

「LLM」「ChatGPT」「生成AI」といった言葉を耳にする機会が増えたものの、それぞれの違いや関係性を正確に説明できる方は少ないのではないでしょうか。また、自社のビジネスにどう活かせるのか、具体的なイメージが湧かないという方も多いはずです。これらの技術は、正しく理解し活用することで、業務効率を劇的に改善し、新たなビジネスチャンスを生み出す可能性を秘めています。
この記事では、LLM(大規模言語モデル)の基本的な仕組みから、ChatGPTや生成AIとの違い、そして具体的なビジネス活用事例までを網羅的に解説します。最新のLLMモデルの動向や、導入時に押さえるべきポイント、注意点についても触れていきますので、読み終える頃には、自社でLLMを活用するための具体的な第一歩が明確になるでしょう。より実践的なAI導入ノウハウや研修プログラムに関心のある方は、AX CAMPが提供する資料もぜひ参考にしてください。

法人向けAI研修
AX CAMP 無料資料
LLM(大規模言語モデル)とは?ChatGPTの基盤技術を理解する

LLM(Large Language Models)とは、大量のテキストデータから言語のパターンを学習し、人間のように自然な文章を生成したり対話したりできるAI技術です。現在話題のChatGPTをはじめ、多くの対話型AIサービスの根幹をなす中核技術と考えると分かりやすいでしょう。その能力は単なる文章作成に留まらず、翻訳、要約、質疑応答、さらにはプログラムコードの生成まで多岐にわたります。
大量のテキストデータからパターンを学習するAI
LLMは、膨大なテキストデータを学習することで言語のパターンを掴みます。そのデータはインターネット上のWebサイトや書籍、論文など多岐にわたり、数百ギガバイトから数テラバイトに及ぶことも珍しくありません。この膨大なデータの中から、単語と単語のつながりや文法、文脈といった言語に関するあらゆるパターンを統計的に学習します。これにより、特定の質問に対して、次に来る確率が最も高い単語を予測し連結させることで、自然な文章を生み出しているのです。
自然な文章生成と高度な文脈理解能力
LLMが持つ最大の特徴は、その卓越した文章生成能力と文脈理解能力にあります。まるで人間が書いたかのような自然で流暢な文章を作り出せるだけでなく、会話の文脈や質問に込められた複雑な意図を正確に読み取ることができます。例えば、「今日の天気は?」「傘は必要?」といった連続した質問に対しても、前の会話の流れを記憶し、文脈に沿った適切な回答を生成できます。この能力が、高機能なチャットボットやコンテンツ作成といった分野で大きな力を発揮するのです。
自己回帰モデルとトランスフォーマー技術
LLMの性能を飛躍的に向上させたのが、「トランスフォーマー(Transformer)」と呼ばれる深層学習モデルです。2017年にGoogleが発表したこの技術は、文章中のどの単語に注目すべきかを判断する「アテンション(Attention)機構」という仕組みを持っています。この仕組みのおかげで、文章が長くなっても重要な単語の関係性を見失うことなく、文脈を正確に捉えられるようになりました。多くの対話型LLMは、このトランスフォーマー技術と、次に来る単語を予測し続ける「自己回帰モデル」を組み合わせることで、現在の高い性能を実現しています。ただし、Transformer系の技術には文章分類などに使われるエンコーダーのみのモデル(例: BERT)や、翻訳で用いられるエンコーダー・デコーダーモデル(例: T5)もあり、用途に応じて使い分けられています。
https://media.a-x.inc/llm-architecture
ファインチューニングによる特定タスクへの特化
汎用的なデータで学習させたLLMを、さらに特定の業界や業務に関する専門データで追加学習させることを「ファインチューニング(Fine-tuning)」と呼びます。例えば、医療分野の論文データを追加学習させれば、医療用語に詳しく専門的な質問にも答えられるLLMを開発できます。同様に、自社の問い合わせ履歴を学習させれば、顧客対応に特化した高精度なチャットボットの構築も可能です。ただし、ファインチューニングを行う際は、使用するデータの著作権やライセンスをクリアにし、個人情報が含まれる場合は適切に匿名化処理を施すなど、法務・倫理的な配慮が不可欠です。

従来の言語モデルとの決定的な違い
従来の言語モデルとLLMとの決定的な違いは、そのモデルの規模(パラメータ数)と、それによってもたらされる文脈理解の深さにあります。従来のモデルは、比較的単純な統計手法に基づき、直前の数単語から次に来る単語を予測する程度でした。一方、LLMは何十億、何百億というパラメータを持ち、トランスフォーマー技術によって文章全体の複雑な関係性を捉えることができます。これにより、単なる単語の予測を超え、文章の背後にある意味やニュアンスまで理解した、質の高い応答が可能になったのです。
https://media.a-x.inc/llm-parameters
LLMが急速に注目される背景

