

「生成AIはなぜ人間の言葉を理解できるんだろう」
「社内の膨大な資料から、AIが的確な答えを見つけ出す仕組みを知りたい」
と感じていませんか。その鍵を握るのが「ベクトル化(エンベディング)」という技術です。これは、テキストや画像といったデータを、AIが処理できる数値の羅列(ベクトル)に変換する仕組みを指します。
この記事では、生成AIの中核技術であるベクトル化の基本的な仕組みから、代表的な手法、そしてビジネスにおける具体的な活用事例までを分かりやすく解説します。この記事を読めば、AIがデータを
「理解する」とはどういうことか、そして自社のデータ活用をどう加速させられるかのヒントが得られるはずです。AI導入の具体的な進め方や業務効率化の事例をまとめた資料もご用意していますので、ぜひご活用ください。

法人向けAI研修
AX CAMP 無料資料
生成AIにおけるベクトル化(エンベディング)とは?
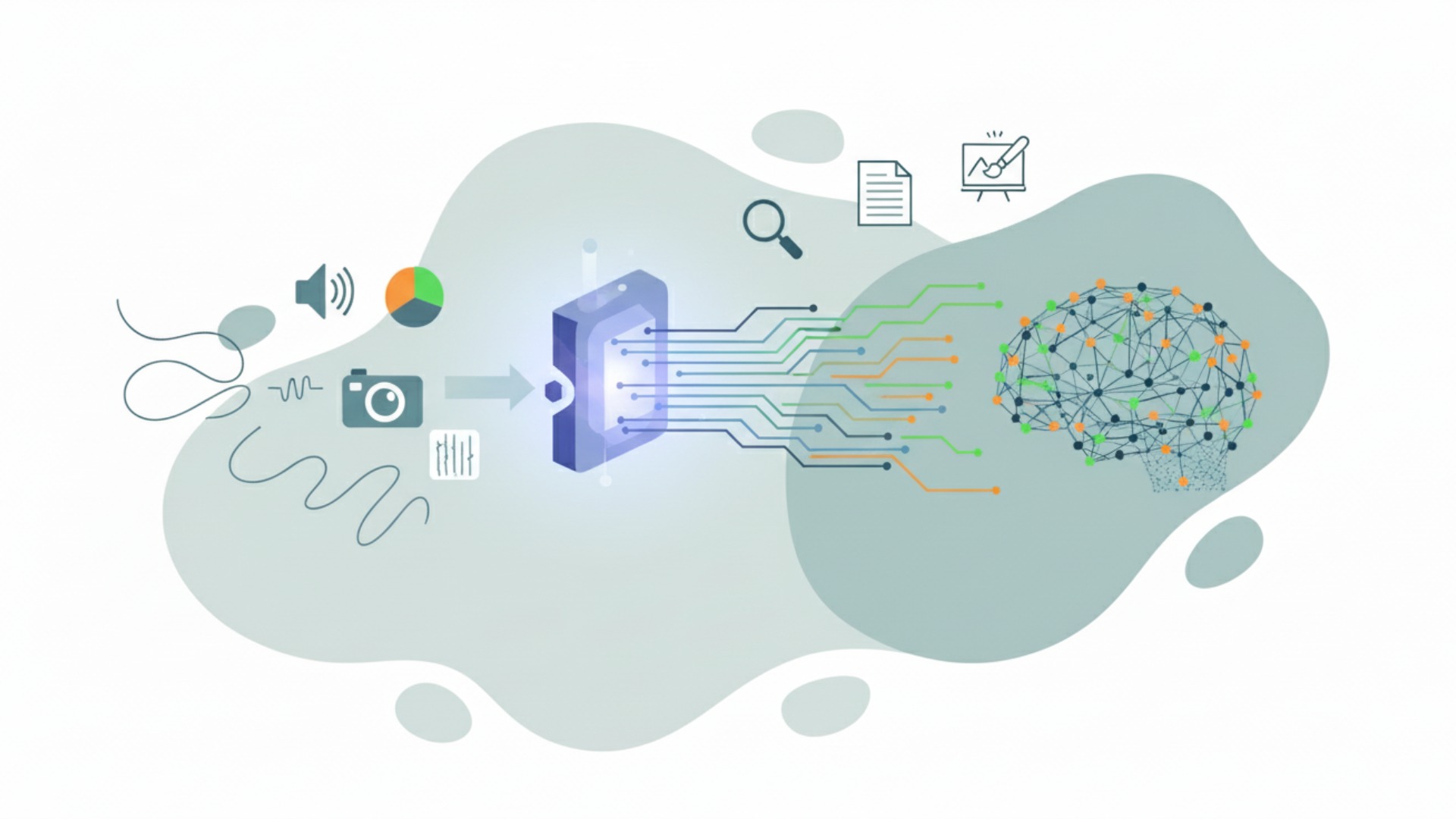
結論として、生成AIにおけるベクトル化(エンベディング)とは、人間が使う言葉や画像などのデータを、AIが理解できる数値のベクトルに変換する技術です。コンピュータは「AI」や「活用」といった単語をそのままでは処理できないため、一度、数値の集合に置き換える必要があります。このプロセスが、AIがデータを取り扱う上でのすべての始まりと言えます。
ベクトル化は、単なる数値への置き換えではありません。単語や文章が持つ「意味」を、多次元空間上の座標として表現することが可能です。これにより、AIはデータの内容を数学的に捉え、様々なタスクに応用できるようになるのです。
AIがテキストや画像を数値で理解する仕組み
AIがテキストや画像を理解する際、まずデータを細かい単位に分解します。テキストであれば単語や文字(トークン)に、画像であればピクセルの集合体として認識します。次に、エンベディングモデルと呼ばれる専用のAIが、これらの分解されたデータ一つひとつを、数百から数千次元のベクトル(数値の配列)に変換します。
例えば、「猫」という単語は [0.12, -0.45, 0.89, …] といった数値の羅列に、「犬」は [0.15, -0.48, 0.91, …] という似た数値の羅列に変換されます。この数値の羅列こそが、AIにとっての「猫」や「犬」の定義であり、このベクトルを用いて様々な処理を行います。
ベクトル空間における「意味の近さ」の表現
ベクトル化の最も重要な特徴は、意味が近い単語や文章ほど、ベクトル空間上で「近く」に配置される点にあります。先ほどの「猫」と「犬」のベクトルは互いに近い位置にプロットされる一方で、「自動車」のベクトルは全く異なる離れた位置にプロットされます。
この性質を利用することで、AIは単語間の関係性を計算で導き出せます。有名な例として「王様」のベクトルから「男性」のベクトルを引き、「女性」のベクトルを足すと、「女王様」のベクトルに非常に近くなる、というものがあります。このように、ベクトル空間上の距離や方向が、現実世界における意味の類似性や関係性を表しているのです。


