

LLM(大規模言語モデル)の性能を飛躍的に向上させた
「アテンション(Attention)」機構。その仕組みについて、
「なんとなく知っているけれど、正確には説明できない」
「最新の動向まで把握したい」と感じている方も多いのではないでしょうか。文章の文脈を深く理解し、人間のように自然なテキストを生成する能力の裏側には、この革新的な技術が存在します。
この記事では、LLMの心臓部ともいえるアテンション機構の基本的な仕組みから、Self-AttentionやMulti-Head Attentionといった主要な種類、そして2026年時点での最新技術動向までを、図解を交えながら体系的に解説します。LLMがなぜこれほどまでに高性能なのか、その核心に迫ります。AI技術のビジネス活用や最新トレンドの把握に関心のある方は、ぜひご一読ください。
また、こうしたAIの専門的な技術をビジネスにどう活かすか、具体的な研修プログラムや導入支援にご興味のある方は、弊社の
「AX CAMP」サービス資料も併せてご覧ください。貴社の課題に合わせたAI活用法が見つかるかもしれません。

法人向けAI研修
AX CAMP 無料資料
LLMにおけるアテンション(Attention)とは?

LLMにおけるアテンション(Attention)とは、文章の中のどの単語に「注目」すべきかを動的に判断し、その重要度に応じて重み付けを変える仕組みです。この技術により、AIは文脈に応じた単語のニュアンスの違いを捉え、より精度の高い文章生成や翻訳ができるようになりました。まさに、LLMが人間のように自然な文章を操るための根幹をなす技術といえるでしょう。
例えば、「He went to the river bank.」と「He went to the bank to withdraw money.」という2つの文があったとします。人間は「river」や「money」といった周辺の単語から、それぞれの「bank」が「土手」と「銀行」という異なる意味を持つことを瞬時に理解します。アテンション機構は、AIにこの人間と同様の文脈判断能力を与え、文脈に応じた適切な単語の選択を可能にするのです。
文脈を読み解くための革新的な仕組み
アテンションが画期的な理由は、文章が長くなっても重要な情報の関連性を見失わない点にあります。従来のモデルでは難しかった、文中の離れた場所にある単語同士の関連性(長期依存関係)を効果的に捉えることができます。これにより、文章全体のテーマや文脈を一貫して保ったまま、自然で論理的なテキストを生成することが可能になりました。
この仕組みは、2017年に発表された画期的な論文『Attention Is All You Need』で紹介された「Transformer」モデルの中核技術として登場し、その後のLLM開発に絶大な影響を与えました。(出典:Attention Is All You Need) 現在主流となっているGPTシリーズやGeminiといった高性能LLMも、このTransformerアーキテクチャを基礎としています。
従来のRNN/LSTMの課題とTransformerにおける役割
アテンションが登場する以前、自然言語処理の分野ではRNN(再帰型ニューラルネットワーク)やその改良版であるLSTM(長短期記憶)が主流でした。これらのモデルは、単語を一つずつ順番に処理していく逐次的な仕組みを持っています。しかし、この仕組みには文章が長くなるにつれて、初期の入力情報が失われてしまうという根本的な課題がありました。
一方で、アテンションを全面的に採用したTransformerモデルは、文章内のすべての単語間の関連性を一度に計算します。これにより、単語の位置に関係なく、文脈を理解するために重要な単語へ直接アクセスできるようになりました。さらに、この構造はGPUによる並列計算との相性が非常に良く、モデルの学習時間を大幅に短縮させ、より巨大なデータセットで、より大規模なモデルを効率的に学習させることを可能にしたのです。