LLMがここ数年で急速に注目を集めるようになった理由は、技術的なブレークスルー、計算能力の向上、そして利用しやすさという3つの要因が重なったためです。これらの要素が相互に作用し、AI技術が研究室レベルから、誰もが手軽に利用できる実用的なツールへと進化する土壌を形成しました。特に、2022年末に登場したChatGPTは、その流れを決定的なものにしました。
トランスフォーマーモデルの登場による性能向上
前述の通り、2017年に発表された「トランスフォーマー」モデルの登場が、LLMの進化における最大の転換点となりました。この技術により、AIは文章の長期的な依存関係、つまり文頭と文末にあるような離れた単語同士の関連性も効率的に学習できるようになったのです。その結果、言語モデルの性能は劇的に向上し、より長く、より複雑で、より論理的な文章の生成が可能になりました。これが、現在の高度な対話型AIの技術的な基盤となっています。
コンピューティングパワーの飛躍的進化
LLMの開発と運用には、膨大な計算能力(コンピューティングパワー)が欠かせません。GPU(Graphics Processing Unit)をはじめとする半導体技術の進化により、これまで不可能だった規模の計算が、より短時間で、より低コストで実行できるようになりました。このハードウェアの進化が、何千億ものパラメータを持つ巨大なLLMの開発を後押しし、AIの性能向上を支える物理的な基盤となっています。クラウドコンピューティングサービスの普及も、多くの企業や研究者が大規模な計算リソースにアクセスしやすくなる一因となりました。
オープンソース化とAPI提供によるアクセスの民主化
かつて最先端のAI技術は、一部の巨大IT企業や研究機関だけがアクセスできるものでした。しかし近年では、Meta社の「Llama」シリーズのように、高性能なLLMがオープンソースとして公開されるケースが増えています。また、OpenAIやGoogleなどが自社のLLMをAPI(Application Programming Interface)として提供し始めたことで、開発者は複雑なAIモデルを自前で構築することなく、自社のサービスに高度なAI機能を組み込めるようになりました。技術へのアクセスが民主化されたことで、世界中の開発者がLLMを活用した新しいアプリケーションを生み出すエコシステムが形成されたのです。
https://media.a-x.inc/llm-open-source
ChatGPTの登場による社会的認知度の向上
LLMの注目度を決定的に高めたのが、2022年11月にOpenAIが公開した「ChatGPT」です。誰でも無料で簡単に利用できる革新的なインターフェースと、人間と対話しているかのような自然で高精度な応答は、世界中に衝撃を与えました。ChatGPTの登場により、LLMという技術が一部の専門家だけのものではなく、一般の人々の生活や仕事を変える実用的なツールであることが広く認識されたのです。この社会的な認知度の向上が、ビジネス界におけるLLM導入の動きを一気に加速させる大きなきっかけとなりました。
法人向けAI研修
AX CAMP 無料資料
LLM・生成AI・ChatGPTの関係性と違い
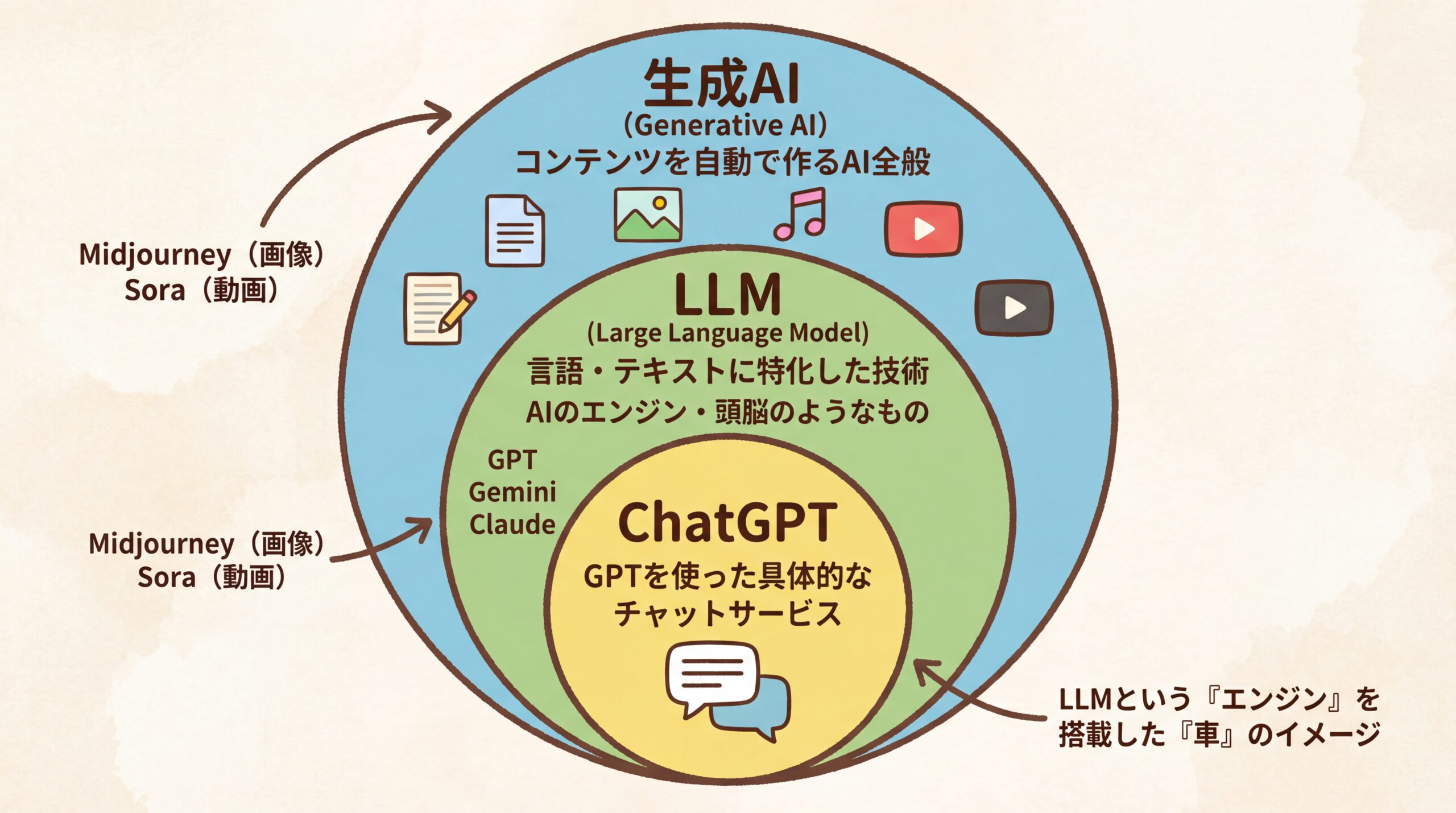
これらの言葉の関係性を理解する上で最も重要なのは、その階層構造です。結論から言うと、「生成AI」という最も広い概念の中に、言語に特化した技術である「LLM」が含まれ、そのLLMを応用した具体的なチャットサービスの一つが「ChatGPT」です。これらは包含関係にあり、それぞれが指し示す範囲が異なります。この構造を理解することで、各用語を正確に使い分けられるようになります。
生成AI:コンテンツを生成するAIの総称
生成AI(Generative AI)は、文章、画像、音楽、プログラムコードなど、新しいオリジナルのコンテンツを自ら「生成」する能力を持つAI技術全般を指す言葉です。LLMは、この生成AIの一種であり、特に「テキスト(言語)」の生成に特化したものを指します。画像生成AI(例: Midjourney)や動画生成AI(例: Sora 2)なども、すべて生成AIのカテゴリーに含まれます。つまり、生成AIはLLMよりも広い概念なのです。