なぜ生成AIにベクトル化が不可欠なのか?
ベクトル化は、Webサイトの文章や社内文書のような「非構造化データ」をAIが扱える形式に整え、検索精度などを飛躍的に高めるために不可欠なプロセスです。現代のビジネスデータの大部分は、このような整理されていない非構造化データであり、これを有効活用することが企業の競争力を左右します。
もしベクトル化がなければ、AIはテキストデータの内容を理解できず、単なる文字列としてしか扱えません。これでは、キーワードが完全に一致しない限り情報を探し出すことができず、AIの能力を最大限に引き出すことは困難でしょう。(出典:Snowflake Cortex Functions)
非構造化データをAIが処理可能な形式に変換する役割
ビジネスの世界には、メールの文面、会議の議事録、顧客からの問い合わせ履歴、設計図、画像ファイルなど、形式の定まっていない「非構造化データ」が溢れています。これらは企業にとって価値ある情報資産ですが、そのままではデータベースでの検索や分析が困難でした。
ベクトル化は、こうした多種多様な非構造化データを、統一された「ベクトル」という形式に変換する「翻訳機」のような役割を担います。テキストも画像も音声も、すべてベクトルに変換することで、AIはそれらを横断的に比較・分析し、新たな知見を見つけ出すことが可能になります。
類似度検索や情報推薦の精度を飛躍的に向上
ベクトル化によって、従来のキーワード検索の限界を超える「類似度検索(セマンティック検索)」が実現します。これは、単語の文字列が一致するかどうかではなく、意味の近さに応じて情報を探し出す検索方法です。
例えば、社内規定データベースで「在宅勤務のルール」と検索した際に、キーワードが完全一致しなくても「リモートワークの服務規程」や「テレワークに関するガイドライン」といった意味的に関連性の高い文書をAIが提示してくれます。これにより、ユーザーは求める情報に迅速かつ正確にたどり着けるようになり、業務効率が大幅に向上するのです。

