

社内の機密情報をクラウドにアップロードせずにAIを活用したい、あるいは毎月のAPIコストを削減したい。多くの企業が抱えるこのような課題を解決する手段として、ローカル環境で大規模言語モデル(LLM)を学習・運用する方法が注目されています。自社のサーバーやPC上でLLMを動作させることで、セキュリティを最大限に確保し、特定の業務に特化したAIを低コストで構築できる可能性があります。
この記事では、ローカルLLMの基礎知識から、クラウドAPIとの違い、具体的なメリット・デメリット、さらには環境構築の実践的な手順までを網羅的に解説します。おすすめの最新モデルや、学習を効率化するツールも紹介するため、自社に最適な導入方法が見つかるはずです。AI活用の専門家による伴走支援サービス
「AX CAMP」が提供する、導入成功のための実践的なノウハウにご興味のある方は、ぜひ資料をダウンロードしてみてください。

法人向けAI研修
AX CAMP 無料資料
ローカルLLMとは?クラウドとの違いを解説
ローカルLLMとは、自社で管理するコンピューターやサーバー上で直接動作させる大規模言語モデルのことです。OpenAIのGPTシリーズやGoogleのGeminiのように、インターネット経由でサービスを利用するクラウドベースのLLMとは異なり、適切に環境を構築・管理すれば、データを外部サーバーに送信せずにAIを運用できる点が大きな特徴です。
このアプローチにより、外部へのデータ送信リスクを原理的に排除できます。しかし、「完全にオフライン」での運用を実現するには注意が必要です。モデルのダウンロードや依存ライブラリの更新、ライセンス認証などで外部通信が発生しうるため、厳格なネットワーク管理が求められます。情報セキュリティを特に重視する企業にとって、これらの点を理解した上での導入が成功の鍵となります。
ローカル環境でLLMを動かす仕組み
ローカル環境でLLMを動かす基本的な仕組みは、高性能なGPU(Graphics Processing Unit)を搭載したマシンに、LLMのモデルデータを読み込ませて利用するというものです。モデルは数十億から数千億のパラメータを持っており、その膨大な計算処理のために大量のVRAM(ビデオメモリ)を必要とします。
ユーザーがテキストを入力すると、CPUがそのデータをGPUに送り、GPU上でLLMが推論処理を実行して応答を生成します。この一連の流れが自社の管理下にあるマシン内で完結します。ただし、モデルのダウンロードや一部ツールの利用状況データ送信(Telemetry)などで意図せず外部通信が発生するケースもあるため、オフライン運用を徹底するには厳格な運用ポリシーの策定が不可欠です。
クラウドベースLLM(API)との比較
ローカルLLMとクラウドベースLLM(API利用)には、それぞれメリットとデメリットが存在します。どちらが最適かは、企業の目的、予算、技術力によって異なります。両者の主な違いを以下の表にまとめました。
| 比較項目 | ローカルLLM | クラウドベースLLM (API) |
|---|---|---|
| セキュリティ | 高い(適切に構成・管理すれば外部送信リスクを低減) | 提供事業者に依存(通信・保存時の対策が必要) |
| カスタマイズ性 | 非常に高い(ファインチューニングが自由) | 限定的(提供される範囲内) |
| コスト | 初期投資(ハードウェア)が高額、運用コストは変動 | 初期投資は低い、利用量に応じた従量課金 |
| パフォーマンス | ハードウェアの性能に依存 | 常に最新・最高の性能を利用可能 |
| 運用・保守 | 自社で全て対応(専門知識が必要) | 多くのインフラ作業は提供者が代行するが、アクセス制御やコスト監視等は利用者側で必要 |
| 利用環境 | オフラインでも利用可能(※厳格な設定・管理が必要) | オンライン環境が必須 |
結論として、セキュリティやカスタマイズ性を最優先し、専門人材を確保できるならローカルLLMが、手軽に最新性能を試したい場合はクラウドベースLLMが適していると言えるでしょう。
「学習(ファインチューニング)」と「推論」の違い
LLMの文脈で使われる「学習」と「推論」は、異なるプロセスを指します。「学習」とは、既存のLLMモデルに対して、特定のタスクや専門分野のデータを追加で与え、モデルの知識や応答スタイルを調整することです。これをファインチューニングと呼びます。
例えば、自社の問い合わせ履歴を学習させ、顧客対応に特化したチャットボットを作成するようなケースがこれにあたります。一方、「推論」とは、学習済みのモデルを使って、実際にユーザーからの質問に答えたり、文章を生成したりする処理のことです。この「推論」をセキュアに行うこと、そして「学習」によって自社専用モデルを作ることが、ローカル環境を構築する主な目的となります。