LLM:生成AIの中でも「言語」に特化した中核技術
LLM(大規模言語モデル)は、前述の通り、テキストの生成、要約、翻訳、質問応答といった言語関連のタスクに特化した生成AIの中核技術です。OpenAIの「GPTシリーズ」やGoogleの「Geminiファミリー」などがこれにあたります。LLMはそれ自体がエンジンや頭脳のようなものであり、通常はAPIなどを通じて様々なアプリケーションに組み込まれて利用されます。そのため、LLMそのものは必ずしもチャット形式のインターフェースを持っているわけではありません。

ChatGPT:LLM(GPTシリーズ)を活用したチャットサービス
ChatGPTは、OpenAIが開発したLLMである「GPTシリーズ」を基盤として作られた、具体的なアプリケーション(チャットサービス)の名前です。ユーザーがチャット形式で質問や指示を入力すると、背後で動いているGPTモデルが応答を生成し、それをチャット形式で返す仕組みになっています。つまり、ChatGPTは「LLMというエンジン」を搭載した「チャット型の車」のような存在と考えると分かりやすいでしょう。同様に、Googleの「Gemini」やAnthropicの「Claude」も、それぞれが開発したLLMを搭載したチャットサービスです。
なぜこれらの言葉が混同されやすいのか?
これらの言葉が混同されやすい最大の理由は、ChatGPTがあまりにも有名になり、生成AIの代詞的な存在となったためです。多くの人が初めて生成AIに触れたのがChatGPTであったため、「生成AI = ChatGPT」という認識が広まりました。また、メディアがこれらの技術を報じる際に、厳密な定義よりも分かりやすさを優先して「ChatGPTのようなAI」といった表現を多用したことも、混同に拍車をかけたと分析できます。ビジネスの文脈で正確な議論をするためには、これらの階層関係を正しく理解しておくことが重要です。
LLMはどのようにテキストを生成する?基本的な仕組みを解説

