

自社に蓄積されたデータや専門知識を活用し、汎用的な大規模言語モデル(LLM)を特定の業務に最適化したいと考えていませんか。
その強力な手法が「ファインチューニング」です。しかし、その仕組みやメリット、他の技術との違いを正確に理解している担当者はまだ多くありません。
この記事では、LLMのファインチューニングについて、その基本からメリット・デメリット、具体的な手順、そして混同されがちなRAG(検索拡張生成)との違いまでを分かりやすく解説します。
最後まで読めば、自社の目的に合わせてLLMをカスタマイズし、独自の高精度なAIを開発するための具体的な道筋が見えるはずです。AI活用の成果を最大化するための第一歩として、ぜひご一読ください。
記事:【AI導入しないことが経営リスクになる時代】先行企業が手にした圧倒的な競争優位とは?
LLMファインチューニングとは?
LLMファインチューニングとは、既存の学習済み大規模言語モデル(LLM)に対し、特定のタスクや専門分野に特化した追加の学習を行う技術のことです。 このプロセスを経ることで、モデルは汎用的な知識に加え、特定の要求に応えるための専門的な能力を獲得します。
料理に例えるなら、市販の万能だし(ベースモデル)に、煮物なら醤油やみりん、お吸い物なら塩や昆布だしを加えて(ファインチューニング)、それぞれの料理に最適な味へ仕上げるイメージです。この一手間によって、あらゆる応答の質を根本から引き上げることが可能になります。
LLMを特定タスクに特化させる技術
ファインチューニングの核心は、LLMを「万能なアシスタント」から「特定の業務のプロフェッショナル」へと進化させる点にあります。一般的なLLMは幅広い知識を持っていますが、特定の業界用語や社内独自の言い回し、特殊な応答形式には対応しきれない場合があります。
そこで、自社が求める応答形式や文体のサンプルデータを学習させることで、モデルの振る舞いを調整します。例えば、以下のようなタスクに特化させられます。
- 顧客サポート用の丁寧な言葉遣い
- マーケティング用の魅力的なキャッチコピー生成
- 法務文書のような厳格なフォーマットでの文章作成
このように、特定の用途に合わせてモデルの応答スタイルを最適化するのが、ファインチューニングの主な目的と言えるでしょう。
ベースモデルとファインチューニングモデルの関係