アテンションの基本的な考え方を比喩で理解する

アテンションの複雑な仕組みは、身近な例に例えることで直感的に理解できます。例えば、あなたが大勢の人が集まるパーティー会場で、友人の「田中さん」を探していると想像してみてください。あなたはおそらく、会場にいる全員を一人ひとり順番に確認するのではなく、無意識のうちに「田中さんらしい人」の特徴(髪型、服装、身長など)に注目し、効率的に探し出すはずです。
このとき、あなたの脳内で行われているのがアテンションに近い処理です。つまり、膨大な情報の中から、目的に関連する重要な情報に焦点を絞り、それ以外の情報の重要度を下げるというプロセスです。LLMのアテンション機構も同様に、文章という情報の集まりの中から、次に来る単語を予測したり、文章を翻訳したりする上で「どの単語が最も関連性が高いか」に注目しています。
別の例として、料理のレシピを考える場合も挙げられます。「カレーライス」という料理名を聞いたとき、あなたの頭の中では「カレールー」「じゃがいも」「にんじん」「玉ねぎ」「肉」といった材料が強く結びつきます。一方で、「醤油」や「味噌」といった他の調味料の重要度は低くなるでしょう。アテンションは、このように単語同士の関連性の強さを数値化し、文脈に合った適切な単語を選択するための重要な役割を担っているのです。(出典:Attention Is All You Need)
アテンション機構の3つの重要要素「Query・Key・Value」