LLMが人間のように自然な文章を生成する仕組みは、入力されたテキストを「トークン」という最小単位に分解し、膨大な学習データから得たパターンに基づいて、次に来る確率が最も高いトークンを予測し続けるというプロセスに基づいています。この一連の流れは、大きく4つのステップに分けられます。専門的な内容も含まれますが、概要を掴むことでLLMの能力と限界をより深く理解できるでしょう。
ステップ1:トークン化(単語や文字への分割)
まず、LLMは入力された文章を「トークン(Token)」と呼ばれる小さな単位に分割します。このプロセスが「トークン化(Tokenization)」です。トークンは、英語であれば単語やサブワード(”running”を”run”と”ning”に分けるなど)になることが多く、日本語の場合は単語や文字、あるいは形態素(意味を持つ最小単位)に分割されます。例えば、「LLMはテキストを生成する」という文章は、「LLM」「は」「テキスト」「を」「生成」「する」といったトークンに分けられます。これは、コンピュータが言語を処理するための最初の準備段階です。
https://media.a-x.inc/llm-token-count
ステップ2:エンべディング(単語のベクトル化)
次に、分割された各トークンは、「エンべディング(Embedding)」というプロセスを経て、数値の羅列である「ベクトル」に変換されます。コンピュータは単語そのものの意味を直接理解できないため、単語を多次元空間上の座標(ベクトル)として表現するのです。このとき、意味が近い単語同士は、ベクトル空間上で近くに配置されるようになっています。例えば、「犬」と「猫」は「車」よりも近い位置にマッピングされます。これにより、LLMは単語間の意味的な関係性を数値として捉えることが可能になります。

ステップ3:トランスフォーマーによる文脈学習
ベクトル化されたトークンは、LLMの中核であるトランスフォーマーに入力されます。トランスフォーマー内部では、「アテンション機構」が働き、入力された文章の中のどのトークンが他のトークンと強く関連しているかを計算します。例えば、「彼女は銀行の土手に座った」という文では、「銀行」が金融機関なのか川岸なのかを判断するために、「土手」という単語に強く注意(アテンション)を向けます。このプロセスを何層にもわたって繰り返すことで、LLMは複雑な文脈や単語の多義性を深く理解するのです。
ステップ4:デコーダーによる次単語予測と文章生成
最後に、文脈を理解した情報をもとに、デコーダー(Decoder)が次に来るべきトークンを確率的に予測します。例えば、「今日の東京の天気は」という入力に対し、学習データに基づき「晴れ」「曇り」「雨」といった候補の中から、最も確率が高いトークン(例えば「晴れ」)を選択します。そして、生成された「晴れ」を含めた「今日の東京の天気は晴れ」という文章を新たな入力として、さらに次のトークンを予測します。この一連の予測プロセスを繰り返し、文章の終わりを示す特殊なトークンが出現するまで続けることで、一つのまとまった文章が生成されるのです。
法人向けAI研修
AX CAMP 無料資料
【最新】代表的なLLM(大規模言語モデル)7選

LLMの開発競争は世界的に激化しており、OpenAI、Google、Anthropicの3社が業界をリードする形で、それぞれ特徴の異なる高性能なモデルを発表しています。これらに加えて、Meta社が提供するオープンソースモデルや、xAI、さらには日本国内の企業による日本語特化型モデルなど、多様な選択肢が登場しています。ここでは、現時点で注目すべき代表的なLLMを紹介します。
| モデルシリーズ | 開発元 | 最新モデル例 | 特徴 |
|---|---|---|---|
| GPTシリーズ | OpenAI | GPT-5など | 業界最高水準の汎用性と論理的推論能力。APIも豊富。 |
| Geminiファミリー | Gemini 2.5 Proなど | マルチモーダル性能に優れ、Googleサービスとの連携が強力。 | |
| Claudeファミリー | Anthropic | Claude Sonnet 4.5など | 安全性と倫理性を重視した設計。長文の読解・生成に強い。 |
| Llamaシリーズ | Meta | Llama 3 | オープンソースで提供され、カスタマイズ性が高い。 |
| Grok | xAI | Grok-1.5 | リアルタイム情報へのアクセスと、ユーモアを交えた回答が特徴。 |
| 日本語特化型モデル | ELYZA, Stability AI Japanなど | Llama-3-ELYZA-JP-8Bなど | 日本の文化や商習慣に合わせた自然な日本語生成に特化。 |
| オープンソースモデル | Mistral AIなど | Mistral Large | コストパフォーマンスに優れ、特定のタスクで高い性能を発揮。 |
1. GPTシリーズ (OpenAI)
ChatGPTで知られるOpenAIが開発するLLMで、業界のベンチマーク的存在です。最新のGPTモデルは、推論能力やマルチモーダル性能が向上し、極めて高い汎用性を誇ります。豊富なAPIが提供されており、多くのアプリケーションの基盤技術として採用されています。
2. Geminiファミリー (Google)
Googleが開発するLLMで、テキスト、画像、音声などを統合的に扱うマルチモーダル性能を強みとしています。最新世代のGeminiモデルは、Google検索やGoogle Workspaceとのシームレスな連携が特徴で、最新情報に基づいた回答や、よりパーソナライズされたタスクの実行を得意とします。

