑な要件を一度に伝えようとすると、LLMは細部を見落としたり、解釈を誤ったりすることがあります。これを避けるためには、要件を分解し、構造化して伝えることが有効です。箇条書きやマークダウン形式を用いて、以下のように情報を整理します。
- 目的:何を実現したいのか
- 入力:どのようなデータを受け取るのか
- 処理手順:どのようなステップで処理を行うのか
- 出力:どのような形式で結果を返すのか
- 制約条件:考慮すべきパフォーマンスやセキュリティ上の要件
このように「思考のプロセス」を模倣した形で指示を与えることで、LLMは要件を正確に理解し、論理的で抜け漏れの少ないコードを生成しやすくなります。
生成コードにコメントを付与させる指示テクニック
AIが生成したコードは、一見正しく動作するように見えても、その内部ロジックが人間にとって理解しにくい場合があります。これでは、後のメンテナンスやデバッグが困難になります。そこで、プロンプトの最後に「各処理の意図がわかるように、詳細なコメントを日本語で追加してください」といった一文を加えることが非常に効果的です。
コメントを付与させることで、コードの可読性が向上するだけでなく、LLM自身が生成したロジックの妥当性を再確認するプロセスを促す効果も期待できます。これにより、より品質が高く、保守性に優れたコードを得ることができます。