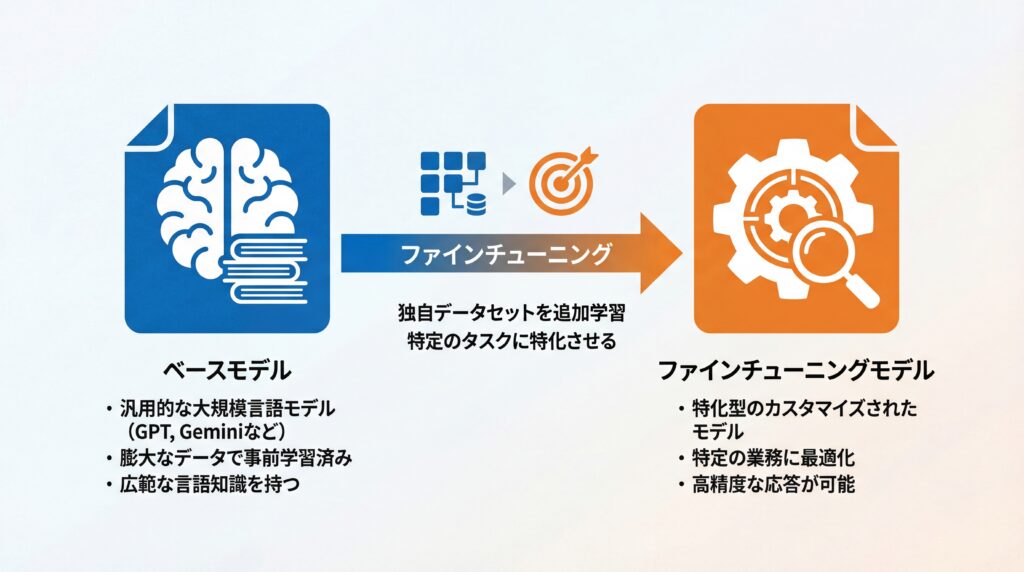
ファインチューニングは、ゼロからモデルを作るのではなく、「ベースモデル」と呼ばれる既存のLLMを土台にします。例えば、OpenAI社のGPTシリーズやGoogle社のGeminiシリーズなどがベースモデルの代表例です。これらのモデルは、インターネット上の膨大なテキストデータによって事前学習されており、言語に関する広範な知識や能力を持っています。
ファインチューニングは、このベースモデルが持つ能力を活かしつつ、新たなデータセットで追加学習を行います。適切な手法(PEFTなど)を用いれば、汎用性を大きく損なうことなく、特定のドメインへの専門性を上乗せした「ファインチューニングモデル」が完成します。ただし、手法を誤ると既存の能力が低下する「破滅的忘却」のリスクもあるため、技術選定は慎重に行う必要があります。(出典:A Comprehensive Study on Catastrophic Forgetting in Fine-tuning Large Language Models)
この関係性により、膨大な計算コストや時間が必要な事前学習を自社で行う必要がなく、比較的少ないデータとコストで高性能な独自モデルを開発できるのです。
2025年における最新の技術トレンド
2025年現在、LLMのファインチューニング技術は、より効率的かつ低コストで実行できる方向へと進化しています。かつてはモデルの全パラメータを更新する「フルファインチューニング」が主流でしたが、莫大な計算リソースが必要でした。
しかし近年では、PEFT(Parameter-Efficient Fine-Tuning)と呼ばれる、モデル内の一部のパラメータのみを調整する手法が注目されています。(出典:Parameter-Efficient Fine-Tuning (PEFT)) 代表的な手法には「LoRA(Low-Rank Adaptation)」があり、これにより計算コストを大幅に削減しつつ、高い性能を維持できるようになりました。
この技術的進歩により、以前は大手企業でなければ難しかったファインチューニングが、より多くの企業にとって現実的な選択肢となりつつあります。今後も、さらに少ないデータとコストで高い効果を得られる手法の登場が期待されます。