3. Claudeファミリー (Anthropic)
元OpenAIのメンバーが設立したAnthropic社が開発。安全性と倫理性を重視した「憲法AI」というアプローチで設計されているのが最大の特徴です。最新のClaudeモデルは、特に長文のドキュメント読解や要約、誠実な対話生成に優れており、ビジネス文書の扱いや顧客対応などで高い評価を得ています。
4. Llamaシリーズ (Meta)
Meta社(旧Facebook)が開発し、オープンソースとして提供されているLLMです。研究者や開発者が自由にモデルを改変・利用できるため、世界中のコミュニティによって急速に発展しています。コストを抑えつつ、自社のニーズに合わせて柔軟にカスタマイズしたい場合に有力な選択肢となります。
5. Grok (xAI)
イーロン・マスク氏が率いるxAI社が開発したLLMです。ソーシャルメディアプラットフォーム「X」(旧Twitter)のデータにリアルタイムでアクセスできる点が大きな特徴で、非常に新しい情報に関する質問にも回答できます。また、少しひねりの効いた、ユーモアのある回答を生成する傾向があります。
6. 日本語特化型モデル (ELYZA, Stability AI Japanなど)
海外製のLLMは日本語にも対応していますが、日本の文化や社会常識、微妙なニュアンスの理解には課題が残る場合があります。これに対し、ELYZAやStability AI Japanなどの日本企業は、日本語のデータセットを中心に学習させたモデルを開発しています。 国内のビジネス文書作成や顧客対応など、より自然で高品質な日本語が求められる場面で強みを発揮します。

7. オープンソースモデルの動向 (Mistral AIなど)
Meta以外にも、フランスのMistral AIなど、高性能なオープンソースLLMを開発するスタートアップが次々と登場しています。これらのモデルは、特定のタスクにおいては商用モデルに匹敵、あるいは凌駕する性能を示しながらも、低コストで利用できる場合があります。オープンソースコミュニティの活発な動きは、LLM市場全体のイノベーションを促進する重要な要素となっています。
https://media.a-x.inc/llm-open-source
法人向けAI研修
AX CAMP 無料資料
【分野別】LLMのビジネス活用事例8選
LLMは、特定の業界に限らず、企業のあらゆる部門で業務効率化、コスト削減、そして新たな顧客体験の創出に貢献するポテンシャルを秘めています。ここでは、具体的なビジネスシーンにおけるLLMの活用事例を8つの分野に分けて紹介します。自社のどの業務に応用できそうか、イメージしながらご覧ください。
https://media.a-x.inc/llm-use-cases
1. カスタマーサポート:問い合わせ自動応答とオペレーター支援
LLMを活用したチャットボットは、顧客からの定型的な問い合わせに24時間365日自動で応答できます。これにより、オペレーターはより複雑で個別対応が必要な問題に集中できるようになります。また、オペレーターが顧客と対話している最中に、関連する社内マニュアルや過去の対応履歴をLLMがリアルタイムで検索・提示し、回答作成を支援することも可能です。
エムスタイルジャパン様の事例
美容健康食品の製造販売を行うエムスタイルジャパン様では、コールセンターでの顧客情報の履歴確認に時間がかかるという課題がありました。AX CAMPの研修を通じて特定の業務から自動化に着手した結果、これまで月16時間かかっていた確認業務がほぼ0時間になり、その成功モデルを他部署へ展開することで、全社で月100時間以上の業務削減に成功しています。(出典:月100時間以上の”ムダ業務”をカット!エムスタイルジャパン社が築いた「AIは当たり前文化」の軌跡)
2. マーケティング:広告文、SNS投稿、ブログ記事の自動生成
ターゲット顧客のペルソナや製品の特長、伝えたいメッセージなどを指示するだけで、LLMは魅力的な広告コピー、SNSの投稿文、ブログ記事の草案などを複数パターン瞬時に生成します。これにより、マーケティング担当者はコンテンツ制作にかかる時間を大幅に短縮し、戦略立案や効果分析といった、より創造的な業務に時間を使えるようになります。(出典:Route66様 導入事例)
Route66様の事例
マーケティング支援を手掛けるRoute66様は、クライアント向けコンテンツの原稿執筆に多くの時間を要していました。AX CAMPの研修でAIライティングツールを導入したところ、1本あたり24時間かかっていた原稿執筆の初稿作成がわずか10秒で完了するなど、圧倒的な生産性向上を実現しました。(出典:AX CAMP受講企業の成果事例)

3. 営業:メール文面のパーソナライズと商談議事録の要約
顧客情報や過去のやり取りを基に、各顧客に最適化されたパーソナルな営業メールの文面をLLMが自動で作成します。これにより、開封率や反応率の向上が期待できます。また、商談の音声を録音しておけば、LLMが自動で文字起こしを行い、決定事項や次のアクションアイテムをまとめた議事録を作成してくれるため、営業担当者の報告業務の負担を大幅に軽減します。