法人向けAI研修
AX CAMP 無料資料
ベクトル化の基本的な仕組みと3つのプロセス
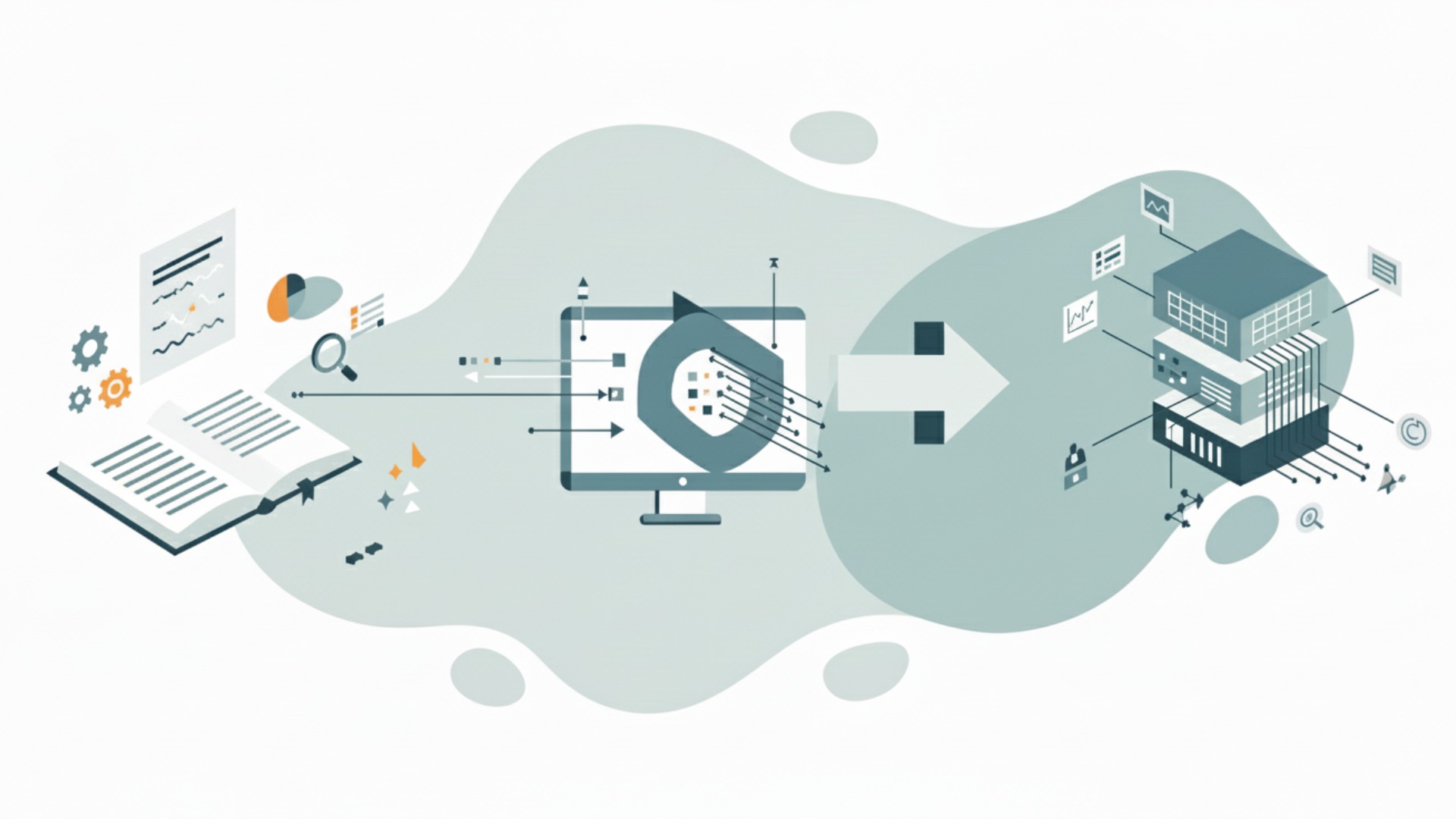
ベクトル化は、魔法のように一瞬で完了するわけではありません。一般的には、「テキストの前処理」「埋め込みモデルによるベクトルへの変換」「ベクトルデータベースでの管理・活用」という3つのステップを経て実行されます。これらのプロセスを順に経ることで、元データが持つ意味を保持したまま、AIが扱いやすい形式へと変換されるのです。
この一連の流れを理解することは、自社でベクトル化技術を応用する際のシステム設計やトラブルシューティングに役立ちます。それぞれのステップがどのような役割を果たしているのかを見ていきましょう。
Step1: テキストの前処理(トークン化・クリーニング)
最初のステップは、元となるテキストデータをAIが処理しやすいように整える「前処理」です。まず「トークン化」によって、文章を単語や文字などの最小単位(トークン)に分割します。例えば、「生成AIの活用事例」という文章は、「生成」「AI」「の」「活用」「事例」といったトークンに分けられます。
次に「クリーニング」処理を行いますが、最新のAIモデルでは注意が必要です。かつては助詞などの「ストップワード」除去や、単語の原型に戻す「レンマ化」が一般的でした。しかし、BERTのようなTransformerベースのモデルでは、これらの処理が文脈や否定表現の理解を妨げる可能性があります。そのため、まずは正規化(全角半角統一など)とトークン化のみを行い、必要に応じて下流タスクの評価で前処理を追加・比較検討するのが現在の主流です。
Step2: 埋め込みモデルによるベクトルへの変換
次に、前処理されたトークンを「埋め込みモデル(Embedding Model)」に入力し、ベクトルへと変換します。埋め込みモデルは、膨大なテキストデータを事前に学習しており、各トークンがどのような文脈で使われるかを理解しています。
このモデルが、各トークンに対して数百から数千次元のベクトルを割り当てます。このとき、単に単語を変換するだけでなく、その単語が置かれている文脈全体を考慮してベクトルを生成するのが近年のモデルの特長です。これにより、「実行」という同じ単語でも、「計画を実行する」と「プログラムを実行する」では異なるニュアンスを持つベクトルが生成され、より精度の高い意味表現ができます。
Step3: ベクトルデータベースでの管理・活用
最後のステップは、生成された大量のベクトルを効率的に管理し、活用するための「ベクトルデータベース」への格納です。ベクトルデータベースは、高次元のベクトルデータを高速に検索することに特化したデータベースです。(出典:What is a Vector Database?)
ユーザーから検索クエリが入力されると、そのクエリも同様にベクトル化されます。そして、ベクトルデータベースは、保存されている膨大なベクトルの中から、クエリのベクトルと類似度の高いベクトルを探し出します。この際、多くはANN(近似最近傍探索)という技術を使い、完全な一致ではなくとも極めて近い結果を高速に返すことで、精度と速度のバランスを取っています。この仕組みにより、セマンティック検索やRAG(検索拡張生成)などの高度なAIアプリケーションが実現されています。
https://media.a-x.inc/ai-development
【手法別】テキストベクトル化の代表的なモデル