ファインチューニングのメリット・デメリット
ファインチューニングは、モデルの性能を特定の方向に大きく向上させる強力な手法ですが、その一方でコストや専門性といった課題も存在します。導入を検討する際は、これらの両側面を正確に理解し、自社の目的やリソースと照らし合わせることが不可欠です。
ここでは、ファインチューニングがもたらす主要なメリットと、事前に考慮すべきデメリットを具体的に解説します。
メリット:モデル性能の向上と特定ドメインへの適応
ファインチューニングの最大のメリットは、自社のニーズに合わせてLLMの性能を飛躍的に高められる点です。(出典:A Comprehensive Study on Catastrophic Forgetting in Fine-tuning Large Language Models) 具体的には、以下のような利点があります。
- 特定タスクでの高精度化
- 専門用語や文脈の理解
- 応答スタイルの統一
- プロンプトの簡略化
例えば、医療分野の論文要約タスクにおいて、専門用語を含むデータでファインチューニングを行うことで、汎用モデルよりも正確な要約生成を支援できます。ただし、生成物はあくまで参考情報であり、診断や治療の代替ではなく、最終的な判断は必ず専門家が行うという前提が重要です。
デメリット:高いコストと専門知識の必要性
多くのメリットがある一方で、ファインチューニングには無視できないデメリットも存在します。導入の障壁となりうる主な課題は以下の通りです。
- 高品質なデータセットの準備
- 高い計算コスト
- 専門的な技術知識
- 過学習のリスク
特に、最も重要なのが「高品質なデータセットの準備」です。 モデルに学習させる数千件規模の「指示」と「理想的な応答」のペアデータを自社で用意する必要があり、これには多大な時間と労力がかかります。また、学習プロセスには高性能なGPUが必要となり、クラウドサービスを利用する場合でも相応の費用が発生します。適切なチューニングを行うには、機械学習に関する深い専門知識も求められます。(出典:Fine-tuning generative AI models for healthcare)


法人向けAI研修
AX CAMP 無料資料
他のLLMカスタマイズ手法との違い
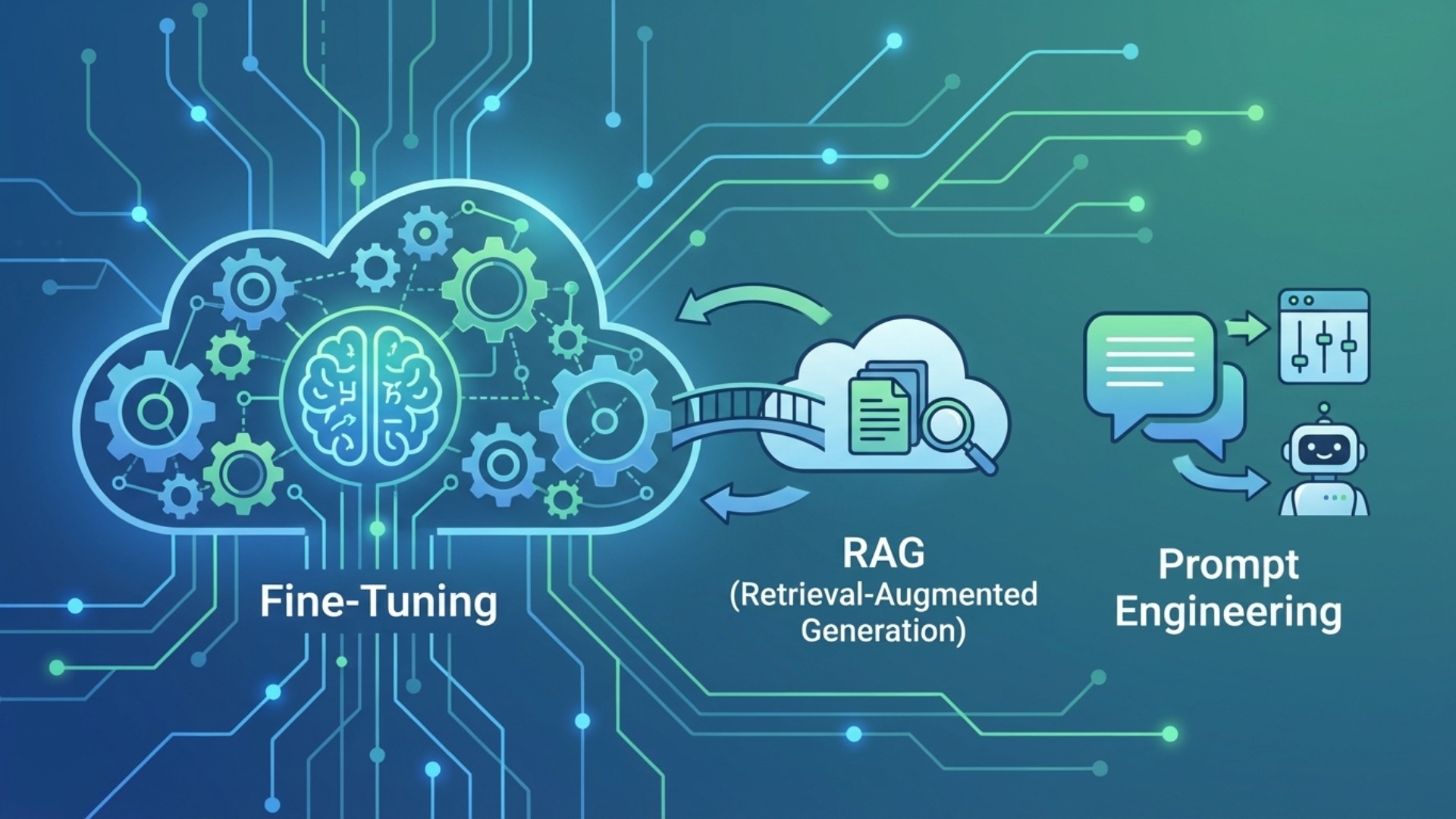