4. ソフトウェア開発:コード生成、デバッグ、仕様書作成の補助
「こういう機能を持つプログラムを作りたい」といった自然言語での指示に基づき、LLMがPythonやJavaScriptなどのプログラムコードを生成します。簡単なツールであれば、専門家でなくても開発が可能です。また、既存のコードに含まれるエラー(バグ)の原因を特定したり、コードの機能を解説するドキュメント(仕様書)を自動で作成したりと、開発プロセスのあらゆる場面でエンジニアをサポートします。
https://media.a-x.inc/llm-coding
5. 人事・採用:求人票作成と応募書類の一次スクリーニング
募集する職種の要件を伝えるだけで、候補者にとって魅力的で分かりやすい求人票の文章をLLMが作成します。さらに、多数の応募者から送られてくる履歴書や職務経歴書の内容をLLMが読み込み、募集要件との合致度を自動で評価・点数化することも可能です。これにより、採用担当者は有望な候補者の選定に集中できます。
WISDOM合同会社様の事例
SNS広告などを手掛けるWISDOM合同会社様では、事業拡大に伴う人材採用コストと業務負荷が課題でした。AX CAMPでAI活用スキルを習得し、SNS投稿文の作成やレポート集計といった業務を自動化した結果、新たに2名を採用した場合と同等の業務量をAIが代替することに成功し、採用コストをかけずに生産性を向上させました。(出典:採用予定2名分の業務をAIが代替!WISDOM社、毎日2時間の調整業務を自動化)
6. 教育・研修:個別最適化された学習コンテンツの提供
受講者一人ひとりの理解度や学習進捗に合わせて、LLMが最適な練習問題を出題したり、分かりにくい部分を補足説明したりする、アダプティブ・ラーニング(適応学習)システムを構築できます。これにより、画一的な研修内容ではなく、各個人のレベルに合わせた効率的なスキルアップ支援が可能になります。

7. 研究開発:論文の要約と膨大な研究データの分析
研究者は日々多くの最新論文に目を通す必要がありますが、LLMを使えば、数十ページに及ぶ論文の要点を数分で正確に要約させることができます。また、実験データや市場調査データといった膨大な数値データをLLMに読み込ませ、その中から新たな傾向や相関関係を見つけ出すといったデータ分析の補助にも活用できます。

8. 社内業務:情報検索、ドキュメント作成、翻訳の効率化
社内規定や業務マニュアルなどの膨大なドキュメントをLLMに学習させておくことで、「〇〇の申請手続きについて教えて」といった自然言語での質問に対し、関連文書を探し出してきて要点をまとめて回答する、高機能な社内検索エンジンを構築できます。その他、会議資料の作成や海外とのメールのやり取りにおける翻訳など、日常的なオフィス業務の様々な場面でLLMは活躍します。
https://media.a-x.inc/ai-efficiency
法人向けAI研修
AX CAMP 無料資料
LLMをビジネスに導入する際の5つのポイント
LLMの導入を成功させるためには、技術的な側面だけでなく、戦略的な視点が不可欠です。結論として、「何のために導入するのか」という目的を明確にし、小さく始めて効果を検証しながら進めるアプローチが成功の鍵となります。やみくもにツールを導入するだけでは、期待した成果は得られません。ここでは、導入を成功に導くための5つの重要なポイントを解説します。
1. 導入目的と課題の明確化
まず最初に、「LLMを使って何を達成したいのか」「現在、社内のどの業務にどのような課題があるのか」を具体的に定義することが最も重要です。例えば、「カスタマーサポートの応答時間を平均30%短縮したい」「マーケティング部門のコンテンツ作成コストを月50万円削減したい」といったように、具体的な数値目標を設定することが望ましいです。目的が明確であればあるほど、導入すべきツールや評価の基準が定まり、プロジェクトが迷走するのを防げます。
2. スモールスタートと効果検証のサイクル構築
全社的に大規模な導入をいきなり目指すのではなく、まずは特定の部門や特定の業務に絞って試験的に導入する「スモールスタート」を推奨します。例えば、営業部の1チームだけで議事録作成の自動化を試す、といった形です。そして、導入前後で業務時間やコスト、成果物の品質がどう変化したかを定量的に測定し、効果を検証します。この「導入→検証→改善」のサイクルを高速で回すことで、リスクを最小限に抑えながら、自社に最適な活用法を見つけ出していくことができます。
3. API活用か独自モデル構築かの戦略的判断
LLMの導入方法には、大きく分けて2つのアプローチがあります。一つは、OpenAIなどが提供する既存のLLMをAPI経由で利用する方法。もう一つは、オープンソースモデルなどを基に、自社専用の独自モデルを構築(ファインチューニング)する方法です。API活用は迅速かつ低コストで導入できるメリットがありますが、カスタマイズ性には限界があります。独自モデル構築は、自社の業務に完全に最適化できる一方、高い専門知識とコスト、開発期間が必要です。自社の目的、予算、技術力を総合的に勘案し、どちらのアプローチが最適か戦略的に判断する必要があります。