アテンション機構の核心部分は、「Query(クエリ)」「Key(キー)」「Value(バリュー)」という3つの要素で構成されています。これらは、LLMが単語間の関連性を計算し、文脈に応じた出力を生成するための重要な役割を担っています。この3つの要素の関係性は、データベースから情報を検索するプロセスに例えると理解しやすいでしょう。
このQKVモデルによって、アテンションは入力された文章(シーケンス)内の各単語について、他のすべての単語との関連度を算出し、その関連度に基づいて情報を動的に集約できます。これが、文脈を深く理解する能力の源泉となっています。(出典:Attention Is All You Need)
Query・Key・Valueの役割
QKVの各要素は、それぞれ異なる役割を持っています。これらが連携することで、精度の高い文脈理解が実現されます。具体的には以下の通りです。
- Query (Q): 現在注目している単語。情報を「検索するためのクエリ」に相当します。例えば、「その猫は可愛い」という文で「その」という単語の文脈を理解したい場合、「その」がQueryになります。
- Key (K): 文中の各単語が持つ「情報の索引(インデックス)」です。Queryとの関連性を計算するために使われます。上記の例では、「その」「猫」「は」「可愛い」の各単語がそれぞれKeyを持ちます。
- Value (V): 文中の各単語が持つ「情報の中身」そのものです。Keyを介してQueryとの関連性が高いと判断された後、最終的な出力に反映される情報です。
結論として、Queryを使って全てのKeyとの関連度を調べ、その関連度に応じてValueを重み付けして足し合わせる、というのがアテンションの基本的な処理フローです。
QKVを用いた関連度スコアの計算フロー
アテンション機構がどのようにして文脈を捉えるのか、具体的な計算フローは大きく4つのステップに分けられます。
- Q, K, Vベクトルの生成: まず、入力された各単語のベクトル(単語埋め込み)から、それぞれ異なる重み行列を掛けることで、Query、Key、Valueという3種類のベクトルを生成します。
- 関連度スコアの計算: 次に、ある単語のQueryベクトルと、文中の他のすべての単語のKeyベクトルとの内積を計算します。この計算結果が、単語間の関連度の高さを示す「スコア」となります。
- 重みの正規化 (Softmax): 計算されたスコアをSoftmax関数に通すことで、合計が1になるような確率分布に変換します。これが「アテンション・ウェイト」と呼ばれるもので、各単語への「注目の度合い」を示します。
- Valueの加重平均: 最後に、算出されたアテンション・ウェイトを使って、すべての単語のValueベクトルを加重平均します。これにより、関連性の高い単語の情報がより強く反映された、文脈付きの新しいベクトルが生成されます。
この一連の処理を通じて、LLMは単語一つひとつに対して、文脈全体を考慮した豊かな表現を獲得することができるのです。
Transformerモデル全体におけるアテンションの役割
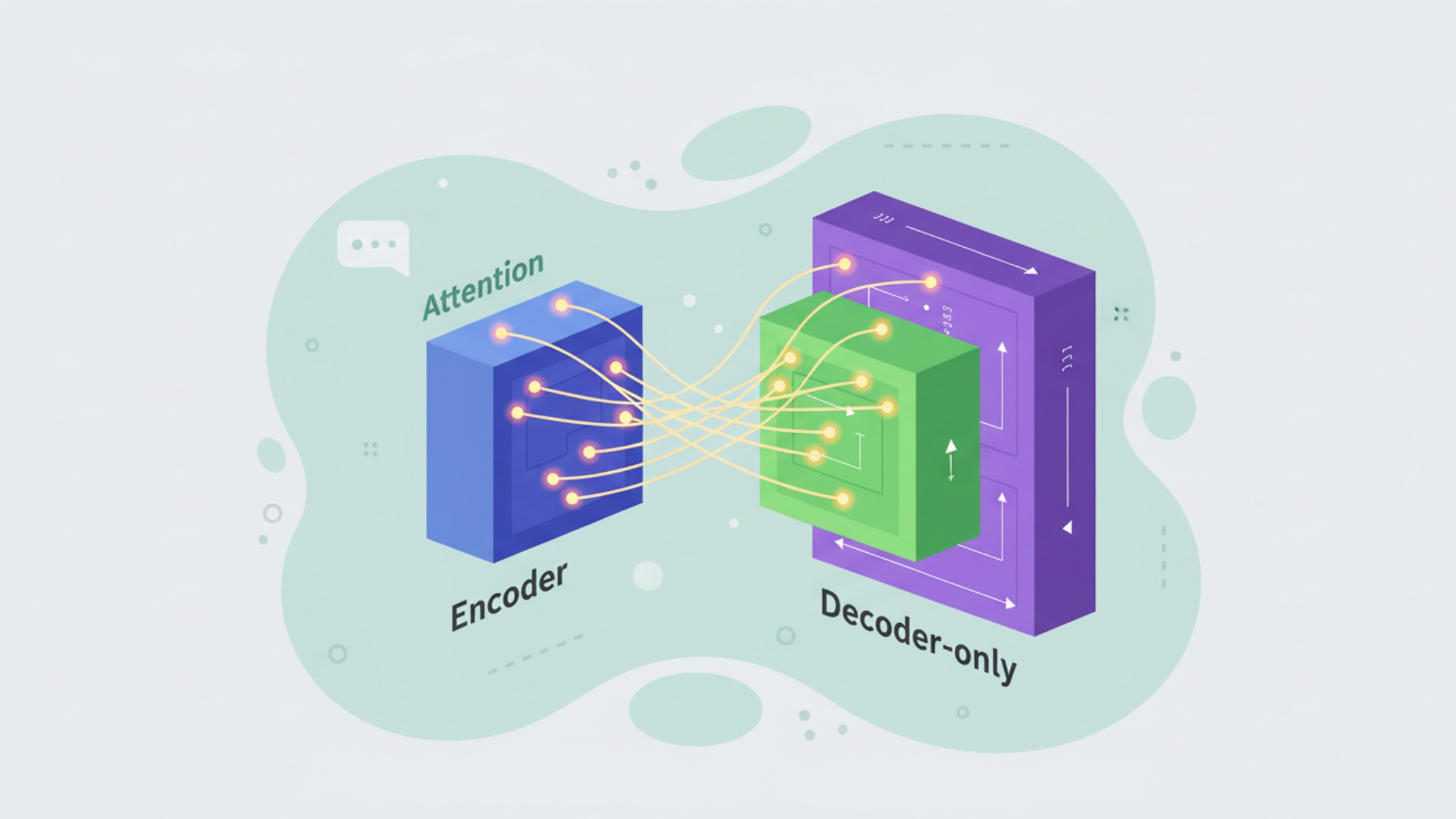
Transformerモデルの原型は、翻訳タスクなどを想定した「エンコーダー」と「デコーダー」という2つの部分から構成されています。しかし、GPTシリーズのような現代の多くの生成LLMは、主に「デコーダーのみ(Decoder-only)」のアーキテクチャを採用している点が重要です。アテンション機構は、これらの構造全体で中心的な役割を果たしています。
モデル内で使われる場所によってアテンションの種類や機能が異なり、それらが連携することで高度な自然言語処理が実現されています。例えば、エンコーダー・デコーダーモデルでは、入力文の文脈を理解するアテンション、出力文を生成する際に過去の生成内容を参照するアテンション、そして入力文を出力文に反映させるアテンションの3種類が連携します。
Transformerのアーキテクチャでは、これらのアテンション機構を含む層(ブロック)が何層にも積み重ねられています。下の層では単語レベルの直接的な関係性を捉え、層が深くなるにつれて、より抽象的で複雑な文脈や意味的な関係性を学習していきます。この階層的な構造が、LLMの深い言語理解能力の源となっているのです。
https://media.a-x.inc/llm-architecture代表的なアテンションの種類と仕組み