実践!LLMを活用したコード生成の基本ステップ

LLMを効果的に活用したコード生成は、大きく2つのステップで構成されます。それは「明確な要件定義とプロンプトの作成」そして「コード生成と人間によるレビュー」です。このプロセスを体系的に行うことで、AIの能力を最大限に引き出しつつ、品質を担保することが可能になります。
各ステップで何をすべきかを理解し、実践することが成功への近道です。以下で、それぞれのステップの具体的な内容を見ていきましょう。
Step1: 明確な要件定義とプロンプトの作成
最初のステップは、AIに何をさせたいのかを明確にすることです。前述のプロンプトエンジニアリング術を活用し、実装したい機能の目的、仕様、制約条件などをできるだけ具体的に、かつ構造的に記述します。この段階の質が、最終的な生成物の品質をほぼ決定づけると言っても過言ではありません。
例えば、「ユーザーデータを保存する機能」といった曖昧な指示ではなく、「以下の仕様で、PostgreSQLデータベースにユーザー情報を保存するPython関数を作成してください。入力はユーザー名とメールアドレス。メールアドレスは重複を許さない制約を設けること。」のように、技術的な詳細を含めて具体化します。
Step2: コード生成と人間によるレビュー
作成したプロンプトをLLMツールに入力し、コードを生成させます。生成されたコードは、あくまで「下書き」や「第一稿」と捉えることが重要です。AIが生成したコードをそのまま利用するのではなく、必ず経験豊富なエンジニアがレビューを行います。
レビューでは、以下の点を確認します。
- 要件を満たしているか
- 潜在的なバグや脆弱性はないか
- コーディング規約に準拠しているか
- 保守性や拡張性は考慮されているか
AIは強力なアシスタントですが、最終的な品質に対する責任は人間が負います。この「AIによる生成」と「人間によるレビュー」のサイクルを回すことで、開発スピードと品質を両立させることができます。
LLMコード生成を導入・活用する際の注意点
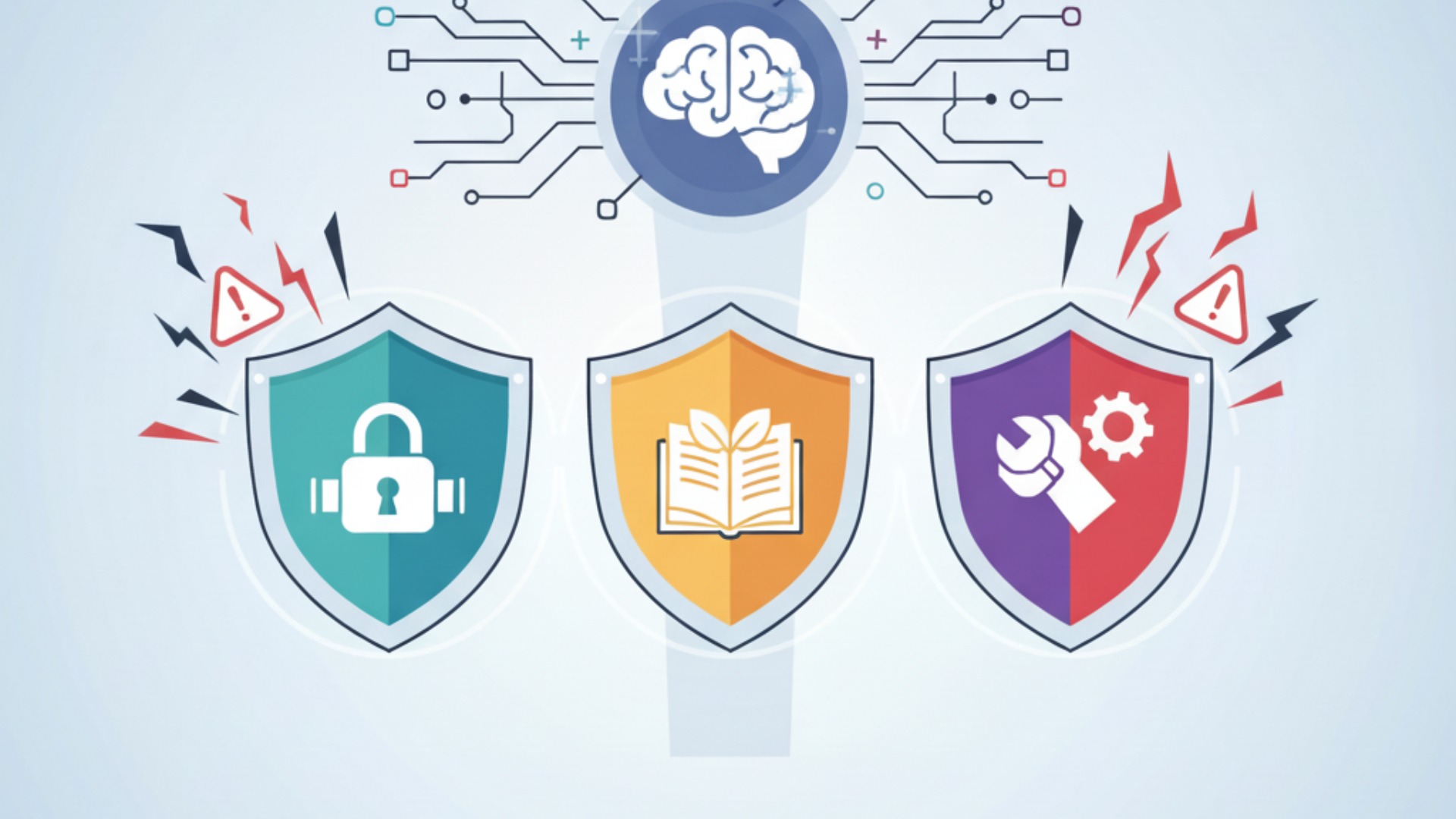
LLMによるコード生成は開発効率を飛躍的に向上させる可能性がある一方で、いくつかの重要な注意点が存在します。特に、セキュリティ、著作権、そして開発者のスキルといった側面でのリスクを理解し、対策を講じることが不可欠です。これらのリスクを軽視すると、将来的に大きな技術的負債や法的な問題につながる可能性があります。
ここでは、導入・活用を進める上で特に注意すべき3つのポイントについて詳しく解説します。
生成コードの潜在的な脆弱性と品質問題
LLMは、学習データに含まれる大量のコードを基に生成を行いますが、その学習データには脆弱性を含むコードも含まれている可能性があります。そのため、AIが生成したコードを無批判に受け入れると、意図せずセキュリティ上の弱点を作り込んでしまうリスクがあります。実際、単純な指示で生成されたコードには、一般的な脆弱性が含まれることが多いという調査結果も報告されています。
このリスクを軽減するためには、生成されたコードに対して静的解析セキュリティテスト(SAST)ツールを適用したり、経験豊富な開発者が手動でセキュリティレビューを行ったりするプロセスが不可欠です。AIはあくまで補助ツールであり、品質保証の最終責任は開発チームにあることを常に意識する必要があります。
著作権およびライセンスのコンプライアンス
LLMが学習したコードの中には、様々なオープンソースライセンスが付与されたものが含まれています。LLMが生成したコードが、これらの既存コードと酷似している場合、意図せず著作権を侵害したり、自社のソフトウェアに望まないライセンス(例:ソースコードの公開義務があるコピーレフト型ライセンス)を適用しなければならなくなったりするリスクがあります。
この問題に対処するためには、Amazon CodeWhispererのようにライセンスの参考情報を提示する機能を持つツールを選択することも有効な対策の一つです。ただし、これらの機能は完全ではなく、企業は独自のライセンスチェックを併用し、法務部門とも連携しながら慎重に運用するべきです。

AIへの過度な依存によるスキル陳腐化のリスク
LLMコード生成ツールが非常に便利なため、開発者が思考停止に陥り、AIに頼りきりになってしまうリスクも指摘されています。特に、経験の浅い開発者が基本的なアルゴリズムやプログラミングの原理を学ぶ機会を失い、表面的な問題解決能力しか身につかない可能性があります。
これを防ぐためには、AIが生成したコードの「なぜそうなるのか」を深く理解しようと努める文化を醸成することが重要です。コードレビューの際に、生成ロジックの背景を説明させたり、チーム内で定期的に勉強会を開いたりするなど、AIを「思考を補助するツール」として使いこなし、開発者自身のスキル向上につなげるための工夫が求められます。
2025年以降のLLMコード生成の進化予測