テキストをベクトル化する手法は、時代とともに進化を続けており、古典的な統計ベースの手法から、最新のTransformerアーキテクチャを基盤とするモデルまで多岐にわたります。それぞれに得意なことや限界があり、用途に応じて適切なモデルを選択することが重要です。技術の変遷を理解することで、各モデルの特性をより深く把握できるでしょう。
ここでは、ベクトル化技術の発展に大きく貢献した代表的なモデル群を、2つのカテゴリーに分けて紹介します。それぞれのアプローチの違いを見ていきましょう。
古典的手法と分散表現 (Word2Vecなど)
2010年代前半に登場したWord2Vecは、ベクトル化技術を大きく前進させました。この手法は「分散表現」という考え方に基づいています。これは、「ある単語の意味は、その周辺に出現する単語によって形成される」というものです。
Word2Vecは、大量のテキストデータから単語の共起関係(どの単語がどの単語の近くで使われやすいか)を学習し、各単語をベクトル空間上に配置します。この手法は比較的軽量で高速に動作する利点がありますが、文脈によって意味が変わる多義語の扱いや、文章全体の意味を捉えるのが苦手という課題がありました。
最新のTransformerベースモデル (BERTなど)
2018年頃に登場したBERT(Bidirectional Encoder Representations from Transformers)は、ベクトル化の精度を劇的に向上させました。BERTはTransformerという深層学習モデルをベースにしており、文章全体を双方向から読み解くことで、文脈に応じた単語の意味を正確に捉えることができます。(出典:Transformers Documentation)
例えば、「銀行の窓口に行く」と「川の土手を歩く」という文があった場合、BERTは前後の文脈を深く理解するため、同じ「bank」という単語でも全く異なるベクトルを生成します。現在主流となっているGPTシリーズなどの大規模言語モデルも、このTransformerの技術を発展させたものであり、非常に高精度なベクトル化を実現しています。