LLMを自社の業務に最適化する手法は、ファインチューニングだけではありません。代表的な手法として「RAG(検索拡張生成)」や「プロンプトエンジニアリング」があり、目的やコストに応じてこれらを使い分けることが重要です。各手法の特性を理解し、最適なアプローチを選択しましょう。
ここでは、それぞれの技術が持つ特徴と、ファインチューニングとの具体的な違いを比較・解説します。
RAG(検索拡張生成)との使い分け
RAGとファインチューニングは、しばしば混同されますが、その目的は根本的に異なります。(出典:ファインチューニングとは?RAGとの違いやメリット・デメリット、代表的な手法を解説) ファインチューニングがモデルの「振る舞い」や「応答スタイル」を学習させるのに対し、RAGは外部知識の検索と統合を通じて、モデルの回答に最新情報や特定データを組み込む手法です。
例えば、「今日の社内報の内容を要約して」というタスクを考えます。この場合、モデルは今日の社内報という「知識」を知らないため、ファインチューニングでは対応できません。RAGを用いて社内報のデータベースにアクセスさせ、その情報を基に回答を生成するのが適切なアプローチです。
一方で、「顧客からの問い合わせに、当社の規定フォーマットと丁寧な言葉遣いで回答して」というタスクは、モデルの「振る舞い」を調整する問題なので、ファインチューニングが適しています。 以下の表に、両者の使い分けをまとめます。
| 項目 | ファインチューニング | RAG(検索拡張生成) |
|---|---|---|
| 目的 | モデルの応答スタイル・振る舞いの学習 | 外部知識・最新情報の参照 |
| 得意なこと | 文体・口調の統一、出力形式の制御 | 社内文書や最新ニュースに基づく回答 |
| 知識の更新 | 再学習が必要 | データベースの更新のみで対応可能 |
| 導入コスト | 高(データ準備・学習コスト) | 中(データベース構築・検索システム) |
プロンプトエンジニアリングとの比較
プロンプトエンジニアリングは、LLMへの指示(プロンプト)を工夫することで、望んだ出力を引き出す技術です。これは、モデル自体には一切手を加えず、対話の方法を変えるだけなので、最も手軽で即時性のあるカスタマイズ手法と言えます。