LLMをローカル環境で学習させるメリット

LLMをローカル環境で学習・運用することには、クラウドサービスにはない数多くのメリットが存在します。特に、データセキュリティの強化と、コスト管理のしやすさは、多くの企業にとって大きな魅力となるでしょう。ここでは、代表的な4つのメリットを具体的に解説します。
データプライバシーとセキュリティの確保
ローカルLLMの大きな利点は、機密情報や個人情報を外部サーバーに送信することなくAI処理ができる点です。外部サービスへデータが送信されるリスクを原理的に排除できるため、情報漏洩対策として非常に有効と言えます。
ただし、アクセス管理の不備や運用ミスといった内部からの情報漏洩リスクは残ります。そのため、データの暗号化、厳格なアクセス権限の管理(最小権限の原則)、操作ログの監査といった包括的な対策を併用することが不可欠です。これらの対策を講じることで、金融機関の顧客データや製造業の設計図など、機密性の高い情報もより安心して扱えるようになります。
https://media.a-x.inc/llm-security
オフライン環境での利用可能性
インターネット接続が不安定な場所や、セキュリティ上の理由で外部ネットワークから遮断された環境でも、LLMを利用できるのがローカル運用の強みです。例えば、工場内の生産ラインや建設現場など、常時オンライン接続が保証されない場所でもAIシステムを安定して稼働させられます。
これにより、従来はAIの活用が難しかった現場業務の効率化や、リアルタイムでのデータ分析が実現可能となり、新たなビジネスチャンスの創出にも繋がるでしょう。
https://media.a-x.inc/llm-offline
APIコストの削減と利用制限からの解放
クラウドベースのLLMは、APIの利用量に応じて課金される従量課金制が一般的です。大規模なデータ処理や頻繁な利用を行うと、月々のコストが想定以上に膨れ上がる可能性があります。ローカル環境であれば、一度ハードウェアへの初期投資を行えば、利用量に応じたAPI料金は発生しません。
ただし、サーバーの電気代、保守費用、ライセンス更新といった継続的なインフラ運用コスト(TCO)は別途発生するため、総コストでの比較が重要です。また、APIサービスによっては短時間に大量のリクエストを送ると利用が制限される(レートリミット)場合がありますが、ローカル環境ならそのような制限もなく、自社のリソースが許す限り自由にLLMをフル活用できます。
https://media.a-x.inc/llm-api-pricing
特定のタスクに合わせた高度なカスタマイズ
ローカル環境では、オープンソースのLLMをベースに、自社の特定業務に合わせて自由にファインチューニングを行えます。社内文書や過去のメール、専門用語集などを学習させることで、業界特有の知識を持った「自社専用AI」を育成できます。
例えば、法務部門向けの契約書レビュー支援AIや、開発部門向けに社内コード規約を熟知したプログラミングアシスタントなど、汎用的なクラウドLLMでは実現が難しい、業務に深く根ざした高精度なAIを構築できる点が大きなメリットです。その際、個人情報を用いる場合は、利用目的の特定や匿名化、同意取得など社内ルールを整備し、法務・個人情報管理部門との事前確認が不可欠です。

ローカルLLMの学習におけるデメリットと注意点
ローカルLLMの導入は多くのメリットをもたらす一方で、いくつかの無視できないデメリットや注意点も存在します。特に、高性能なハードウェアへの初期投資と、環境構築・運用を担う専門人材の確保が大きなハードルとなります。導入を検討する際は、これらの課題を事前に把握し、対策を講じることが成功の鍵です。
高性能なハードウェア(GPU)の要求
LLMを快適に動作させるためには、非常に高性能なコンピューター、特に強力なGPUが必要です。扱うモデルの規模によりますが、7Bクラスのモデルを快適に動かすには最低でも12GB、本格的な活用を目指すなら24GB以上のVRAMを持つGPUが推奨されます。CPUは8コア以上、メインメモリは32GB以上が目安です。また、数十GBに及ぶモデルデータを保存するため、高速なSSDに100GB以上の空き容量を確保しましょう。(出典:AI導入に必要なものとは?ハードウェア・ソフトウェア・人材の観点から解説)
- 7B(70億)クラス:最低12GB以上のVRAM
- 13B(130億)クラス:16GB~24GBのVRAM
- 70B(700億)クラス以上:48GB以上のVRAMを持つGPUが複数枚必要になる場合も
このように、高性能なGPUは高価であり、導入には多額の初期投資が必要です。また、消費電力や冷却の問題も考慮し、サーバーの設置場所や運用体制も事前に計画しなければなりません。