アテンション機構にはいくつかの種類がありますが、特にTransformerモデルで中心的に使用されるのが「Self-Attention」と、それを発展させた「Multi-Head Attention」です。これらの仕組みを理解することは、現代のLLMの動作原理を把握する上で欠かせません。
Self-Attentionが文章内の単語同士の関係性を捉える基本的なメカニズムであるのに対し、Multi-Head Attentionはそれを複数の異なる視点から同時に行うことで、より豊かで多角的な文脈理解を可能にします。この2つの技術が、Transformerモデルの性能を決定づける重要な要素となっています。
Self-Attention(自己注意機構)
Self-Attention(自己注意機構)は、1つの文章の中で、ある単語が他のどの単語と強く関連しているかを計算する仕組みです。この機構により、モデルは文法的な依存関係や意味的なつながりを捉えることができます。
例えば、「そのロボットは命令を実行したが、それは壊れていた」という文を考えてみましょう。この文の「それ」が何を指しているかを理解するためには、「ロボット」という単語に注目する必要があります。Self-Attentionは、文中のすべての単語ペアの関連度を計算することで、「それ」と「ロボット」のスコアが非常に高くなるように学習します。これにより、代名詞が指す対象を正しく特定するなど、文脈に依存した解釈ができるようになるのです。
この処理は、前述したQuery, Key, Valueのメカニズムを用いて行われます。入力された文章の各単語が、それぞれQ, K, Vの役割を同時に担い、自分自身を含む他のすべての単語との関連性を計算することから「自己」注意機構と呼ばれます。
Multi-Head Attention(マルチヘッドアテンション)
Multi-Head Attentionは、Self-Attentionの処理を複数(例えば8個や12個)並列で行う仕組みです。それぞれのSelf-Attentionの計算単位を「ヘッド」と呼びます。このアプローチにより、モデルは一度に多様な側面から文章の関連性を捉えることができます。
一つのヘッドが文法的な係り受け関係(例:「猫が」「走る」の主語述語関係)に注目している間に、別のヘッドは意味的な類似性(例:「王」と「女王」の関係)に注目する、といったように、各ヘッドが異なる種類の関係性を学習します。これを「複数の視点(マルチヘッド)」から文脈を分析する、と表現できます。
各ヘッドで計算された出力は、最終的に連結され、一つのベクトルに統合されます。これにより、単一のSelf-Attentionだけでは捉えきれなかった、よりリッチで複雑な文脈情報をモデルに与えることが可能になります。Transformerモデルの驚異的な性能は、このMulti-Head Attentionによって支えられていると言っても過言ではありません。(出典:Attention Is All You Need)

アテンションがLLMにもたらした3つの主要なメリット
アテンション機構の導入は、LLM(大規模言語モデル)の性能を飛躍的に向上させました。そのメリットは多岐にわたりますが、特に重要なのは「長期依存関係の克服」「計算の並列化による学習の高速化」「モデルの解釈可能性の向上」の3点です。(出典:Attention Is All You Need) これらのメリットが組み合わさることで、今日の高度なLLMが実現されています。
- 長期依存関係の克服: アテンションは、単語間の距離に関係なく直接的な関連度を計算できるため、文章中で遠く離れた単語間の関連性を効果的に捉えられます。
- 計算の並列化と高速化: 文中の全単語に対する計算を一度に行えるため、GPUの並列処理能力を最大限に活用でき、学習時間を劇的に短縮しました。
- 解釈可能性向上の手がかり: アテンションの重みを可視化することで、モデルが特定の出力を生成する際に、入力文のどの部分に注目したかを推測するヒントになります。
特に計算の並列化は、数十億から数兆パラメータにも及ぶ現代のLLMの学習を現実的なものにした、極めて重要な貢献です。ただし、アテンションの重みが必ずしも人間の直感や因果関係と一致するとは限らないため、解釈には注意が必要であることも指摘されています。
【2026年最新】アテンション機構の進化と派生技術