しかし、複雑な要求を伝えようとするとプロンプトが非常に長くなりがちで、毎回同じ指示を繰り返す手間が発生します。また、指示の仕方によって出力の質が安定しないこともあります。
これに対し、ファインチューニングはモデル自体を特定のタスクが得意な状態に作り変えるアプローチです。一度学習させてしまえば、毎回長いプロンプトを与えなくても、短い指示で安定して高品質な出力を得られるようになります。初期コストは高いですが、長期的に繰り返し利用するタスクにおいては、運用効率で大きく上回ります。


ファインチューニングでできること・できないこと
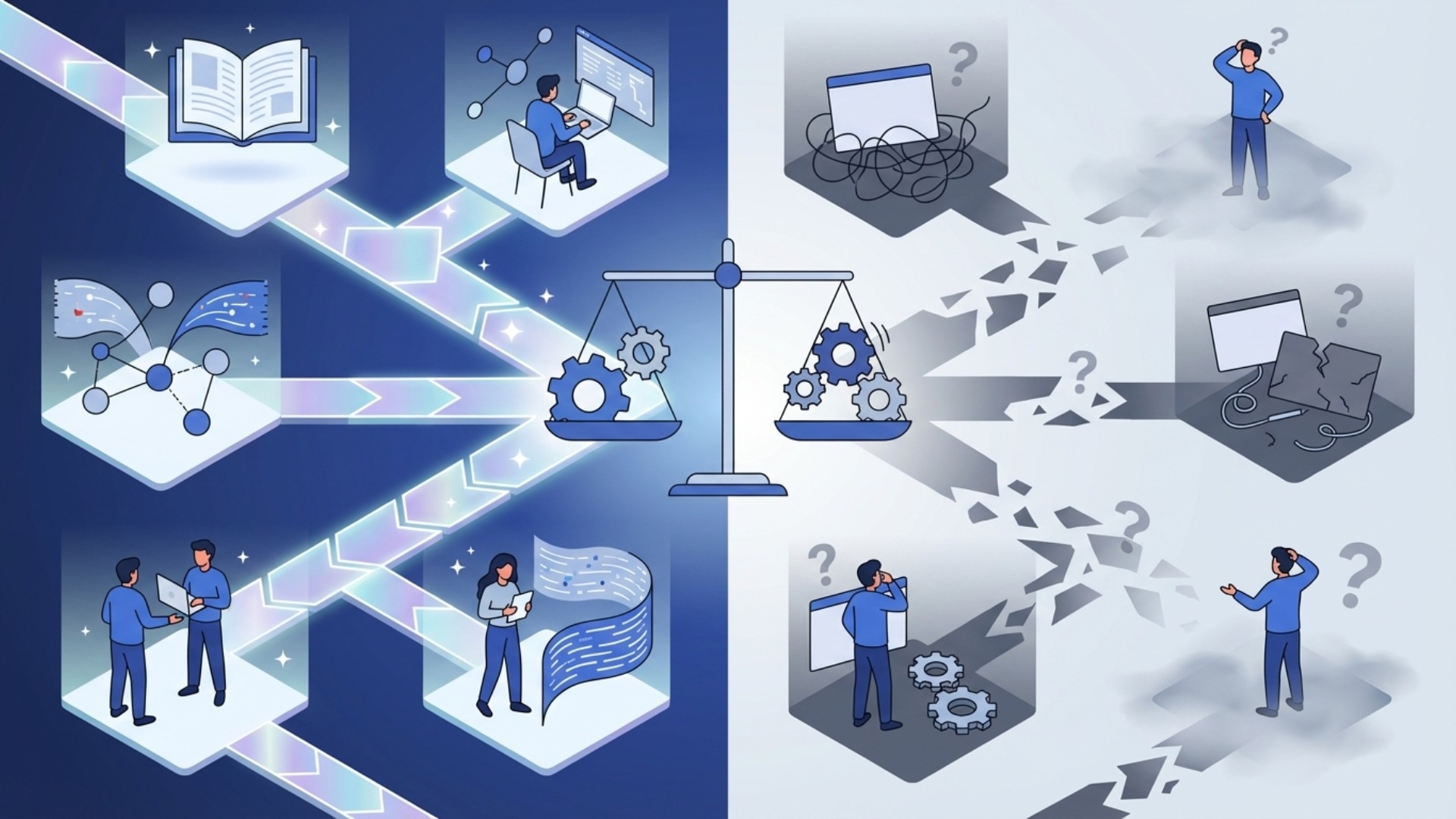
ファインチューニングは万能の技術ではなく、得意なことと苦手なことが明確に分かれています。その能力の限界を正しく理解することは、期待外れの結果を避け、プロジェクトを成功に導くために極めて重要です。モデルの「振る舞い」を教えるのが得意で、新たな「知識」を教えるのは苦手、と覚えておくと良いでしょう。
ここでは、ファインチューニングが真価を発揮するタスクと、原理的に対応が難しいタスクを具体的に解説します。
得意なタスク:文体・口調の統一、出力形式の制御
ファインチューニングは、LLMの出力の「スタイル」を調整するタスクで非常に高い効果を発揮します。 これは、モデルが持つ広範な言語知識をベースに、特定の応答パターンを学習するためです。主に以下のような用途で活用されます。
- 文体・口調の統一
- 特定の出力形式の遵守
- 専門用語への適応
- タスク特化の精度向上
例えば、企業のチャットボットが常に特定のキャラクターの口調で話すようにしたり、JSON形式で必ず応答を返すように制御したりできます。また、特定のプログラミング言語のコーディングスタイルを学習させ、自社の規約に沿ったコードを生成させることも可能です。繰り返し発生する定型的なタスクの品質を安定させ、効率化する上で大きな力を発揮します。
苦手なタスク:新たな知識の学習、幻覚(ハルシネーション)の抑制
一方で、ファインチューニングには限界もあります。特に、モデルが元々持っていない全く新しい知識を教え込むことは非常に困難です。 これは、ファインチューニングが既存の知識の「使い方」を調整するプロセスであり、「知識」そのものを注入するプロセスではないためです。
- 新たな知識の注入