法人向けAI研修
AX CAMP 無料資料
ベクトル化技術の主な活用事例

ベクトル化技術は、単なる学術的な概念にとどまらず、AIの回答精度を高めるRAGや、より人間的な検索体験を実現するセマンティック検索など、多くの実用的なアプリケーションで広く活用されています。これらの技術は、ビジネスにおける情報検索のあり方を根本から変える可能性を秘めています。
ここでは、ベクトル化がどのようにビジネス課題の解決に貢献しているのか、具体的な活用事例を2つ紹介します。また、これらの技術がもたらす業務効率化のインパクトについても触れていきます。
RAG(検索拡張生成)によるハルシネーション対策
RAG(Retrieval-Augmented Generation)は、生成AIが事実に基づかない情報(ハルシネーション)を生成するのを防ぐための有力な技術です。ユーザーから質問が入力されると、まずその質問内容をベクトル化し、社内文書やマニュアルなどの信頼できる情報源が格納されたベクトルデータベースを検索します。
そして、質問に関連性の高い文書を見つけ出し、その内容を参考情報として生成AIに渡します。AIは、この正確な情報源に基づいて回答を生成するため、ハルシネーションを大幅に抑制できます。これにより、顧客対応チャットボットや社内情報検索システムなど、正確性が求められる場面でも安心して生成AIを活用できるのです。
セマンティック検索とマルチモーダル(画像・音声)応用
セマンティック検索(意味検索)は、ベクトル化の最も代表的な応用例です。ECサイトで「夏向けの涼しいトップス」といった曖昧な表現で検索しても、AIがその意図を汲み取り、「半袖」「リネン素材」「通気性」といった関連キーワードを持つ商品を推薦してくれます。
さらに、この技術はテキストに限りません。画像や音声もベクトル化することで「マルチモーダル検索」が可能になります。例えば、スマートフォンのカメラで撮影した洋服の画像を使って、ECサイト上で類似の商品を検索するといった使い方が実現します。これにより、ユーザー体験はより直感的で便利なものへと進化します。
こうしたベクトル化技術をビジネスに実装することで、具体的な業務効率化が実現可能です。実際に、AX CAMPの研修を通じてAI活用を推進した企業では、目覚ましい成果が生まれています。以下に代表的な例を挙げます。(出典:【2024年最新】生成AIの法人向け活用事例30選!業務効率化・コスト削減の成功例を解説)
- 問い合わせ対応の高速化:過去の膨大な問い合わせ履歴をベクトル化して検索可能にすることで、類似の質問を即座に発見。担当者が回答作成にかける時間を大幅に削減する活用が期待できます。
- コンテンツ制作の効率化:関連情報の収集・整理にAIを活用し、これまで数日かかっていたLP(ランディングページ)制作を数時間に短縮。外注コストの削減と内製化を実現したという声も聞かれます。(参考値)
- 採用業務の精度向上:候補者の職務経歴と募集要項をベクトル化してマッチング精度を高め、書類選考における一部業務の負荷を軽減。これにより、採用担当者がより戦略的な業務に集中できる環境づくりに貢献します。(参考値)