4. プロンプトエンジニアリング人材の育成
LLMから期待通りの回答を引き出すためには、「プロンプト」と呼ばれる指示や質問の仕方が極めて重要になります。このプロンプトを工夫し、AIの性能を最大限に引き出す技術が「プロンプトエンジニアリング」です。どんなに高性能なLLMを導入しても、使いこなす側のスキルがなければ宝の持ち腐れになってしまいます。社内でプロンプトエンジニアリングに関する研修を実施したり、スキルを持つ人材を育成したりすることが、LLM活用の成果を大きく左右します。

5. UI/UX設計による付加価値の創出
LLMを単に導入するだけでなく、従業員が直感的でストレスなく使えるようなユーザーインターフェース(UI)やユーザー体験(UX)を設計することも重要です。例えば、複雑なプロンプトを入力しなくても、いくつかのボタンをクリックするだけで目的の文章が生成されるような社内ツールを開発すれば、ITに不慣れな従業員でもLLMの恩恵を受けられます。優れたUI/UXは、LLM活用の定着率を高め、生産性向上への貢献度を最大化します。
LLM導入前に知っておきたい注意点と対策
LLMは非常に強力なツールですが、その導入と運用にはいくつかのリスクも伴います。特に、LLMが生成するもっともらしい嘘の情報(ハルシネーション)と、機密情報の漏洩に繋がるセキュリティリスクは、すべての企業が対策すべき重要な課題です。これらのリスクを事前に理解し、適切な対策を講じることで、安全にLLMのメリットを享受できます。
ハルシネーション(もっともらしい嘘)への対策
ハルシネーションとは、LLMが事実に基づかない情報を、あたかも事実であるかのように生成してしまう現象です。LLMは学習データにあるパターンを基に次に来る単語を予測しているだけで、情報の真偽を判断しているわけではないため、この現象が起こります。対策としては、LLMが生成した情報は必ず人間がファクトチェック(事実確認)を行うプロセスを徹底することが基本です。重要な意思決定や顧客への正式な回答に利用する際は、必ず一次情報源と照らし合わせる社内ルールを設けましょう。

情報漏洩とセキュリティリスクの管理
無料版や一般消費者向けのチャットサービスに顧客情報や社内の機密情報を入力すると、その情報がサービス提供者に送信され、モデルの学習データとして利用されてしまう可能性があります。一方で、多くのベンダーが提供する法人向けのAPIプランやエンタープライズプランでは、入力データがモデルの学習に利用されないと規約で定められています。対策として、まず社内ガイドラインを策定し、機密情報を安易に入力しないよう周知徹底することが不可欠です。さらに、外部サービス利用時には事業者との契約内容を精査し、目的外利用の禁止、データ保持期間、秘密保持義務、安全管理措置などを書面で確認することが重要になります。

著作権や法的・倫理的な問題への配慮
LLMが生成した文章や画像が、既存の著作物と酷似してしまう可能性はゼロではありません。生成物を商用利用する際には、意図せず著作権を侵害してしまうリスクがないか、注意が必要です。具体的な対策として、生成物が既存の著作物と類似していないかチェックするツールの活用や、利用するLLMサービスの利用規約で商用利用の範囲を確認すること、必要に応じて専門家へ相談する体制を整えることが重要です。また、個人を誹謗中傷するようなコンテンツや、差別的な内容を生成しないよう、倫理的な利用ポリシーを定めておくべきです。

継続的な運用コストと専門人材の確保
高性能なLLMのAPIを利用する場合、処理するテキスト量に応じて継続的な利用料金(従量課金)が発生します。本格的に活用するとなると、そのコストは決して無視できません。また、自社で独自モデルを運用する場合は、サーバー費用やメンテナンス費用がかかります。導入前に、費用対効果を慎重に見積もることが重要です。さらに、LLMを効果的に活用し、発生したトラブルに対応するためには、AIに関する知識を持った専門人材が不可欠です。社内での人材育成や、必要に応じた外部専門家の活用も視野に入れる必要があります。
法人向けAI研修
AX CAMP 無料資料
LLMの今後の展望と将来性