環境構築と運用の専門知識が必要
ローカルLLMの環境構築は、単純なソフトウェアのインストールとは異なり、高度な専門知識を要します。Pythonの仮想環境管理、ライブラリのバージョン整合性、NVIDIAドライバやCUDAの設定に加え、意図しない外部通信を防ぐためのファイアウォール設定や、利用ツールのTelemetry(利用状況データ送信機能)を無効化するなどのセキュリティ知識も求められます。
また、導入後もモデルのアップデートやセキュリティパッチの適用、ハードウェアのメンテナンスなど、継続的な運用管理が必要です。これらの作業を担える専門知識を持ったエンジニアが社内にいない場合、導入は困難を極めるでしょう。
https://media.a-x.inc/llm-local-build
最新の高性能モデルへの追従の難しさ
AI業界は日進月歩で、数ヶ月単位で新しい、より高性能なモデルが登場します。クラウドサービスであれば、事業者が常に最新モデルを提供してくれるため、ユーザーはいつでも最高の性能を利用できます。
しかし、ローカル環境の場合、新しいモデルを利用するには、その都度自社でダウンロード、設定、そして場合によっては再学習を行う必要があります。この継続的なアップデート作業は大きな負担となり、リソースが限られている企業にとっては、最新技術への追従が難しくなる可能性があります。