- 事実誤認(ハルシネーション)の完全な抑制
- 倫理観や安全性の抜本的変更
技術的にはファインチューニングで新事実をモデルに組み込めますが、頻繁に更新される情報や即時性が求められる情報は RAG(検索拡張生成)を用いる方が運用上有利です。 例えば、昨日発売された新製品の情報をファインチューニングで教えても、正確に学習することはできません。このような場合は、RAGを使って外部の製品情報データベースを参照させるのが正しいアプローチです。また、モデルが事実に基づかない情報を生成する「ハルシネーション」を、ファインチューニングだけで完全に防ぐことは困難です。あくまでベースモデルが持つ知識の範囲内で、その表現方法を調整する技術であると理解することが重要です。(出典:ファインチューニングとは?RAGとの違いやメリット・デメリット、代表的な手法を解説)


法人向けAI研修
AX CAMP 無料資料
LLMファインチューニングの具体的な手順
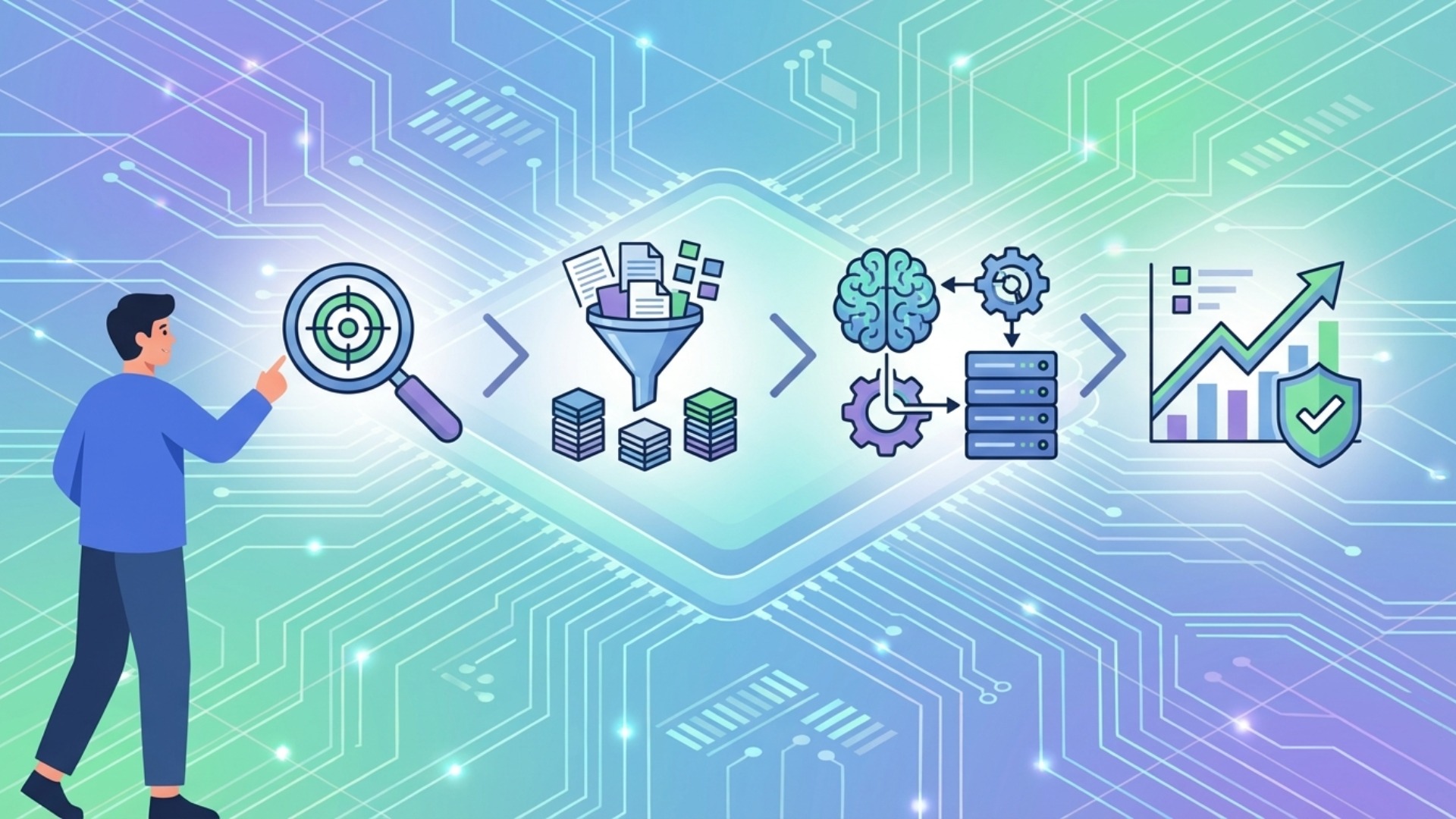
LLMファインチューニングを成功させるためには、計画的かつ体系的なアプローチが求められます。そのプロセスは大きく分けて、目的の明確化、データの準備、モデルの学習、そして性能評価の4つのステップで構成されます。特に、プロジェクトの成否は最初の「目的設定」と「データセットの品質」で8割が決まると言っても過言ではありません。
ここでは、ファインチューニングを実践するための具体的な手順を、ステップごとに解説していきます。
ステップ1・2:目的設定と高品質なデータセットの準備
最初のステップは、ファインチューニングによって「何を達成したいのか」を具体的に定義することです。例えば、「カスタマーサポートの一次回答を自動化する」「特定の文体でブログ記事の草案を生成する」など、目的を明確にすることで、必要なデータの種類や量が決まります。
次に、その目的に沿った高品質なデータセットを準備します。これは「指示(prompt)」と「理想的な出力(completion)」をペアにした形式で用意します。(出典:【ChatGPT】ファインチューニングをわかりやすく解説 #LLM)データ準備の際は、個人情報や機密情報、著作権で保護されたコンテンツの取り扱いに細心の注意を払い、関連法規やガイドラインを遵守する必要があります。