2017年にTransformerと共に登場したアテンション機構は、LLM発展の礎となりましたが、その計算コストの問題から、さらなる進化が求められてきました。特に、入力トークン数の二乗で計算量が増加する点は大きな課題でした。2025年現在、この課題を克服し、より長く、より効率的に文脈を扱えるようにするための様々な派生技術が登場しています。
これらの最新技術は、計算効率とメモリ使用量を劇的に改善し、数百万トークンといった超長文のコンテキストを処理する能力をLLMに与えつつあります。(出典:Qwen2.5: A Bridge to General Artificial Intelligence)ここでは、その中でも特に注目されている「効率化技術」と「Mixture of Experts (MoE)との組み合わせ」について解説します。
計算・メモリ効率を改善する技術(スパースアテンション, FlashAttention)
標準的なアテンション機構は、すべての単語ペアの関連性を計算するため、非常に計算コストが高いという欠点があります。この問題を解決するために、計算を一部に限定する「スパースアテンション」という考え方が生まれました。
さらに、近年では「FlashAttention」という技術が大きな注目を集めています。FlashAttentionは、アテンションの計算方法そのものを変えるのではなく、GPUのメモリ階層を効率的に使うことで、メモリアクセスのボトルネックを解消し、計算を大幅に高速化するアルゴリズムです。具体的には、計算途中の巨大なアテンション行列を低速なメインメモリに書き出すことなく、高速なSRAM上で処理を完結させることで、特定の条件下ではメモリ使用量を削減し、2〜4倍の高速化を実現します。(出典:FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning)
Mixture of Experts (MoE)との組み合わせ
もう一つの重要なトレンドが、「Mixture of Experts(MoE)」アーキテクチャとアテンションの組み合わせです。MoEは、モデル内部に複数の専門家(Expert)と呼ばれる小さなニューラルネットワークを持ち、入力に応じて最適な専門家を動的に切り替えて処理を行う仕組みです。
このMoEをTransformerのフィードフォワード層に適用することで、モデル全体のパラメータ数を大幅に増やしながらも、推論時に実際に計算を行う部分(アクティブなパラメータ)を少数に抑えることができます。例えば、8人の専門家がいて、各入力トークンに対して最も関連性の高い2人だけが働く、といったイメージです。
このアプローチにより、一部の最新高性能モデルは、推論コストを抑えつつ、モデルの知識容量と性能を飛躍的に向上させています。ただし、MoEには利点だけでなく、専門家への処理の割り振り(ルーティング)や学習の不安定さといったトレードオフも存在するため、その設計と運用には高度な技術が求められます。アテンションが文脈理解の質を高め、MoEがモデルの巨大化と効率化を両立させる、という強力な組み合わせが2025年現在のLLMアーキテクチャの主要な選択肢の一つとなっています。
https://media.a-x.inc/llm-architectureLLMのアテンションにおける課題と今後の展望