【2026年最新】ローカル学習におすすめのLLMモデル5選

ローカル環境で利用できるオープンソースLLMは数多く存在し、それぞれに特徴があります。ライセンス、性能、日本語への対応度などを考慮し、自社の目的に合ったモデルを選ぶことが重要です。ここでは、2025年11月時点で特に評価が高く、多くの開発者に利用されている代表的な5つのモデルを紹介します。
1. Llama 3 (Meta)
Meta社が開発した「Llama 3」は、オープンウェイトLLMの中でも特に高い性能を誇り、多くのプロジェクトでベースモデルとして採用されています。公式に公開されているサイズは8B(80億)や70B(700億)です。汎用性が非常に高く、多くのタスクで安定した性能を発揮するため、ローカルLLM導入の第一候補となるモデルです。利用にあたっては、公式のライセンスと利用規約を確認する必要があります。(出典:Meta、大規模言語モデル「Llama 3」を公開 ~オープンなモデルで業界最高水準の性能)
2. Gemma ファミリ (Google)
Googleが開発した「Gemma」は、同社の高性能モデル「Gemini」シリーズと同じ技術を基に作られたオープンソースモデルです。比較的小さなサイズでも高い性能を発揮するよう設計されており、比較的スペックの低いマシンでも動作させやすい点が特徴です。商用利用も可能なライセンスで提供されており、ビジネス用途でも安心して利用できます。(出典:Google、オープンな大規模言語モデル「Gemma」。Geminiベースで開発)
3. Phi-3 (Microsoft)
Microsoftが開発した「Phi-3」は、「小さいのに賢い」をコンセプトにした軽量なモデル群です。特に「Phi-3-mini」は3.8B(38億)という非常に小さいパラメータサイズながら、大規模なモデルに匹敵する性能を持つとされています。スマートフォンなどのエッジデバイスでの動作も視野に入れて開発されており、リソースが限られた環境での利用に最適です。ライセンスはMIT Licenseで提供されており、商用利用も可能です。
4. Command R+ (Cohere)
Cohere社が開発した「Command R+」は、特にRAG(検索拡張生成)や業務ツールとの連携といった、実用的なビジネス応用を強く意識したモデルです。104B(1040億)パラメータを持つエンタープライズ向けモデルとして知られており、多言語対応にも優れています。信頼性の高い情報源を引用しながら回答を生成する能力に長けており、企業のシステム構築に適しています。研究や評価目的では利用できますが、商用利用にはCohereとの契約が必要です。
5. Mistral ファミリ (Mistral AI)
フランスのスタートアップMistral AIは、複数の高性能モデルを提供しています。フラッグシップモデルの「Mistral Large」は、一部の性能ベンチマークにおいてGPTシリーズの高性能モデルに匹敵すると評価されていますが、商用利用にはAPI経由での利用が基本となります。一方で、「Mistral 7B」や「Mixtral 8x7B」はApache 2.0ライセンスで公開されており、商用利用も可能なためローカル環境で広く利用されています。(出典:Open-weight models)
https://media.a-x.inc/llm-open-source
日本語の学習に強いローカルLLMモデル
一般的なオープンソースLLMは主に英語データで学習されているため、日本語特有のニュアンスや文脈の理解が不十分な場合があります。幸いなことに、日本の企業や研究機関によって、日本語能力を強化した高性能なローカルLLMが開発・公開されています。国内でのビジネス利用においては、これらの日本語特化モデルを選択することが成功への近道です。(2025年11月時点)
Swallow (TokyoTech)
東京工業大学の研究チームが開発したモデル群で、「Llama」シリーズをベースに日本語能力を強化しています。複数のサイズが公開されており、オープンソースの日本語LLMとして最高レベルの性能を誇ります。Apache 2.0ライセンスで公開されており、商用利用も可能です。学術的な正確さや論理的な応答が求められるタスクで高い評価を得ています。
Llama-3-ELYZA-JP (ELYZA)
株式会社ELYZAが、Metaの「Llama 3」をベースに、独自の高品質な日本語データを用いて追加学習を行ったモデルです。元のモデルが持つ高い汎用性能を維持しつつ、日本語の指示に対する理解力や、自然で流暢な応答生成能力が大幅に向上しています。Llama 3 Community License Agreementに準拠しており、条件付きで商用利用が可能です。
Japanese StableLM 2 (Stability AI)
画像生成AI「Stable Diffusion」で知られるStability AI Japanが開発した、日本語に特化した言語モデルです。1.6Bと12Bの2サイズが公開されており、特に12Bモデルは同規模のモデルの中でトップクラスの日本語性能を持つとされています。Stability AIの定めるライセンス(STABILITY AI JAPANESE DEEP LEARNING MODEL LICENSE)に基づき、商用利用が可能です。
https://media.a-x.inc/llm-japan
ローカルLLMの学習環境を構築する実践手順
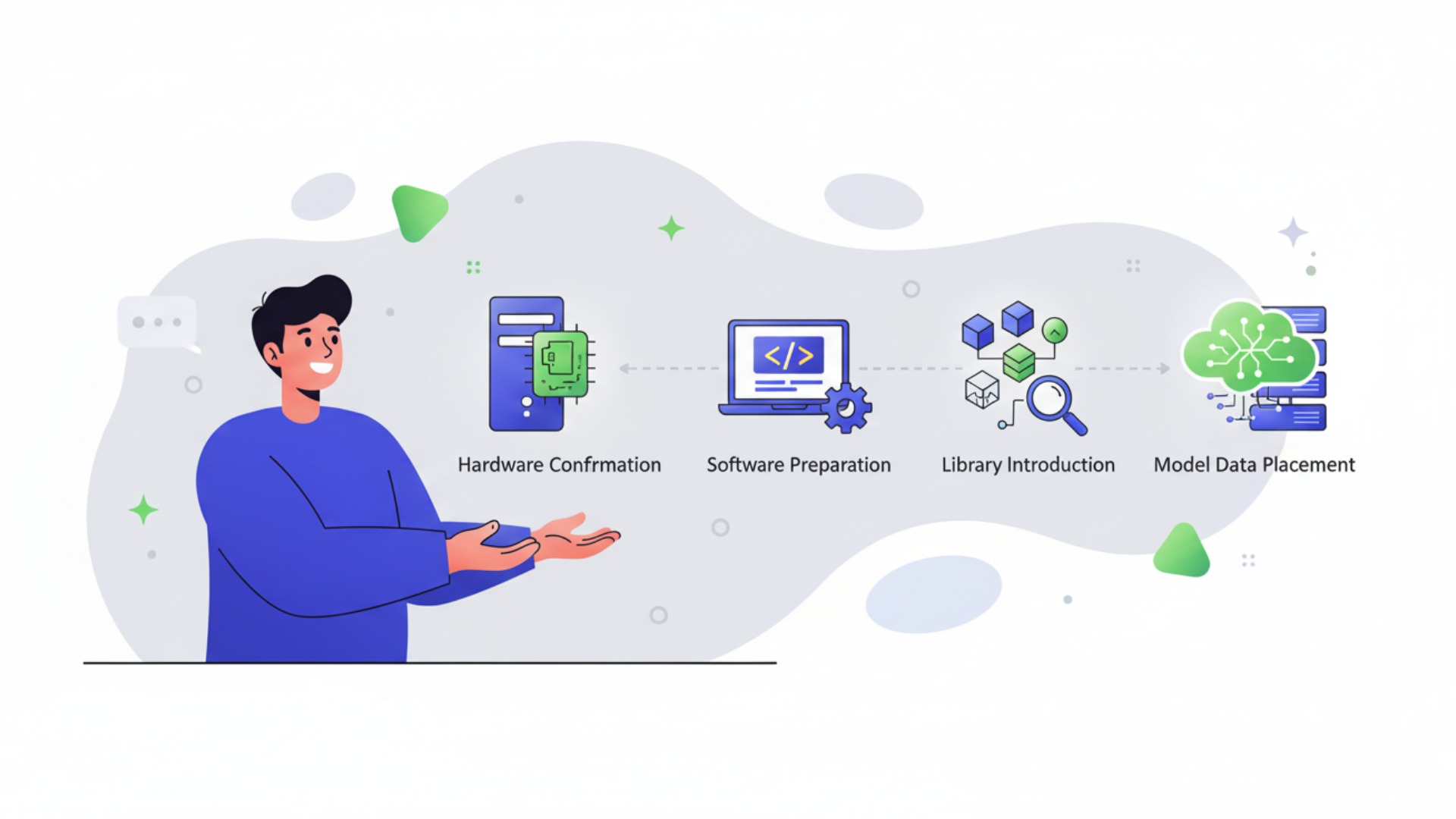
ローカルLLMの環境構築は、正しい手順を踏めば決して不可能ではありません。全体の流れは、ハードウェアの確認、ソフトウェアの準備、ライブラリの導入、そしてモデルデータの配置という4つのステップに分けられます。ここでは、それぞれのステップで具体的に何を行うべきかを解説します。
ステップ1:必要なハードウェアスペックの確認
まず、LLMを動作させるマシンのスペックを確認します。最も重要なのはGPUとそのVRAM容量です。前述の通り、7Bクラスのモデルなら最低12GB、より大規模なモデルを扱うなら24GB以上のVRAMが推奨されます。CPUは比較的重要性は低いですが、8コア以上あると快適です。メインメモリは32GB以上、モデルデータを保存するために高速なSSDに100GB以上の空き容量があると良いでしょう。
ステップ2:Pythonと仮想環境の準備
次に、プログラミング言語であるPythonをインストールします。LLM関連のライブラリはPythonで開発されているものがほとんどです。この際、プロジェクトごとにライブラリのバージョンを管理するために、「仮想環境」を作成することが強く推奨されます。`venv`や`conda`といったツールを使い、クリーンな専用環境を用意することで、ライブラリ同士の競合といったトラブルを避けられます。
ステップ3:主要ライブラリのインストール
仮想環境を有効化したら、LLMの実行に必要なライブラリをインストールします。代表的なものには、NVIDIA製GPUを利用するための`PyTorch`、様々なモデルを簡単に扱えるようにするHugging Faceの`transformers`、モデルの読み込みを効率化する`accelerate`、メモリ使用量を削減する`bitsandbytes`などがあります。(出典:Installation)
これらのライブラリは`pip`コマンドでインストールしますが、お使いのNVIDIAドライバとCUDAのバージョンに適合したものを選択する必要があります。特に`bitsandbytes`などは環境依存の問題が発生しやすいため、仮想環境の利用は必須です。ビルドに失敗する場合は、condaを利用したり、事前ビルド済みのwheelファイルを探したりといった対応が求められます。
ステップ4:モデルデータのダウンロードと配置
最後に、利用したいLLMのモデルデータをダウンロードします。多くのオープンソースモデルは、AIモデルの共有プラットフォームである「Hugging Face」で公開されています。ここから目的のモデルを探し、Git LFS(Large File Storage)などのツールを使ってローカルマシンにダウンロードします。ダウンロードしたモデルデータを、作成したプログラムから読み込めるように指定のディレクトリに配置すれば、準備は完了です。
https://media.a-x.inc/llm-local-build
ローカルLLMの学習を効率化する主要フレームワーク・ツール