{"prompt": "製品Aの納期について教えてください。", "completion": "お問い合わせありがとうございます。製品Aの納期は通常3営業日いただいております。"}
このデータの品質がモデルの性能に直結するため、誤字脱字がなく、一貫性のある質の高いデータを用意することが最も重要です。
ステップ3・4:トレーニングの実行とモデルの評価
データセットの準備が完了したら、次はいよいよモデルのトレーニングを実行します。OpenAIのAPIや、Google CloudのVertex AI、Amazon SageMakerといったクラウドプラットフォームが提供するサービスを利用するのが一般的です。(出典:Fine-tuning generative AI models for healthcare)これらのサービスを利用する際は、自社のデータがベンダー側で二次利用(モデルの再学習など)されないか、契約や利用規約を事前に必ず確認し、適切なガバナンス体制を構築することが不可欠です。
学習プロセスでは、学習率やエポック数(データセットを繰り返し学習する回数)などの「ハイパーパラメータ」を調整し、最適な性能を目指します。学習が完了した後は、最後のステップとしてモデルの評価を行います。事前に用意しておいたテスト用のデータセットを入力し、期待通りの応答が返ってくるか、精度は十分か、倫理的に問題のある回答をしないかなどを多角的に検証します。この評価結果に基づき、必要であればデータセットやハイパーパラメータを調整し、再度トレーニングを行うサイクルを繰り返します。


LLMのビジネス活用ならAX CAMPのAI研修へ

LLMファインチューニングは自社専用AIを開発する強力な手段ですが、実行には高品質なデータの準備や専門知識、適切なコスト管理が不可欠です。「何から手をつければ良いかわからない」「推進できる人材がいない」といった課題に直面する企業は少なくありません。
AX CAMPでは、貴社の具体的な業務課題をヒアリングし、ファインチューニングやRAGといった技術をどう活用すれば成果に繋がるのか、戦略立案から伴走します。実際に、AX CAMPの支援を通じて多くの企業が成果を上げています。(※各社の実績はAX CAMP導入事例に基づきます)
- グラシズ様:LPライティング外注費10万円→0円、制作時間3営業日→2時間