ベクトル化を実践するための主要ツール・ライブラリ

ベクトル化の仕組みをゼロから構築するのは非常に困難ですが、現在では専門的なライブラリやクラウドサービスを利用することで、比較的容易に実装することが可能です。これらのツールをうまく活用することで、開発者は複雑なアルゴリズムに悩むことなく、アプリケーションのコアな価値創造に集中できます。
ここでは、ベクトル化を実践する上で役立つ代表的なツールやサービスを、「プログラミングライブラリ」「埋め込みモデルAPI」「ベクトルデータベース」の3つのカテゴリに分けて紹介します。
| カテゴリ | 代表的なツール・サービス | 主な特徴 |
|---|---|---|
| プログラミングライブラリ | Hugging Face Transformers, Sentence-Transformers | Python環境で動作。最新の埋め込みモデルを数行のコードで利用可能。研究から本番環境まで幅広く使われる。(出典:Transformers Documentation) |
| 埋め込みモデルAPI | OpenAI API, Google Vertex AI, Snowflake Cortex | 自前でモデルを管理する必要がなく、APIリクエストを送るだけで高精度なベクトルを取得可能。スケーラビリティに優れる。(出典:Snowflake Cortex Functions) |
| ベクトルデータベース | Pinecone, Weaviate, Chroma, Qdrant | ベクトルの保存、管理、高速な類似度検索に特化。クラウドサービス型やオープンソース型など様々な選択肢がある。(出典:What is a Vector Database?) |
これらのツールを組み合わせることで、RAGシステムやセマンティック検索アプリケーションを効率的に開発できます。例えば、Pythonの`Sentence-Transformers`でテキストをベクトル化し、その結果をクラウドの`Pinecone`に保存して管理する、といった構成が一般的です。
法人向けAI研修
AX CAMP 無料資料
ベクトル化の課題と2025年以降の展望
ベクトル化は非常に強力な技術ですが、計算コストや最適なモデル選定の難しさといった実用上の課題も存在します。一方で、技術の進化は著しく、これらの課題を克服するための研究開発が世界中で進められています。今後は、より効率的で、多様なデータに対応可能な技術へと発展していくことが予測されます。
ここでは、現在ベクトル化技術が直面している主な課題と、それらが将来どのように解決されていくかの展望について解説します。
現在の主な課題としては、以下の3点が挙げられます。
- 計算コスト: 高精度なモデルを用いて大量のデータをベクトル化するには、高性能なGPUなどの計算リソースが必要となり、時間とコストがかかります。
- 専門知識の必要性: 用途に最適な埋め込みモデルを選定したり、パラメータを調整したりするには、AIや自然言語処理に関する専門的な知識が求められます。
- 意味の多様性の表現: 同じ単語でも文脈によって全く異なる意味を持つ場合(多義性)や、皮肉のような複雑なニュアンスをベクトルで完全に表現するのは依然として難しい課題です。
これらの課題に対し、2025年以降は以下のような方向性で技術が進化していくと考えられます。
- モデルの効率化と進化: より少ない計算リソースで高精度なベクトルを生成できる、軽量かつ高性能なモデルが登場し、コストの問題が緩和されるでしょう。
- マルチモーダル化の標準化: テキスト、画像、音声、動画といった異なる種類のデータを、統一された一つのベクトル空間でシームレスに扱える技術が一般化し、より高度な分析や検索が可能になります。
- 自動化とMaaS化の進展: ベクトル化に関連する一連のプロセス(データ前処理、モデル選定、ベクトルDB管理など)を自動化したり、それらをパッケージとして提供するMaaS(Model as a Service)が普及し、専門家でなくても容易に活用できるようになります。