コマンドライン操作や複雑な環境構築は、ローカルLLM導入のハードルを高くする一因です。しかし、近年ではこれらのプロセスを大幅に簡略化し、誰でも手軽にローカルLLMを試せる便利なツールが数多く登場しています。ここでは、特に人気が高く、初心者から上級者まで幅広く利用されている3つのツールを紹介します。
Ollama:手軽にモデルを試せる実行環境
Ollamaは、たった一つのコマンドで様々なLLMをダウンロードし、すぐにチャット形式で試すことができるツールです。複雑な環境構築を一切必要とせず、macOS, Windows, Linuxに対応しています。「とりあえずローカルLLMを動かしてみたい」という初心者にとって最適な選択肢であり、APIサーバーを立てる機能もあるため、開発の初期段階で利用するのにも便利です。
Llama.cpp:CPUでも高速推論を実現
Llama.cppは、LLMの推論処理をGPUだけでなくCPUでも高速に実行することを目指したプロジェクトです。C++で書かれており、モデルを「量子化」という技術で軽量化することで、高性能なGPUがないマシンでも実用的な速度でLLMを動作させることが可能になります。MacBookのような一般的なノートPCでもLLMを動かせるため、多くのユーザーに支持されています。
LM Studio:GUIで直感的に操作可能
LM Studioは、グラフィカルなインターフェース(GUI)を通じて、直感的にローカルLLMを管理・実行できるデスクトップアプリケーションです。モデルの検索・ダウンロードから、チャット形式での対話、各種パラメータの調整まで、すべての操作をマウスで行えます。プログラミングの知識がなくても扱えるため、非エンジニアでも手軽にローカルLLMの性能を試すことができます。
https://media.a-x.inc/llm-tools
実践的なAIスキルを習得するならAX CAMP