- Route66様:原稿執筆時間24時間→10秒
- C社様:SNS運用時間3時間→1時間(66%削減)で月間1,000万imp達成
- WISDOM様:AI導入で採用2名分の業務をAIが代替
本記事で解説したような高度な技術を使いこなすには、まず組織全体のAIリテラシー向上が欠かせません。AX CAMPでは、役員層から現場担当者まで、それぞれの階層に必要な知識とスキルを体系的に学ぶことができます。実践的なカリキュラムを通じて、自社でAIプロジェクトを主導できる人材を育成し、PoC(概念実証)で終わらない、本当に業務を変革するAI活用を実現しませんか。
「自社に最適なAIの活用法が知りたい」「失敗のリスクを最小限に抑えたい」とお考えでしたら、まずは無料の資料請求から、どのような支援が可能かご確認ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:LLMファインチューニングで自社専用AIを実現しよう
本記事では、LLMファインチューニングの基本概念からメリット・デメリット、具体的な手順、そしてRAGなどの他手法との違いについて詳しく解説しました。最後に、重要なポイントを改めて振り返ります。
- ファインチューニングはLLMを特定タスクに特化させる追加学習技術である
- メリットは高精度化と業務への最適化、デメリットはコストと専門知識の要求
- 「振る舞い」を変えるのがファインチューニング、「知識」を参照するのがRAG
- 成功の鍵は「目的設定」と「高品質なデータセット」の準備にある
ファインチューニングを正しく理解し活用することで、汎用的なLLMを自社の強力な業務パートナーへと進化させることが可能です。応答品質の安定化やプロンプトの簡略化は、日々の業務効率を大きく改善する可能性を秘めています。
もちろん、こうした専門的な取り組みを自社だけで進めるのは容易ではありません。もし、より実践的な知識の習得や、専門家のサポートを受けながらプロジェクトを推進したいとお考えであれば、AX CAMPがお力になります。貴社の課題に合わせた最適なAI導入プランをご提案し、成果創出に向けて伴走します(※効果は個別の状況により異なります)。AIを活用してビジネスを次のステージへ進めるために、ぜひ一度ご相談ください。

法人向けAI研修
AX CAMP 無料資料