LLMによるコード生成技術は、今後も急速な進化を続けると予測されています。2025年以降は、単にコードを生成するだけでなく、より自律的に開発プロセス全体を担う「AIエージェント」の普及や、特定の業務領域に深く特化した「ファインチューニングモデル」の一般化が進むでしょう。これにより、ソフトウェア開発のあり方そのものが、さらに大きく変わっていく可能性があります。
これらの未来のトレンドを理解することは、今からAI活用戦略を立てる上で非常に重要です。それぞれの進化の方向性について、具体的に見ていきましょう。
自律的に開発を進めるAIエージェントの普及
将来的には、「〇〇という機能を作って」といった曖昧な指示だけで、AIが自ら仕様を具体化し、コーディング、テスト、デバッグ、さらにはデプロイまでを一貫して行う「AIエージェント」が普及すると考えられています。2025年現在、すでにその初期段階にあるツールも登場しており、開発プロセスにおける人間の役割は、AIエージェントの監督や最終的な意思決定へとシフトしていく可能性があります。
このようなAIエージェントが一般化すれば、開発サイクルは劇的に短縮され、人間はより創造的で戦略的なタスクに集中できるようになります。企業にとっては、市場の変化に迅速に対応できるアジャイルな開発体制を、これまで以上に高いレベルで実現できることを意味します。
特定ドメインに特化したファインチューニングモデルの一般化
汎用的な大規模言語モデルを、特定の業界や企業のデータで追加学習させる「ファインチューニング」が、より手軽に行えるようになります。これにより、例えば「医療業界の規制に準拠したコード」や「自社の複雑な業務ロジックを理解したコード」を高精度で生成する、ドメイン特化型LLMを各企業が持つことが一般的になるでしょう。
ファインチューニングされたモデルは、専門用語や業界特有の文脈に対する理解が深いため、汎用モデルに比べてハルシネーション(誤った情報の生成)が少なく、より信頼性の高いコードを生成できます。これにより、これまで自動化が難しかった専門性の高い領域でも、AIによる開発支援の恩恵を受けられるようになります。
AX CAMPの研修を導入したWISDOM合同会社様では、AI活用スキルの習得を通じて業務自動化を推進。その結果、採用予定だった2名分の業務負荷をAIで完全に代替することに成功し、事業成長を加速させています。(出典:採用予定2名分の業務をAIが代替!WISDOM社、毎日2時間の調整業務を自動化)

LLMコード生成のスキルを実践的に学ぶならAX CAMP

LLMによるコード生成の可能性を最大限に引き出し、自社の開発プロセスを革新するためには、ツールの使い方を覚えるだけでなく、その背景にある原理や、効果的な活用戦略、そして潜在的なリスクへの対処法までを体系的に理解することが不可欠です。しかし、これらの知識を独学や断片的な情報だけで習得するのは容易ではありません。
もし、貴社がLLMをはじめとするAI技術を本格的に導入し、開発チーム全体の生産性を飛躍的に向上させたいとお考えなら、実践的なスキル習得に特化した「AX CAMP」が最適な解決策となります。AX CAMPは、単なる座学ではなく、貴社の実際の開発課題をテーマにした演習を通じて、明日から現場で使える生きたスキルを身につけることに重点を置いています。
例えば、本記事で紹介したようなプロンプトエンジニアリングの高度なテクニックや、複数のLLMツールを適材適所で使い分ける選定眼、さらには生成されたコードの品質を担保するためのレビュー手法まで、専門家の伴走支援を受けながら実践形式で学ぶことができます。これにより、AIを「使う」だけのレベルから、「使いこなす」レベルへとステップアップし、開発チームのパフォーマンスを最大化することが可能です。実際に、AX CAMPを導入したRoute66様では、これまで24時間かかっていた原稿執筆がわずか10秒で完了するなど、劇的な業務効率化を達成した事例もございます。(出典:原稿執筆が24時間→10秒に!Route66社が実現したマーケ現場の生成AI内製化)まずは、貴社の課題や目標について、お気軽にご相談ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMによるコード生成を理解し開発を次のステージへ
本記事では、LLMによるコード生成の基本から、2026年最新のおすすめツール、精度を高めるプロンプト術、そして導入時の注意点まで、幅広く解説しました。LLMは、正しく理解し活用すれば、開発の生産性を劇的に向上させる強力な武器となります。
この記事の要点を以下にまとめます。
- LLMコード生成はAIとの対話による開発を実現し、生産性を向上させる
- GPT-5やGoogle Gemini 2.5 Ultraなど、用途に応じて多様なツールが存在する
- 精度はプロンプトの質に大きく依存し、構造化された指示が重要である
- 生成コードには脆弱性や著作権のリスクが伴うため、人間によるレビューが不可欠である
- 将来的には自律型AIエージェントやドメイン特化モデルが主流になる
これらの技術を自社に導入し、競争優位性を確立するためには、ツールの導入と並行して、開発者一人ひとりがAIを使いこなすスキルを習得することが不可欠です。AX CAMPでは、貴社の状況に合わせたカリキュラムを通じて、LLMコード生成をはじめとするAI活用の実践スキルを体系的に学ぶことができます。専門家の伴走支援のもと、AIを真の力に変え、開発組織全体のパフォーマンスを次のステージへと引き上げるお手伝いをします。ご興味のある方は、ぜひ一度無料相談会へお越しください。

法人向けAI研修
AX CAMP 無料資料