ローカルLLMの導入は、セキュリティの確保やコスト削減に大きなメリットをもたらしますが、その一方で環境構築やモデルの選定、ファインチューニングには高度な専門知識が求められます。自社に専門家がいない、あるいは何から手をつければ良いか分からない、といった課題に直面する企業は少なくありません。
そのような課題を解決するのが、当社が提供する実践型の法人向けAI研修・伴走支援サービス「AX CAMP」です。AX CAMPでは、非エンジニアの方でもAIを活用して業務を自動化できるスキルを、実務直結のカリキュラムを通じて体系的に学ぶことができます。
単なる知識の提供に留まらず、経験豊富なプロのコンサルタントがお客様の業務課題をヒアリングし、最適なAI活用方法の選定から実装、そして社内への定着までを徹底的にサポートします。自社だけでAI導入を進めるのが難しいと感じているなら、まずは無料の資料請求や相談会で、どのような支援が可能かをご確認ください。

法人向けAI研修
AX CAMP 無料資料
まとめ:ローカルLLMの学習で自社専用AI活用を始めよう
この記事では、ローカル環境でLLMを学習・運用する方法について、その基礎からメリット・デメリット、具体的な構築手順、そして実際のビジネス事例までを解説しました。改めて、本記事の重要なポイントをまとめます。
- ローカルLLMは適切に構成・管理すればセキュリティとカスタマイズ性に優れる
- APIコストを気にせずAIを無制限に利用できるが、インフラコストは発生する
- 導入には高性能なハードウェアと専門知識、厳格な運用ポリシーが必要
- Ollamaなどのツールを使えば環境構築を簡略化できる
- 自社データで学習させれば業務特化の専用AIが作れる
ローカルLLMを使いこなすことは、データを外部に出すことなく、自社のニーズに完全に合致したAIを構築するための強力な手段です。セキュリティを最優先しながらDXを推進したい企業にとって、これは大きな競争優位性につながります。
しかし、その実現には技術的なハードルが伴います。「AX CAMP」では、専門家による伴走支援を通じて、ローカルLLMの導入を含む貴社のAI活用プロジェクトを成功へと導きます。AIの内製化や、より高度なAI活用に関心のある方は、ぜひ一度、お気軽にご相談ください。

法人向けAI研修
AX CAMP 無料資料