LLMの進化を牽引してきたアテンション機構ですが、いくつかの課題も残されています。最大の課題は、依然として残る計算コストの問題です。FlashAttentionのような技術で効率化は進んでいるものの、入力長の二乗で計算量が増えるという基本的な性質は変わっていません。そのため、極めて長いコンテキストを扱う際には、依然として膨大な計算資源が必要となります。
一部の最新研究や商用モデルで数百万トークン級の処理が報告されていますが、実運用においてはコスト、速度、そして長文における精度維持のトレードオフが存在するのが現状です。また、アテンションは文中のあらゆる単語ペアの関係性を計算しますが、その冗長性をいかに削減するかは、今後の重要な研究テーマです。線形時間で動作する新しいアテンションの亜種や、アテンションを全く使わない新しいアーキテクチャ(State Space Modelなど)の研究も活発に進められています。
今後の展望としては、さらに効率的で、より長い文脈を扱え、かつ特定のタスクに特化したアテンション機構の開発が期待されます。例えば、動画や音声といったマルチモーダルなデータを扱う際には、時間的な連続性や空間的な関係性をより効果的に捉えるための新しいアテンションの形が求められるでしょう。アテンション機構の進化は、LLMの能力の限界を押し広げ、私たちがAIと対話する方法をさらに変革していく可能性を秘めています。

LLMやアテンションのビジネス活用ならAX CAMPへ

LLMやアテンション機構といったAIの根幹技術を理解することは、その可能性を最大限に引き出すための第一歩です。しかし、これらの専門的な知識を実際のビジネス課題の解決に結びつけるには、さらなるノウハウと実践的なスキルが求められます。「自社の業務にどう応用できるのか」「何から手をつければ良いのかわからない」といったお悩みをお持ちの企業も少なくありません。
私たちAX CAMPでは、AI技術の基礎から実務での応用までを体系的に学べる法人向け研修プログラムを提供しています。経験豊富な専門家が、貴社のビジネスモデルや業務内容を深く理解した上で、最適なAI活用のシナリオを共に描き、その実現を伴走支援します。単なる知識の提供に留まらず、現場で実際に成果を出せる人材の育成をゴールとしています。(出典:RAGとは?その仕組みやメリット、代表的な手法を解説)
AX CAMPの研修は、明日から使える具体的な成果を重視しています。例えば、当社の研修を導入した企業様では、以下のような業務改善を実現しました。
- 原稿執筆時間の大幅短縮: 1,500字程度のブログ原稿1本あたりの執筆時間を、従来の24時間から10秒へ短縮(Route66株式会社様)
- SNS運用の効率化と成果向上: 担当者の作業時間を3時間から1時間へ削減(66%削減)しつつ、月間1,000万インプレッションを達成(C社様)
AIの力を自社の競争力に変えたいとお考えの担当者様は、ぜひ一度、AX CAMPのサービス資料をご覧ください。無料相談も受け付けておりますので、お気軽にお問い合わせください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMのアテンションの仕組みと重要性を再確認
本記事では、LLMの性能を支える中核技術であるアテンション(Attention)機構について、その基本的な仕組みから最新の技術動向までを解説しました。最後に、重要なポイントを改めて振り返ります。
- アテンションとは: 文章内の単語の重要度を文脈に応じて動的に判断する仕組み。
- 主要な構成要素: Query, Key, Value (QKV) を用いて単語間の関連度を計算する。
- 代表的な種類: 文章内の関係性を捉えるSelf-Attentionと、それを多角的に行うMulti-Head AttentionがTransformerの中核をなす。
- もたらしたメリット: 長期依存関係の克服、計算の並列化による学習高速化、モデルの解釈性向上の手がかりを提供した。
- 2026年の最新動向: FlashAttentionによる効率化や、Mixture of Experts (MoE)との組み合わせにより、超長文対応とモデルの巨大化・効率化を両立させる動きが進んでいる。
アテンション機構は、LLMが単なるパターン認識を超え、人間のように文脈を深く理解するための鍵となる技術です。この仕組みを理解することは、AIの能力と限界を正しく把握し、ビジネスにおける有効な活用策を考える上で不可欠と言えるでしょう。
AX CAMPでは、こうしたAIの核心技術をビジネスの現場で使いこなし、具体的な成果へと繋げるための実践的な研修を提供しています。専門家の伴走支援のもと、AI導入プロジェクトを確実に成功させたい、あるいは社内にAI活用を推進できる人材を育成したいとお考えでしたら、ぜひ弊社のサービスをご検討ください。貴社のAI活用とDX推進を強力にサポートします。

法人向けAI研修
AX CAMP 無料資料