LLMの進化はまだ始まったばかりであり、その将来性は計り知れません。今後の大きなトレンドとしては、テキストだけでなく画像や音声、動画などを統合的に扱う「マルチモーダル化」と、人間からの指示を自律的に解釈してタスクを実行する「AIエージェント化」が挙げられます。これらの技術革新は、ビジネスのあり方を根底から変えるほどのインパクトを持つと予測されています。
マルチモーダル化の進展(テキスト、画像、音声の統合)
現在のLLMは主にテキスト情報を扱いますが、将来的にはテキスト、画像、音声、動画といった異なる種類の情報(モダリティ)をシームレスに理解し、生成できるようになります。例えば、会議の動画を読み込ませるだけで、音声認識で議事録を作成し、ホワイトボードの画像を解析して図解を抽出し、それらをまとめた報告書をテキストで生成するといったことが可能になります。人間が五感で世界を認識するように、AIも複数の情報源から統合的に物事を理解できるようになるのです。GoogleのGeminiなどは、すでにこの方向性で高い能力を示しています。
AIエージェントによる自律的なタスク実行
AIエージェントとは、「来週の火曜日に大阪でクライアントと会食を設定して」といった曖昧な指示を与えるだけで、AIが自律的にタスクを分解し、必要なツール(カレンダー、予約サイト、地図アプリなど)を使いこなしながら目的を達成してくれる技術です。「クライアントの好みを検索→レストランを3つリストアップ→候補をメールで送信→返信を基に予約→カレンダーに登録→交通手段を検索して通知」といった一連の作業を、すべて自動で実行します。これにより、人間はより高レベルな意思決定に集中できるようになります。
特定業界・業務に特化した専門LLMの台頭
汎用的な超高性能LLMと並行して、特定の分野に特化した中小規模のLLMも数多く登場すると考えられます。例えば、金融業界の専門用語や規制に精通した「金融LLM」や、医療画像の解析と診断文の作成を得意とする「医療LLM」などです。これらの特化型LLMは、汎用モデルよりも少ない計算コストで、特定のタスクにおいて高い精度を発揮できるため、多くの企業にとって導入しやすく、費用対効果の高い選択肢となるでしょう。
思考ツリー(Tree of Thoughts)などの技術革新
LLMの性能をさらに引き出すための新しい技術開発も進んでいます。例えば、「思考ツリー(Tree of Thoughts: ToT)」に代表される手法は、LLMが複雑な問題を解く際に、思考プロセスをツリー構造のように分岐させ、複数の選択肢を評価しながら最適な答えを導き出すアプローチです。 このような基礎技術の革新が、LLMの推論能力や問題解決能力をさらに向上させ、これまでAIには困難とされてきた、より複雑で創造的なタスクへの応用を可能にしていくと期待されています。

LLMの活用ならAX CAMPにご相談ください

ここまでLLMの基本からビジネス活用法、将来性までを解説してきましたが、「理論は理解できたが、自社で実践するのは難しそうだ」と感じられた方もいらっしゃるかもしれません。特に、具体的な業務への落とし込みや、効果的なプロンプトの作成、リスク管理体制の構築には、専門的な知識とノウハウが求められます。
私たちAX CAMPは、法人向けのAI研修および伴走支援サービスを提供しており、LLMをはじめとするAI技術のビジネス活用を強力にサポートします。私たちの研修は、単なる知識のインプットに留まりません。貴社の実際の業務課題を題材にした実践的なワークショップを通じて、明日から現場で使える具体的なAI活用スキルを習得できるのが最大の特長です。経験豊富なコンサルタントが、貴社の状況に合わせた最適なLLMの選定から、導入計画の策定、社内ガイドラインの作成まで、一気通貫で支援します。
「何から手をつければ良いか分からない」「AI導入を任されたが、推進できるか不安だ」といったお悩みをお持ちの担当者様は、ぜひ一度お気軽にご相談ください。LLMをビジネスの強力な武器に変えるための、最短ルートをご提案します。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMとChatGPTの違いを理解しビジネスの可能性を広げよう
本記事では、LLM(大規模言語モデル)の仕組みからビジネス活用までを網羅的に解説しました。最後に、重要なポイントを改めて振り返ります。
- LLMとChatGPTの関係:LLMは文章を生成するAI技術そのものであり、ChatGPTはそのLLMを活用したチャットサービスの一つです。
- 多様なビジネス活用:LLMはカスタマーサポート、マーケティング、開発、人事など、企業のあらゆる部門で業務効率化に貢献します。
- 導入成功の鍵:成功のためには「目的の明確化」と「スモールスタート」が不可欠であり、プロンプト技術の習得も重要です。
- リスクへの備え:ハルシネーション(嘘の情報)や情報漏洩といったリスクを理解し、ファクトチェックや法人向けプランの検討、利用ガイドラインの策定などの対策が必要です。
LLMは、もはや一部の先進企業だけのものではありません。その基本的な仕組みと活用法、そしてリスクを正しく理解し、自社の課題解決に向けて一歩を踏み出すことが、これからの時代に競争力を維持していく上で不可欠と言えるでしょう。
AX CAMPでは、この記事で紹介したようなLLMの活用法を、貴社の実務に直結する形で学べる研修プログラムを提供しています。専門家の伴走支援を受けながら、自社の業務をAIで自動化・効率化するスキルを確実に身につけることができます。ご興味のある方は、ぜひ下記の資料請求や無料相談をご活用ください。

法人向けAI研修
AX CAMP 無料資料