生成AIのベクトル化をビジネスに活かすならAX CAMP

ベクトル化の仕組みや可能性を理解しても、「では、具体的に自社のどの業務に、どのように応用すれば成果が出るのか?」という問いに答えるのは簡単ではありません。技術の概念をビジネスの成果に結びつけるには、自社の課題を深く理解し、適切な技術を選定し、そして現場が使いこなせる形で実装するノウハウが不可欠です。
AX CAMPは、こうした課題を解決するために設計された実践型の法人向けAI研修・伴走支援サービスです。単にAIの知識を学ぶだけでなく、「自社で成果を出す」ことに徹底的にこだわっています。
AX CAMPが提供する価値は、主に以下の3点です。
- 職種別の実践的カリキュラム: エンジニア向けにはRAGシステムのハンズオン構築を、企画職向けには業務課題の洗い出しとAI活用企画の立案を、といったように、明日から実務で使えるスキルが身につくカリキュラムを提供します。
- 専門家による伴走支援: 研修で学んだ内容を自社で実践する際に、専門コンサルタントが壁打ち相手となり、技術選定から導入計画までを具体的にサポート。計画倒れに終わらせません。
- 豊富な成功事例に基づくノウハウ: 様々な業界のAI導入を支援してきた実績から得られた知見を基に、貴社の状況に最も適したAI活用のロードマップを共に描きます。
「社内に眠るデータをビジネスに活かしたい」「AIを使って競合との差別化を図りたい」とお考えでしたら、まずは一度、弊社の無料相談をご活用ください。貴社の課題や目標をヒアリングさせていただき、AI活用で何が実現できるのか、具体的な道筋をご提案します。

法人向けAI研修
AX CAMP 無料資料
まとめ:生成AI ベクトル化を理解してデータ活用を加速させよう
本記事では、生成AIの中核技術である「ベクトル化(エンベディング)」について、その仕組みから活用事例、将来の展望までを解説しました。AIがどのようにして言葉や画像を「理解」しているのか、その根幹をご理解いただけたのではないでしょうか。
この記事の要点を以下にまとめます。
- ベクトル化は、テキストや画像などの非構造化データをAIが扱える数値ベクトルに変換する「翻訳」技術である。
- 単語や文章の意味の近さをベクトル空間上の距離で表現し、高精度な類似度検索を可能にする。
- RAG(検索拡張生成)やセマンティック検索など、ビジネス課題を解決する多くのアプリケーションで活用されている。
- 実装には専門的なツールやライブラリが多数存在し、これらを活用することで開発を効率化できる。
ベクトル化を理解し、使いこなすことは、社内に蓄積された膨大な情報資産を価値に変え、データドリブンな意思決定を加速させるための鍵となります。しかし、これらの技術を自社だけで導入し、成果を出すまでには多くのハードルが存在するのも事実です。
もし、この記事で解説したようなベクトル化技術を自社のビジネスに本格的に導入し、具体的な業務効率化や新たな価値創造を実現したいとお考えなら、専門家の支援を受けるのが最も確実な近道です。AX CAMPでは、貴社の課題に合わせた最適なAI導入プランの策定から、現場でAIを使いこなす人材の育成までを一気通貫でサポートします。まずは無料の資料請求やオンライン相談で、どのような可能性があるのかをご確認ください。

法人向けAI研修
AX CAMP 無料資料